(WebFlux)002、如何打印日志与链路ID
一、背景
最近在持续改造项目,想通过日志查看用户所有的接口链路日志。在原来基于SpirngMVC的时候,那是比较好处理的,通过ThreadLocal,放入TraceId,就可以把一个TraceId传到各个地方,然后再需要的地方取出来,相当简单。但是在换了WebFlux,老实说,真还是有些麻烦。但这并不能难倒我们,发车!
现在把使用过程中问题和解决方式列出来,供大家参考。参考原文链接
SpringBoot 版本号: 2.6.10
二、 正文
2.1 实现方案
要实现用户调用链路所有的日志,那么我们就得通过唯一的ID去追踪。大致可以通过在请求的header中携带token,或者通过cookie这样的方式。考虑到大多数的使用场景,我们就使用在header中携带token的方式来实现。
2.2 实现方式
既然我们采取的是在header在添加token的方式,那么如何取出来,然后又在打印日志中获取到,这才是关键点。我们在SpringMVC中通常采用AOP的方式打印日志,那我们在WebFlux中是否也可以这样做呢?
2.2.1 步骤1 - 过滤器
当然可以了。要实现拦截,当然还是先实现WebFilter,代码如下。
/**
* <p>记录traceId</p>
*
* @author fattycal@qq.com
* @since 2022/8/8
*/
@Slf4j
@Configuration
public class TraceIdWebFilter implements WebFilter {
private static final String TRACE_ID = ConstantsFields.TRACE_ID;
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return chain.filter(exchange)
// 放入当前上下文,类似于ThreadLocal
.contextWrite(context -> {
// header 中是否有TRACE-ID
String traceId = exchange.getRequest().getHeaders().getFirst(TRACE_ID);
traceId = Optional.ofNullable(traceId).orElse("");
if (!StringUtils.hasText(traceId)) {
log.warn("TRACE_ID not present in header: {}", exchange.getRequest().getURI());
}
Context contextTmp = context.put(TRACE_ID, traceId);
exchange.getAttributes().put(TRACE_ID, traceId);
return contextTmp;
});
}
}
实现WebFilter,通过contextWrite方法,把Header中的trace-id存入到上下文中。这个ContextWrite很重要,它是类似于ThreadLocal的东西,如果有老铁不知道,可以参考Context翻译文章,这里我们就不在一一赘述啦。
实现了WebFilter后,并且放入了Context中,这样我们是不是想ThreadLocal一样,取出来直接用就可以了?of course!
2.2.2 步骤2 - 切面
直接贴代码,如下(方式一)。
/**
* <br>日志切面</br>
*
* @author fattyca1@qq.com
* @since 2022/8/10
*/
@Aspect
@Configuration
@Slf4j
public class LoggerAspect {
@Around("@annotation(com.fattycal.demo.webflux.annotation.Loggable)")
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object result = joinPoint.proceed();
if (result instanceof Mono) {
Mono monoResult = (Mono) result;
AtomicReference<String> traceId = new AtomicReference<>("");
return monoResult.flatMap(ret -> Mono.subscriberContext().map(ctx -> {
// 从Context中取出traceId, 放入到了AtomicReference,正常变量没办法操作(内部类)。
traceId.set(ctx.getOrDefault(ConstantsFields.TRACE_ID, ""));
return ret;
}))
.doOnSuccess(o -> {
String response = "";
if (Objects.nonNull(o)) {
response = o.toString();
}
log.info("【{}】,Enter: {}.{}() with argument[s] = {}", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs());
log.info("【{}】,Exit: {}.{}() had arguments = {}, with result = {}, Execution time = {} ms", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs()[0],
response, (System.currentTimeMillis() - start));
});
}
return result;
}
}
我们直接通过切面,来判断响应结果是否是属于Mono,如果是,则通过flatmap结合Mono.subscriberContext()拿到traceId,然后在doOnSuccess中打印日志。这样的好处是,不用自己订阅Mono.subscriberContext()。
有的哥们就会问,为啥不在doOnSuccess()中去订阅呢? 好问题,我们的尝试一下。代码如下(方式二)。
@Aspect
@Configuration
@Slf4j
public class LoggerAspect {
@Around("@annotation(com.fattycal.demo.webflux.annotation.Loggable)")
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object result = joinPoint.proceed();
if (result instanceof Mono) {
Mono monoResult = (Mono) result;
// 错误的实现方式
return monoResult.doOnSuccess(obj -> Mono.subscriberContext()
.map(ctx -> {
String traceId = ctx.getOrDefault(ConstantsFields.TRACE_ID, "");
String response = "";
if (Objects.nonNull(obj)) {
response = obj.toString();
}
log.info("【{}】,Enter: {}.{}() with argument[s] = {}", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs());
log.info("【{}】,Exit: {}.{}() had arguments = {}, with result = {}, Execution time = {} ms", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs()[0],
response, (System.currentTimeMillis() - start));
return ctx;
})
);
}
return result;
}
}
一激动,马上唰唰写出来了,但是这样写可不可以呢(文章已标记是错误的写法)?为啥说是错误的写法呢,那是因为在Reactor3中,有一个至理名言,那就是nothing happens until you subscribe()。我们没有订阅,所以Mono.subscriberContext().map()这一个流不会被执行的(点完餐付完钱店家才确定要做)。
所以我们稍微动一下代码,如下。
/**
* <br>日志切面</br>
*
* @author fattyca1@qq.com
* @since 2022/8/10
*/
@Aspect
@Configuration
@Slf4j
public class LoggerAspect {
@Around("@annotation(com.fattycal.demo.webflux.annotation.Loggable)")
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object result = joinPoint.proceed();
if (result instanceof Mono) {
Mono monoResult = (Mono) result;
// 把doOnSuccess这个操作放到单独线程池里做
return monoResult.publishOn(Schedulers.newElastic("fattyca1-thread-pool")).doOnSuccess(obj -> Mono.subscriberContext()
.map(ctx -> {
String traceId = ctx.getOrDefault(ConstantsFields.TRACE_ID, "");
String response = "";
if (Objects.nonNull(obj)) {
response = obj.toString();
}
log.info("【{}】,Enter: {}.{}() with argument[s] = {}", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs());
log.info("【{}】,Exit: {}.{}() had arguments = {}, with result = {}, Execution time = {} ms", traceId,
joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName(),
joinPoint.getArgs()[0],
response, (System.currentTimeMillis() - start));
return ctx;
}).subscribe()
);
}
return result;
}
}
我们在map方法后面又增加了subscribe()方法,这个时候,付钱了,餐馆才给你做饭。当然,我们又添加了publishOn这个方法,那是因为subscribe()是阻塞的,为了不阻塞,我们放进了一个新的线程池中处理。这样我们就大功告成啦! 马上动手测试一下
2.2.3 品尝果实
我们直接来一个朴实无华的测试,代码如下。
@RestController
public class WebfluxController {
@RequestMapping("/hi/{name}")
@Loggable
public Mono<String> helloWorld(@PathVariable("name") String name) {
return Mono.fromSupplier(() -> "hi, " + name);
}
}
2.2.3.1 (方式一)
先按照方式一的方式来测试,结果如图所示。
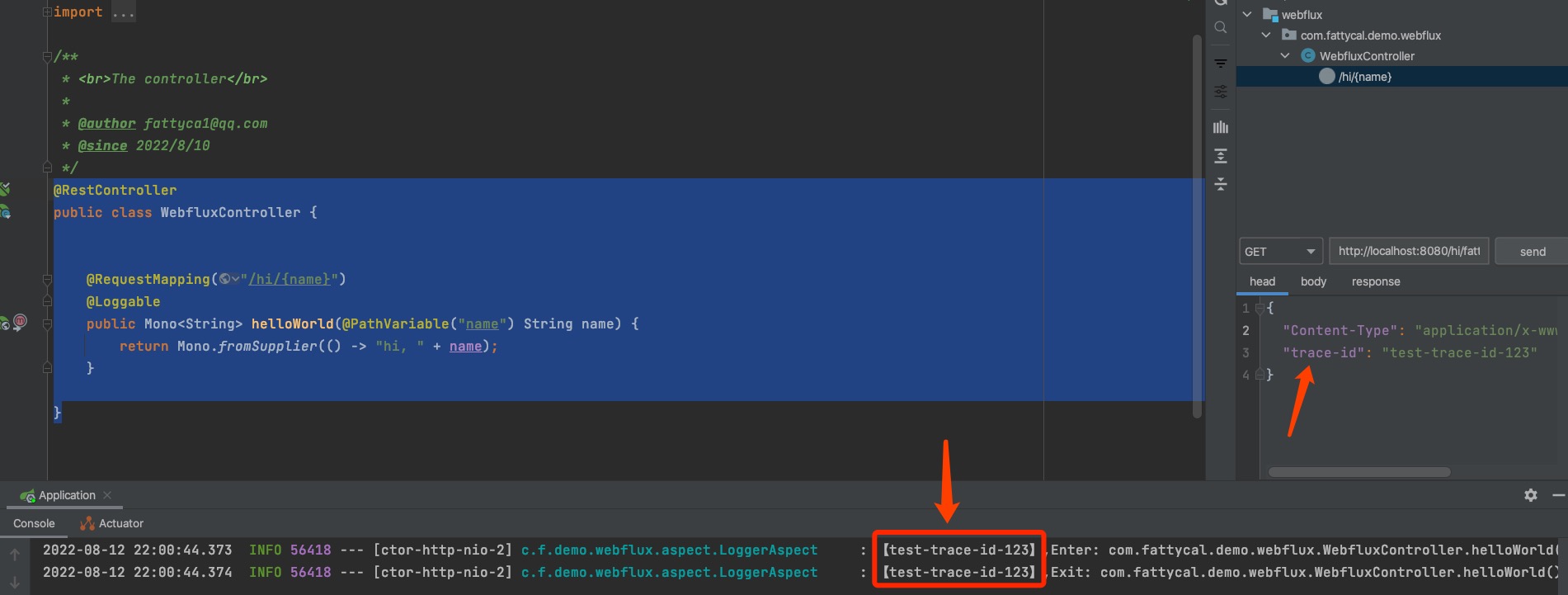
方式一测试出来,的确没问题,我们把Header中的Trace-id打印出来了。那接下来试试方式二。
2.2.3.2 (方式二)
方式一实现方式测试,结果如图所示。
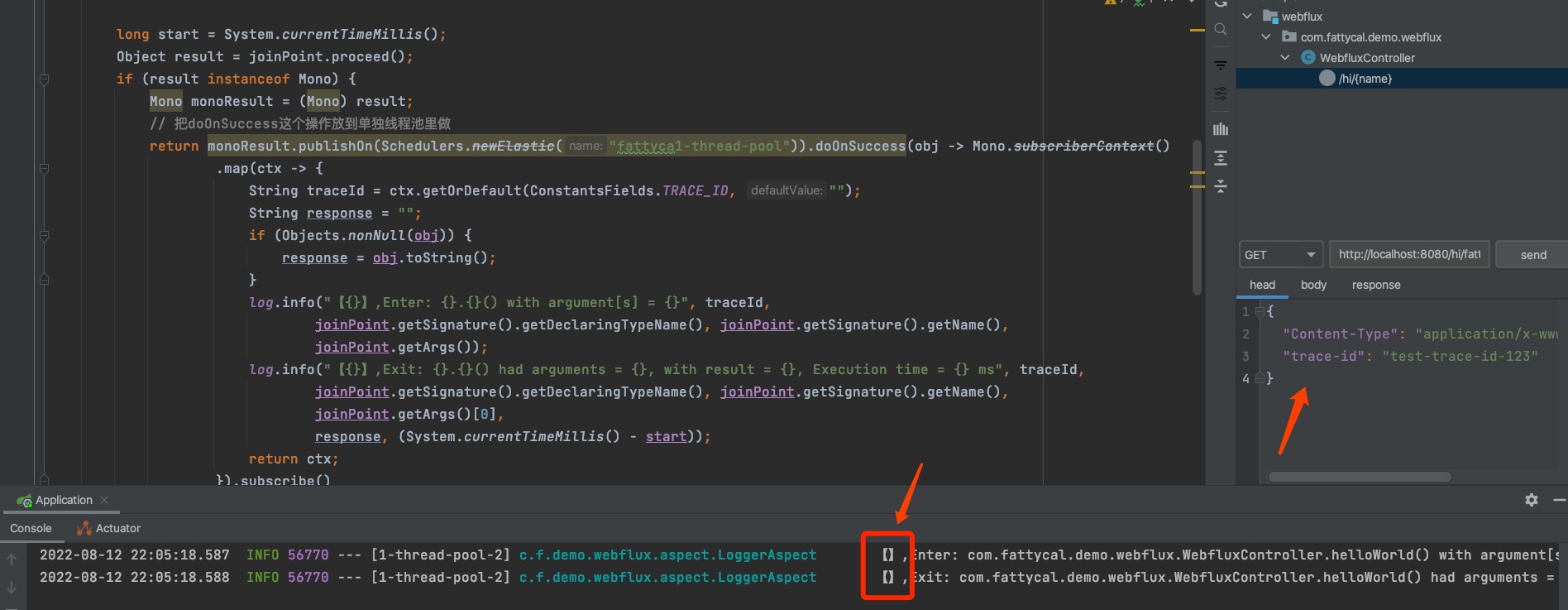
擦,扑街了~,从测试结果看,这样的方式是取不到Context中的值,我在尝试去掉线程池后,也还是取不到Context中的值。为什么没有取到这一点,还没研究透,后面研究透了给大家补上。
从结果看,我们还是通过FlatMap的方式,提前拿到Trace-id还是靠谱一点。
2.2.3.2 测试三
我们修改了一下Controller中的代码,通过flatMap,从Context中获取traceId。再测试一下。结果如图所示。
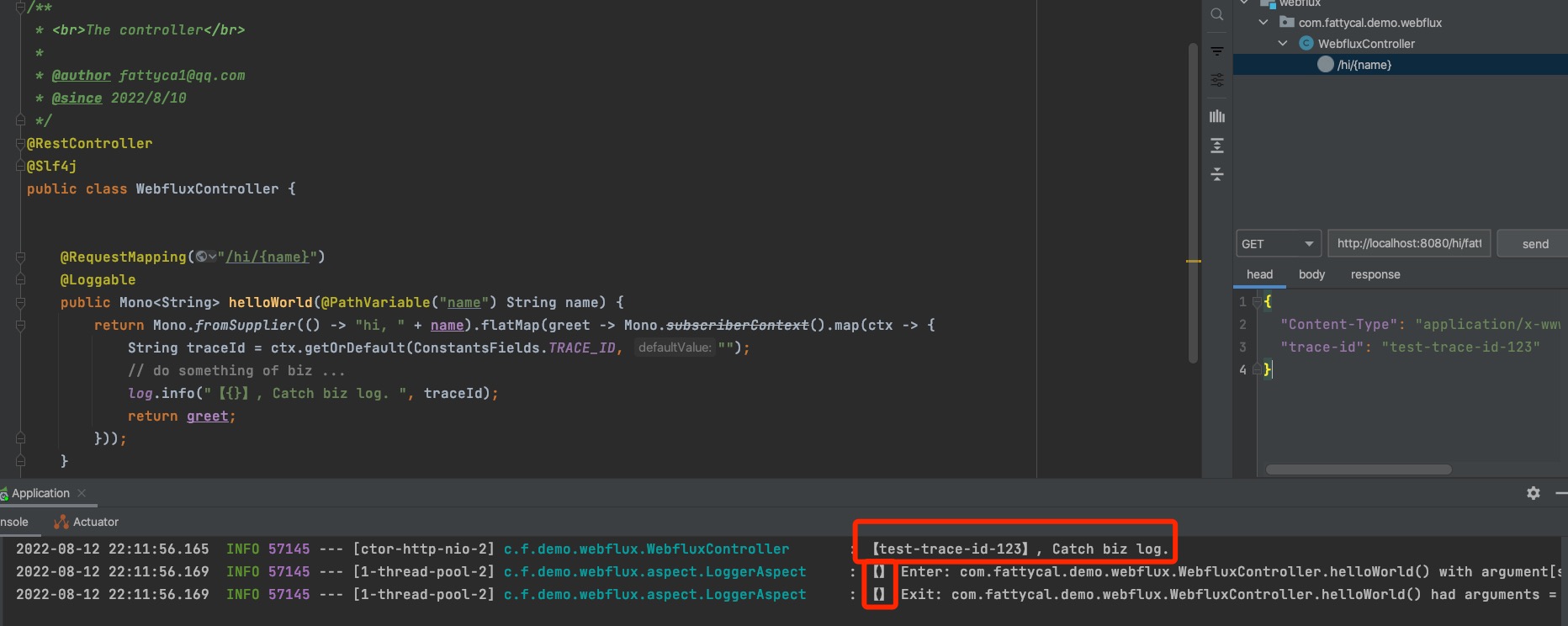
通过测试我们发下,通过flatmap,然后再从Context中获取traceId是完全可行的,所以我们在实际使用的时候还是要注意下方式。
三、总结
先实践,实操,在理解原理。以上为实际实践,如果发现有问题,欢迎指出,交流!
(WebFlux)002、如何打印日志与链路ID的更多相关文章
- 基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪
原文链接:基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪 一.日志系统 1.日志框架 在每个系统应用中,我们都会使用日志系统,主要是为了记录必要的信息和方便排 ...
- Mybatis框架基于映射文件和配置文件的方式,实现增删改查,可以打印日志信息
首先在lib下导入: 与打印日志信息有关的架包 log4j-1.2.16.jar mybatis架包:mybatis-3.1.1.jar 连接数据库的架包:mysql-connector-java-5 ...
- android112 c代码打印日志,c反编译调用java
activity: package com.itheima.ccalljava; import android.os.Bundle; import android.app.Activity; impo ...
- 以打印日志为荣之logging模块详细使用
啄木鸟社区里的Pythonic八荣八耻有一条: 以打印日志为荣 , 以单步跟踪为耻; 很多程序都有记录日志的需求,并且日志中包含的信息既有正常的程序访问日志,还可能有错误.警告等信息输出,python ...
- springboot aop + logback + 统一异常处理 打印日志
1.src/resources路径下新建logback.xml 控制台彩色日志打印 info日志和异常日志分不同文件存储 每天自动生成日志 结合myibatis方便日志打印(debug模式) < ...
- 大数据项目中js中代码和java中代码(解决Tomcat打印日志中文乱码)
Idea2018中集成Tomcat9导致OutPut乱码找到tomcat的安装目录,打开logging.properties文件,增加一行代码,覆盖默认设置,将日志编码格式修改为GBK.java.ut ...
- Java中打印日志,这4点很重要!
目录 一.预先判断日志级别 二.避免无效日志打印 三.区别对待错误日志 四.保证记录完整内容 打印日志,要注意下面4点. 一.预先判断日志级别 对DEBUG.INFO级别的日志,必须使用条件输出或者使 ...
- 关于spring 事务 和 AOP 管理事务和打印日志问题
关于spring 事务 和 AOP 管理事务和打印日志问题 1. 就是支持事务注解的(@Transactional) . 可以在server层总使用@Transactional,进行方法内的事务管 ...
- Java如何打印日志
以下为<正确的打日志姿势>学习笔记. 什么时候打日志 1.程序出现问题,只能通过 debug 功能来定位问题,很大程度是日志没打好.良好的系统,通过日志就能进行问题定位. 2.if-els ...
随机推荐
- [XJOI3529] 左右
题目链接:左右 Description 给你一个s数组,一个t数组,你可以对s数组执行以下两种操作 L 操作:每个数等于其左边的数加上自己 R 操作:每个数等于其右边的数加上自己 第一个数的左边是最后 ...
- Spring AOP快速使用教程
Spring是方法级别的AOP框架,我们主要也是以某个类的某个方法作为连接点,用动态代理的理论来说,就是要拦截哪个方法织入对应的AOP通知.为了更方便的测试我们首先创建一个接口 public in ...
- python 的 @staticmethod和@classmethod和普通实例方法
参考:https://www.huaweicloud.com/articles/12607084.html https://blog.csdn.net/qq_30708445/article/deta ...
- Docker安装Jenkins打包Maven项目为Docker镜像并运行【保姆级图文教学】
一.前言 Jenkins作为CI.CD的先驱者,虽然现在的风头没有Gitlab强了,但是还是老当益壮,很多中小公司还是使用比较广泛的.最近小编经历了一次Jenkins发包,感觉还不错,所以自己学习了一 ...
- WinForms拖控件拖到天荒地老
更新记录: 2022年4月15日:本文迁移自Panda666原博客,原发布时间:2021年4月18日. 2022年4月15日:更新自动生成Web CURD工具. 说明 Winforms的控件拖起来是真 ...
- SSH和SCP的使用方法
1.SSH使用方法 ssh 用户名@IP 例: ssh ubuntu@192.168.1.190 最近因为项目需求,需要通过ssh来登录Windows,但是一开始一直无法登录,参考下面这个帖子解决了, ...
- Vue回炉重造之图片加载性能优化
前言 图片加载优化对于一个网站性能好坏起着至关重要的作用.所以我们使用Vue来操作一波.备注 以下的优化一.优化二栏目都是我自己封装在Vue的工具函数里,所以请认真看完,要不然直接复制的话,容易出错的 ...
- 压测工具Apache Bench的安装与使用
压测工具使用指南: Apache Bench 下载64位 压缩 cmd打开bin目录 使用abs.exe [option] http[s]://www.asb.com 来测试 其中option: -n ...
- 如何通过WinDbg获取方法参数值
引入 我们在调试的过程中,经常会通过查看方法的输入与输出来确定这个方法是否异常.那么我们要怎么通过 WinDbg 来获取方法的参数值呢? WinDbg 中主要包含三种命令:标准命令.元命令(以 . 开 ...
- DTCC 干货分享:Real Time DaaS - 面向TP+AP业务的数据平台架构
2021年10月20日,Tapdata 创始人唐建法(TJ)受邀出席 DTCC 2021(中国数据库技术大会),并在企业数据中台设计与实践专场上,发表主旨演讲"Real Time Daa ...