深入理解 Python 虚拟机:元组(tuple)的实现原理及源码剖析
深入理解 Python 虚拟机:元组(tuple)的实现原理及源码剖析
在本篇文章当中主要给大家介绍 cpython 虚拟机当中针对列表的实现,在 Python 中,tuple 是一种非常常用的数据类型,在本篇文章当中将深入去分析这一点是如何实现的。
元组的结构
在这一小节当中主要介绍在 python 当中元组的数据结构:
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
/* ob_item contains space for 'ob_size' elements.
* Items must normally not be NULL, except during construction when
* the tuple is not yet visible outside the function that builds it.
*/
} PyTupleObject;
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
从上面的数据结构来看和 list 的数据结构基本上差不多,最终的使用方法也差不多。将上面的结构体展开之后,PyTupleObject 的结构大致如下所示:
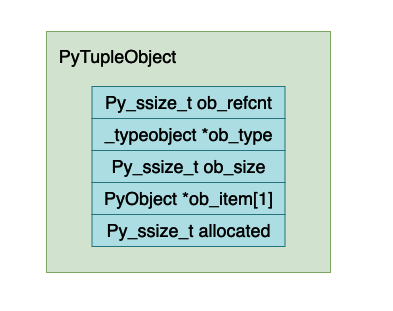
现在来解释一下上面的各个字段的含义:
Py_ssize_t,一个整型数据类型。
ob_refcnt,表示对象的引用记数的个数,这个对于垃圾回收很有用处,后面我们分析虚拟机中垃圾回收部分在深入分析。
ob_type,表示这个对象的数据类型是什么,在 python 当中有时候需要对数据的数据类型进行判断比如 isinstance, type 这两个关键字就会使用到这个字段。
ob_size,这个字段表示这个元组当中有多少个元素。
ob_item,这是一个指针,指向真正保存 python 对象数据的地址,大致的内存他们之间大致的内存布局如下所示:
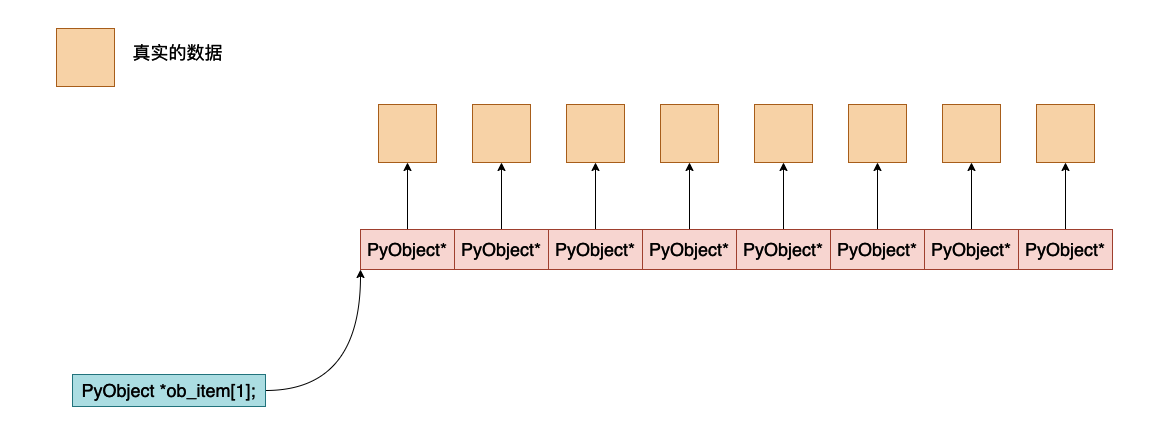
需要注意的是元组的数组大小是不能够进行更改的,这一点和 list 不一样,我们可以注意到在 list 的数据结构当中还有一个 allocated 字段,但是在元组当中是没有的,这主要是因为元组的数组大小是固定的,而列表的数组大小是可以更改的。
元组操作函数源码剖析
创建元组
首先我们需要了解一下在 cpython 内部关于元组内存分配的问题,首先和 list 一样,在 cpython 当中对于分配的好的元组进行释放的时候,并不会直接进行释放,而是会先保存下来,当下次又有元组申请内存的时候,直接将这块内存进行返回即可。
在 cpython 内部会进行缓存的元组大小为 20,如果元组的长度为 0 - 19 那么在申请分配内存之后释放并不会直接释放,而是将其先保存下来,下次有需求的时候直接分配,而不需要申请。在 cpython 内部,相关的定义如下所示:
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
static int numfree[PyTuple_MAXSAVESIZE];
- free_list,保存指针——指向被释放的元组。
- numfree,对应的下标表示元组当中元素的个数,numfree[i] 表示有 i 个元素的元组的个数。
下面是新建 tuple 对象的源程序:
PyObject *
PyTuple_New(Py_ssize_t size)
{
PyTupleObject *op;
Py_ssize_t i;
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
#if PyTuple_MAXSAVESIZE > 0
// 如果申请一个空的元组对象 当前的 free_list 当中是否存在空元组对象 如果存在则直接返回
if (size == 0 && free_list[0]) k
op = free_list[0];
Py_INCREF(op);
return (PyObject *) op;
}
// 如果元组的对象元素个数小于 20 而且对应的 free_list 当中还有余下的元组对象 则不需要进行内存申请直接返回
if (size < PyTuple_MAXSAVESIZE && (op = free_list[size]) != NULL) {
free_list[size] = (PyTupleObject *) op->ob_item[0];
numfree[size]--;
/* Inline PyObject_InitVar */
_Py_NewReference((PyObject *)op); // _Py_NewReference 这个宏是将对象 op 的引用计数设置成 1
}
else
#endif
{
/* Check for overflow */
// 如果元组的元素个数大或者等于 20 或者 当前 free_list 当中没有没有剩余的对象则需要进行内存申请
if ((size_t)size > ((size_t)PY_SSIZE_T_MAX - sizeof(PyTupleObject) -
sizeof(PyObject *)) / sizeof(PyObject *)) {
// 如果元组长度大于某个值直接报内存错误
return PyErr_NoMemory();
}
// 申请元组大小的内存空间
op = PyObject_GC_NewVar(PyTupleObject, &PyTuple_Type, size);
if (op == NULL)
return NULL;
}
// 初始化内存空间
for (i=0; i < size; i++)
op->ob_item[i] = NULL;
#if PyTuple_MAXSAVESIZE > 0
// 因为 size == 0 的元组不会进行修改操作 因此可以直接将这个申请到的对象放到 free_list 当中以备后续使用
if (size == 0) {
free_list[0] = op;
++numfree[0];
Py_INCREF(op); /* extra INCREF so that this is never freed */
}
#endif
_PyObject_GC_TRACK(op); // _PyObject_GC_TRACK 这个宏是将对象 op 将入到垃圾回收队列当中
return (PyObject *) op;
}
新建元组对象的流程如下所示:
- 查看 free_list 当中是否已经存在空闲的元组,如果有则直接进行返回。
- 如果没有,则进行内存分配,然后将申请的内存空间进行初始化操作。
- 如果 size == 0,则可以将新分配的元组对象放到 free_list 当中。
查看元组的长度
这个功能比较简单,直接只用 cpython 当中的宏 Py_SIZE 即可。他的宏定义为 #define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)。
static Py_ssize_t
tuplelength(PyTupleObject *a)
{
return Py_SIZE(a);
}
元组当中是否包含数据
这个其实和 list 一样,就是遍历元组当中的数据,然后进行比较即可。
static int
tuplecontains(PyTupleObject *a, PyObject *el)
{
Py_ssize_t i;
int cmp;
for (i = 0, cmp = 0 ; cmp == 0 && i < Py_SIZE(a); ++i)
cmp = PyObject_RichCompareBool(el, PyTuple_GET_ITEM(a, i),
Py_EQ);
return cmp;
}
获取和设置元组中的数据
这两个方法也比较简单,首先检查数据类型是不是元组类型,然后判断是否越界,之后就返回数据,或者设置对应的数据。
这里在设置数据数据的时候需要注意一点的是,当设置新的数据的时候,原来的 python 对象引用计数需要减去一,同理如果设置没有成功的话传入的新的数据的引用计数也需要减去一。
PyObject *
PyTuple_GetItem(PyObject *op, Py_ssize_t i)
{
if (!PyTuple_Check(op)) {
PyErr_BadInternalCall();
return NULL;
}
if (i < 0 || i >= Py_SIZE(op)) {
PyErr_SetString(PyExc_IndexError, "tuple index out of range");
return NULL;
}
return ((PyTupleObject *)op) -> ob_item[i];
}
int
PyTuple_SetItem(PyObject *op, Py_ssize_t i, PyObject *newitem)
{
PyObject *olditem;
PyObject **p;
if (!PyTuple_Check(op) || op->ob_refcnt != 1) {
Py_XDECREF(newitem);
PyErr_BadInternalCall();
return -1;
}
if (i < 0 || i >= Py_SIZE(op)) {
Py_XDECREF(newitem);
PyErr_SetString(PyExc_IndexError,
"tuple assignment index out of range");
return -1;
}
p = ((PyTupleObject *)op) -> ob_item + i;
olditem = *p;
*p = newitem;
Py_XDECREF(olditem);
return 0;
}
释放元组内存空间
当我们在进行垃圾回收的时候,判定一个对象的引用计数等于 0 的时候就需要释放这块内存空间(相当于析构函数),下面就是释放 tuple 内存空间的函数。
static void
tupledealloc(PyTupleObject *op)
{
Py_ssize_t i;
Py_ssize_t len = Py_SIZE(op);
PyObject_GC_UnTrack(op); // PyObject_GC_UnTrack 将对象从垃圾回收队列当中移除
Py_TRASHCAN_SAFE_BEGIN(op)
if (len > 0) {
i = len;
while (--i >= 0)
// 将这个元组指向的对象的引用计数减去一
Py_XDECREF(op->ob_item[i]);
#if PyTuple_MAXSAVESIZE > 0
// 如果这个元组对象满足加入 free_list 的条件,则将这个元组对象加入到 free_list 当中
if (len < PyTuple_MAXSAVESIZE &&
numfree[len] < PyTuple_MAXFREELIST &&
Py_TYPE(op) == &PyTuple_Type)
{
op->ob_item[0] = (PyObject *) free_list[len];
numfree[len]++;
free_list[len] = op;
goto done; /* return */
}
#endif
}
Py_TYPE(op)->tp_free((PyObject *)op);
done:
Py_TRASHCAN_SAFE_END(op)
}
将元组的内存空间回收的时候,主要有以下几个步骤:
- 将元组对象从垃圾回收链表当中移除。
- 将元组指向的所有对象的引用计数减一。
- 判断元组是否满足保存到 free_list 当中的条件,如果满足就将他加入到 free_list 当中去,否则回收这块内存。加入到 free_list 当中整个元组当中 ob_item 指向变化如下所示:

- 如果不能够将释放的元组对象加入到 free_list 当中,否则将内存释放回收。
总结
在本篇文章当中主要介绍了在 cpython 当中是如何实现 tuple 的,以及相关的数据结构和一些基本的使用函数,最后简单谈了关于元组内存释放的问题,这里面还是涉及一些其他的知识点,不能够在这篇文章进行分析,在本文内存分配主要是聚焦在元组身上,主要是分析内存分配和 tuple 的 free_list 是如何交互的。
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址:https://github.com/Chang-LeHung/dive-into-cpython
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
深入理解 Python 虚拟机:元组(tuple)的实现原理及源码剖析的更多相关文章
- 一个Python开源项目-腾讯哈勃沙箱源码剖析(上)
前言 2019年来了,2020年还会远吗? 请把下一年的年终奖发一下,谢谢... 回顾逝去的2018年,最大的改变是从一名学生变成了一位工作者,不敢说自己多么的职业化,但是正在努力往那个方向走. 以前 ...
- 《python解释器源码剖析》第12章--python虚拟机中的函数机制
12.0 序 函数是任何一门编程语言都具备的基本元素,它可以将多个动作组合起来,一个函数代表了一系列的动作.当然在调用函数时,会干什么来着.对,要在运行时栈中创建栈帧,用于函数的执行. 在python ...
- Python源码剖析——02虚拟机
<Python源码剖析>笔记 第七章:编译结果 1.大概过程 运行一个Python程序会经历以下几个步骤: 由解释器对源文件(.py)进行编译,得到字节码(.pyc文件) 然后由虚拟机按照 ...
- 《python解释器源码剖析》第11章--python虚拟机中的控制流
11.0 序 在上一章中,我们剖析了python虚拟机中的一般表达式的实现.在剖析一遍表达式是我们的流程都是从上往下顺序执行的,在执行的过程中没有任何变化.但是显然这是不够的,因为怎么能没有流程控制呢 ...
- 《python解释器源码剖析》第8章--python的字节码与pyc文件
8.0 序 我们日常会写各种各样的python脚本,在运行的时候只需要输入python xxx.py程序就执行了.那么问题就来了,一个py文件是如何被python变成一系列的机器指令并执行的呢? 8. ...
- 《python解释器源码剖析》第1章--python对象初探
1.0 序 对象是python中最核心的一个概念,在python的世界中,一切都是对象,整数.字符串.甚至类型.整数类型.字符串类型,都是对象.换句话说,python中面向对象的理念观测的非常彻底,面 ...
- 《python解释器源码剖析》第0章--python的架构与编译python
本系列是以陈儒先生的<python源码剖析>为学习素材,所记录的学习内容.不同的是陈儒先生的<python源码剖析>所剖析的是python2.5,本系列对应的是python3. ...
- socket_server源码剖析、python作用域、IO多路复用
本节内容: 课前准备知识: 函数嵌套函数的使用方法: 我们在使用函数嵌套函数的时候,是学习装饰器的时候,出现过,由一个函数返回值是一个函数体情况. 我们在使用函数嵌套函数的时候,最好也这么写. def ...
- Python 多线程、多进程 (一)之 源码执行流程、GIL
Python 多线程.多进程 (一)之 源码执行流程.GIL Python 多线程.多进程 (二)之 多线程.同步.通信 Python 多线程.多进程 (三)之 线程进程对比.多线程 一.python ...
- 【Python源码剖析】对象模型概述
Python 是一门 面向对象 语言,实现了一个完整的面向对象体系,简洁而优雅. 与其他面向对象编程语言相比, Python 有自己独特的一面. 这让很多开发人员在学习 Python 时,多少有些无所 ...
随机推荐
- 杭电oj 多项式求和
Problem Description 多项式的描述如下:1 - 1/2 + 1/3 - 1/4 + 1/5 - 1/6 + ...现在请你求出该多项式的前n项的和. Input 输入数据由2行组 ...
- Unity图集打包流程
1.先打开图集打包工具 设置为Always Enables(Legacy Sprite Packer) 打开地址Edit - ProjectSetting-Editor--Sprite Packer ...
- vue父子组件,子组件调用父组件方法
问题描述:在table页面修改数据后,想刷新页面.修改页面以子组件的形式写的,现在想在子组件里面调用父组件的方法实现页面刷新! 将问题google后,以下两种方法都尝试过了,但是不起作用......大 ...
- 文件上传html
<html><head> <meta charset="UTF-8"> <title>上传文件测试</title>< ...
- 项目引入fastclick 导致ios中input需要多次点击才能触发focus
main.js中引入之后的修改 import FastClick from "fastclick"; FastClick.prototype.focus = function (t ...
- JS笔记(三):函数与对象
镇楼图 Pixiv:torino 四.Function类型 Rest语法 一些函数如Math.max可以支持任意数量的参数,JS中对于这样的参数可以简单使用...来实现,使用剩余参数,它支持收集剩余的 ...
- Java开发的事务
代码来自https://blog.csdn.net/weixin_42950079/article/details/99674292 可以看出jdbc的一个事务有这么几个步骤:1.关闭sql自动提交: ...
- 如何安装vm虚拟机软件并用该软件建立虚拟机
一.安装vm虚拟机软件 1.双击打开虚拟机应用程序 找到VM应用程序所在的位置,双击安装 2.根据向导安装 根据提示点击下一步 点击安装之后耐心等待一会,会出现需要输入许可证的的界面,这时候不要关闭界 ...
- 使用SecureCRT通过SSH连接远程Linux设备
Ubuntu安装和配置ssh教程 https://blog.csdn.net/future_ai/article/details/81701744 以SecureCRT为例: 把电脑和设备连接在同一个 ...
- The first blog
这是一只爱碎觉的汪的第一篇博客. 下面就来简单介绍一下自己吧,爱好广泛,尤其热爱钢琴和运动,喜欢每个按键在手指间跳动的感觉,喜欢一个个音符连起来奏响的一曲曲优美的音乐,也喜欢运动后大汗淋漓的畅快感.肯 ...