NLP之TextLSTM(预测单词下一个字母)
LSTM
1.理论
1.1 LSTM与RNN
1.1.1 RNN的缺点
如果训练非常深的神经网络,对这个网络做从左到右的前向传播和而从右到左的后向传播,会发现输出\(y^{<t>}\)很难传播回去,很难影响前面的权重,这样的梯度消失问题使得RNN常常出现局部效应,不擅长处理长期依赖的问题
和梯度爆炸不同的是,梯度爆炸会使得参数爆炸,很容易就发现大量的NaN参数,因此可以很快地进行梯度修剪;但是梯度消失不仅难以察觉,而且很难改正
1.1.2 LSTM
LSTM(还有GRU)改变了RNN的隐藏层,使其可以更好地捕捉深层链接,改善梯度消失的问题
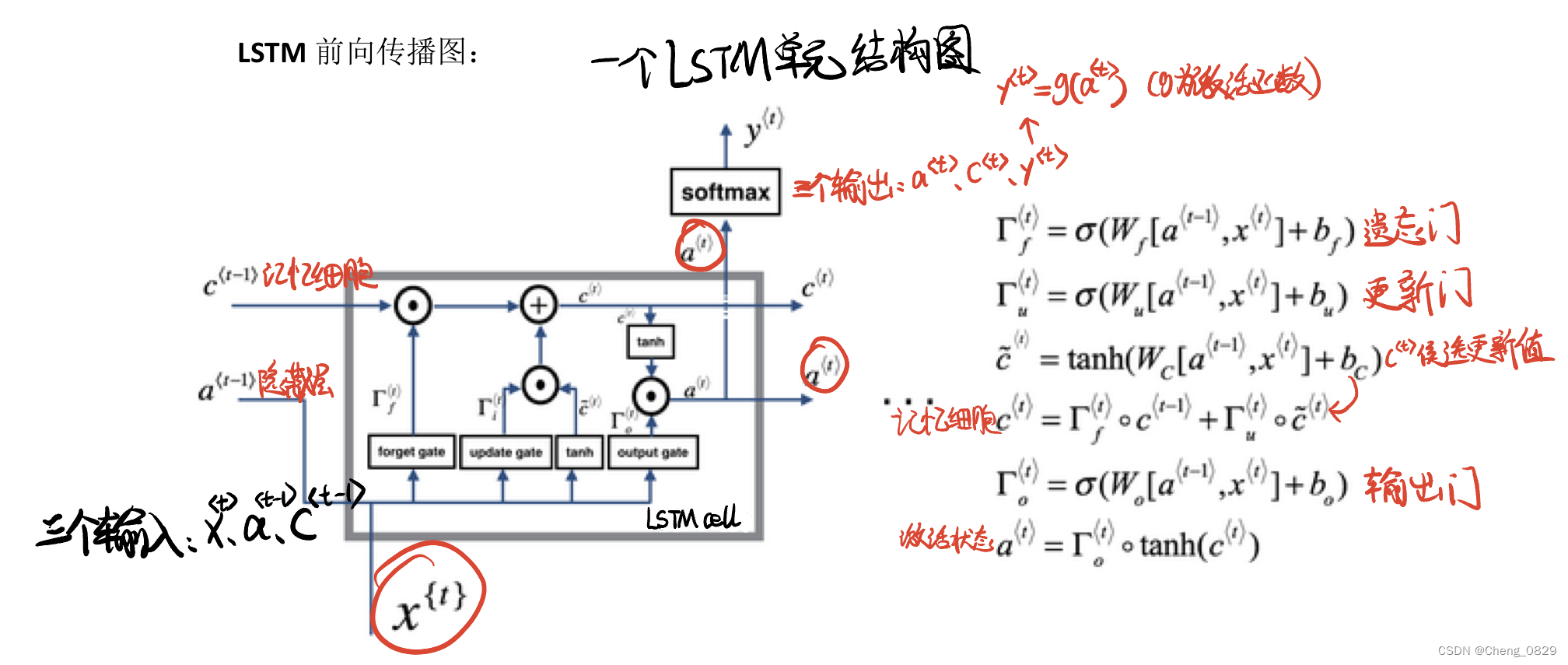
1.2 LSTM基本结构
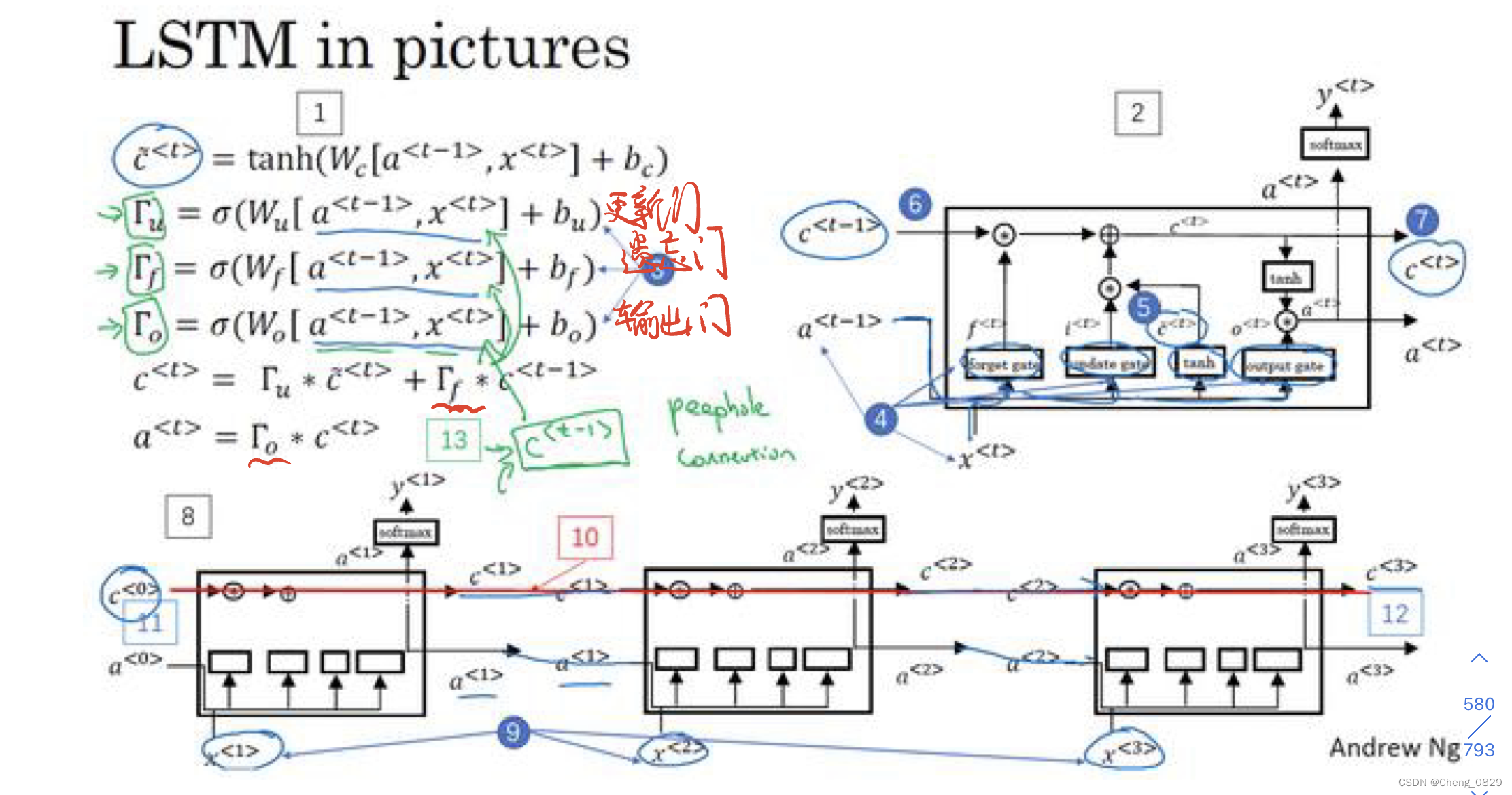
2.实验
2.1 实验步骤
- 数据预处理,得到字典、样本数等基本数据
- 构建LSTM模型,设置输入模型的嵌入向量维度,隐藏层α向量和记忆细胞c的维度
- 训练
- 代入数据,设置每个样本的时间步长度
- 得到模型输出值,取其中最大值的索引,找到字典中对应的字母,即为模型预测的下一个字母.
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 测试
2.2 算法模型
- 一个LSTM细胞单元有三个输入,分别是输入向量\(x^{<t>}\)、隐藏层向量\(a^{<t-1>}\)和记忆细胞\(c^{<t-1>}\);
- 一个LSTM细胞单元有三个输出,分别是输出向量\(y^{<t>}\)、隐藏层向量\(a^{<t>}\)和记忆细胞\(c^{<t>}\)
- 本实验时间步长度n=3,即使用了三个LSTM细胞单元
"""
Task: 基于TextLSTM的单词字母预测
Author: ChengJunkai @github.com/Cheng0829
Email: chengjunkai829@gmail.com
Date: 2022/09/09
Reference: Tae Hwan Jung(Jeff Jung) @graykode
"""
import numpy as np
import torch, os, sys, time
import torch.nn as nn
import torch.optim as optim
'''1.数据预处理'''
def pre_process(seq_data):
char_arr = [c for c in 'abcdefghijklmnopqrstuvwxyz']
word_dict = {n:i for i, n in enumerate(char_arr)}
number_dict = {i:w for i, w in enumerate(char_arr)}
# 字母类别数:26,即嵌入向量维度
n_class = len(word_dict) # number of class(=number of vocab)
return char_arr, word_dict, number_dict, n_class
'''根据句子数据,构建词元的嵌入向量及目标词索引'''
def make_batch(seq_data):
input_batch, target_batch = [], []
# 每个样本单词
for seq in seq_data:
# e.g. input : ['m','a','k'] -> [num1, num2, num3]
input = [word_dict[n] for n in seq[:-1]]
target = word_dict[seq[-1]] # e.g. 'e' is target
input_batch.append(np.eye(n_class)[input])
target_batch.append(target)
'''input_batch : [batch_size(样本数), n_step(样本单词数), n_class] -> [10, 3, 26]'''
input_batch = torch.FloatTensor(np.array(input_batch))
# print(input_batch.shape)
target_batch = torch.LongTensor(np.array(target_batch))
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
return input_batch, target_batch
'''2.构建模型:LSTM(本实验结构图详见笔记)'''
class TextLSTM(nn.Module):
def __init__(self):
super().__init__()
# n_class是字母类别数(26),即嵌入向量维度
self.lstm = nn.LSTM(input_size=n_class, hidden_size=hidden_size)
self.W = nn.Linear(hidden_size, n_class, bias=False)
self.b = nn.Parameter(torch.ones([n_class]))
'''每个样本输入的单词数和模型的时间步长度相等'''
def forward(self, X):
# X : [batch_size, n_step, n_class] [10, 3, 26]
# input : [n_step, batch_size, n_class] [3, 10, 26]
# input : [输入序列长度(时间步长度),样本数,嵌入向量维度]
'''transpose转置: [10, 3, 26] -> [3, 10, 26]'''
input = X.transpose(0, 1)
# hidden_state:[num_layers*num_directions, batch_size, hidden_size]
# hidden_state:[层数*网络方向,样本数,隐藏层的维度(隐藏层神经元个数)]
hidden_state = torch.zeros(1, len(X), hidden_size)
hidden_state = hidden_state.to(device)
# cell_state:[num_layers*num_directions, batch_size, hidden_size]
# cell_state:[层数*网络方向,样本数,隐藏层的维度(隐藏层神经元个数)]
cell_state = torch.zeros(1, len(X), hidden_size)
cell_state = cell_state.to(device)
'''
一个LSTM细胞单元有三个输入,分别是$输入向量x^{<t>}、隐藏层向量a^{<t-1>}
和记忆细胞c^{<t-1>}$;一个LSTM细胞单元有三个输出,分别是$输出向量y^{<t>}、
隐藏层向量a^{<t>}和记忆细胞c^{<t>}$
'''
# outputs:[3,10,128] final_hidden_state:[1,10,128] final_cell_state:[1,10,128])
outputs, (final_hidden_state, final_cell_state) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs.to(device)
'''取最后一个单元的隐藏层激活状态输出值'''
'''既可以用outputs[-1],也可以用final_hidden_state[0]'''
final_output = outputs[-1] # [batch_size, hidden_size]
Y_t = self.W(final_output) + self.b # Y_t : [batch_size, n_class]
return Y_t
if __name__ == '__main__':
hidden_size = 128 # number of hidden units in one cell
device = ['cuda:0' if torch.cuda.is_available() else 'cpu'][0]
seq_data = ['make', 'need', 'coal', 'word', 'love', 'hate', 'live', 'home', 'hash', 'star']
'''1.数据预处理'''
char_arr, word_dict, number_dict, n_class = pre_process(seq_data)
input_batch, target_batch = make_batch(seq_data)
'''2.构建模型'''
model = TextLSTM()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
if os.path.exists('model_param.pt') == True:
# 加载模型参数到模型结构
model.load_state_dict(torch.load('model_param.pt', map_location=device))
'''3.训练'''
print('{}\nTrain\n{}'.format('*'*30, '*'*30))
loss_record = []
for epoch in range(1000):
optimizer.zero_grad()
# X : [batch_size, n_step, n_class]
output = model(input_batch)
output = output.to(device)
loss = criterion(output, target_batch)
loss.backward()
optimizer.step()
if loss >= 0.001: # 连续30轮loss小于0.01则提前结束训练
loss_record = []
else:
loss_record.append(loss.item())
if len(loss_record) == 30:
torch.save(model.state_dict(), 'model_param.pt')
break
if ((epoch+1) % 100 == 0):
print('Epoch:', '%04d' % (epoch + 1), 'Loss = {:.6f}'.format(loss))
torch.save(model.state_dict(), 'model_param.pt')
'''4.预测'''
print('{}\nTest\n{}'.format('*'*30, '*'*30))
inputs = ['mak','ma','look'] # make look
for input in inputs: # 每个样本逐次预测,避免长度不同
input_batch, target_batch = make_batch([input])
predict = model(input_batch).data.max(1, keepdim=True)[1]
print(input + ' -> ' + input + number_dict[predict.item()])
'''
为什么训练集输入字母数都是3,但是测试集可以不是?
make_batch的input_batch维度是[batch_size(样本数), n_step(样本单词数),n_class(26)]
n_step是输入序列长度,之前疑惑为什么只有3个lstm单元,却可以输入其他个数的字母?
实际上,模型并没有把时间步作为一个超参数,也就是时间步随输入样本而变化,在训练集中,n_step均为3,
但是,在测试集中,三个单词都是分别作为样本集输入的,也就是时间步分别为3,2,4,
最后在self.lstm(input, (hidden_state, cell_state))中,模型会自动根据input的序列长度,分配时间步
但由于是一次性输入一个样本集,所以样本集中各个样本长度必须一致,否则报错
因此必须把预测的inputs中各个单词分别放进容量为1的样本集单独输入
需要指出的是,由于模型训练的是根据3个字母找到最后以1个字母,
所以如果长度不匹配,即使单词在训练集中,
也不能取得好的结果,比如"ma"的预测结果并不一定是训练集中的"mak"
'''
NLP之TextLSTM(预测单词下一个字母)的更多相关文章
- 给定一个字符串,把字符串内的字母转换成该字母的下一个字母,a换成b,z换成a,Z换成A,如aBf转换成bCg, 字符串内的其他字符不改变,给定函数,编写函数 void Stringchang(const char*input,char*output)其中input是输入字符串,output是输出字符串
import java.util.Scanner; /*** * 1. 给定一个字符串,把字符串内的字母转换成该字母的下一个字母,a换成b,z换成a,Z换成A,如aBf转换成bCg, 字符串内的其他字 ...
- java 获取下一个字母(传大写返回大写,传小写返回小写)
public static String getNextUpEn(String en){ char lastE = 'a'; char st = en.toCharArray()[0]; if(Cha ...
- NLP之Bi-LSTM(在长句中预测下一个单词)
Bi-LSTM @ 目录 Bi-LSTM 1.理论 1.1 基本模型 1.2 Bi-LSTM的特点 2.实验 2.1 实验步骤 2.2 实验模型 1.理论 1.1 基本模型 Bi-LSTM模型分为2个 ...
- NLP之TextRNN(预测下一个单词)
TextRNN @ 目录 TextRNN 1.基本概念 1.1 RNN和CNN的区别 1.2 RNN的几种结构 1.3 多对多的RNN 1.4 RNN的多对多结构 1.5 RNN的多对一结构 1.6 ...
- 引爆公式让你的APP游戏成为下一个“爆款”
在2014年的移动互联网领域,“魔漫相机”是一款值得关注的产品.虽然没有腾讯.百度或阿里巴巴等大资源的支持,但是这款应用一上线就在中国市场发展迅猛,日下载量超过80万次,最高一日达300万次.类似的成 ...
- cs224d 作业 problem set2 (三) 用RNNLM模型实现Language Model,来预测下一个单词的出现
今天将的还是cs224d 的problem set2 的第三部分习题, 原来国外大学的系统难度真的如此之大,相比之下还是默默地再天朝继续搬砖吧 下面讲述一下RNN语言建模的数学公式: 给出一串连续 ...
- [ACM] POJ 1035 Spell checker (单词查找,删除替换添加不论什么一个字母)
Spell checker Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 18693 Accepted: 6844 De ...
- C语言:假定输入的字符串只包含字母和*号,fun函数:除了尾部的*号以外,将字符的其他*号进行全部删除,形参p已经指向字符串中最后一个字母。-利用折半查找整数m在有序数组中的位置,若找到,返回下标值,否则返回-1。
//假定输入的字符串只包含字母和*号,fun函数:除了尾部的*号以外,将字符的其他*号进行全部删除,形参p已经指向字符串中最后一个字母. #include <stdio.h> void f ...
- JS中将字符串中每个单词的首字母大写化
今天看到一个帖子,处理js中字符串每个单词的首字母大写. 原贴地址:关于字符串中每个单词的首字母大写化问题 受到启发,自己跟着改写了几个版本如下,请大家指正. 1.for循环: var a = 'Hi ...
随机推荐
- (WebFlux)002、如何打印日志与链路ID
一.背景 最近在持续改造项目,想通过日志查看用户所有的接口链路日志.在原来基于SpirngMVC的时候,那是比较好处理的,通过ThreadLocal,放入TraceId,就可以把一个TraceId传到 ...
- java-前端之HTML
--html网页简单使用 1.html网页的基本标签 <!doctype html><!-- 声明网页版本 --> <html><!-- 唯一的跟元素 --& ...
- linux --stdin 管道 标准输入重定向
linux --stdin 标准输入重定向 --stdin This option is used to indicate that passwd should read the new passwo ...
- 【PostgreSQL】PostgreSQL 15移除了Stats Collector
试用即将发行的PostgreSQL 15的人会发现少了一个后台进程: postgres 1710 1 0 04:03 ? 00:00:00 /usr/pgsql-15/bin/postmaster ...
- AtCoder Beginner Contest 264(D-E)
D - "redocta".swap(i,i+1) 题意: 给一个字符串,每次交换相邻两个字符,问最少多少次变成"atcoder" 题解: 从左到右依次模拟 # ...
- C# using()的本质
" 程序世界没有秘密,所有答案都在源码里 " 01.点明观点 C#中,非托管资源使用之后必须释放,而using()是使用非托管资源的最佳方式,可以确保资源在代码块结束之后被正确释放 ...
- .Net Core 配置文件读取 - IOptions、IOptionsMonitor、IOptionsSnapshot
原文链接:https://www.cnblogs.com/ysmc/p/16637781.html 众所周知,appsetting.json 配置文件是.Net 的重大革新之心,抛开了以前繁杂的xml ...
- 小技巧:webpack中@的配置和用法
好家伙, 当我们要各种两个文件去引用别的文件时,一般这么写 import msg from '../../msg.js' 那么如果文件藏得很深,'../'会变得很多,不美观,也不直观 所以我们又又又可 ...
- Linux虚拟机 RHEL8.0安装步骤
一. 创建空白虚拟机 1.打开 VMware 虚拟机软件依次选择新建虚拟机并选择选择"自定义" 自定义功能更加全面,典型就是比较简单的配置 2.选择对应的 VMware 版本,此则 ...
- KingbaseES 参数 - ora_statement_level_rollback
参数 ora_statement_level_rollback 控制KingbaseES 是否实现类似oracle 语句级的回滚.当该参数打开时,如果事务操作失败,仅会回滚最后一条操作,避免了全部操作 ...