《Ranked List Loss for Deep Metric Learning》CVPR 2019
Motivation:
深度度量学习的目标是学习一个嵌入空间来从数据点中捕捉语义信息。现有的成对或者三元组方法随着模型迭代过程会出现大量的平凡组导致收敛缓慢。针对这个问题,一些基于排序结构的损失取得了不错的结果,本文主要是针对排序loss存在的两个不足做的改进。
- 不足一:给定一个query,只利用了小部分的数据点来构建相似度结构,导致一些有用信息被忽略。本文给出的解决方案是把样本划分为正例集和负例集,目标是使得query离正例集比负例集近一个间隔。
- 不足二:此前方法都是在嵌入空间尽可能推进正样本的距离忽略了类内差异,作者使用一个超参来保留类内分布。

作者先是回顾了目前存在的一些loss, 从上图可以看到,ranked list loss也就是本文提出的方法,在训练中充分利用了输入样本信息。
本文的想法是把正例样本与负例样本以$m$隔开,类内样本允许存在$\alpha-m$的分布差异,如下图所示:
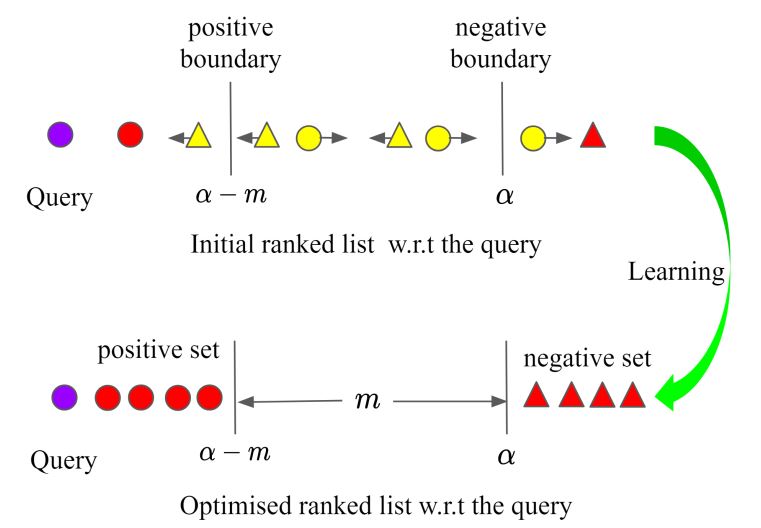
成对约束:
其基于成对损失,上图可以表示为:$L_{\mathrm{m}}\left(\mathbf{x}_{i}, \mathbf{x}_{j} ; f\right)=\left(1-y_{i j}\right)\left[\alpha-d_{i j}\right]_{+}+y_{i j}\left[d_{i j}-(\alpha-m)\right]_{+}$。其中${x}_{i}$为query,$d_{i j}=\left\|f\left(\mathbf{x}_{i}\right)-f\left(\mathbf{x}_{j}\right)\right\|_{2}$为样本间欧式距离,当$y_{i}=y_{j}$时,$y_{i j}=1$,反之为0。
对于每个query $\mathbf{x}_{i}^{c}$,我们对gallery使用距离排序得到列表,其中存在$N_{c}-1$个正例点与$\sum_{k \neq c} N_{k}$个负例点。可以分别表示为$\mathbf{P}_{c, i}=\left\{\mathbf{x}_{j}^{c} | j \neq i\right\},\left|\mathbf{P}_{c, i}\right|=N_{c}-1$与$\mathbf{N}_{c, i}=\left\{\mathbf{x}_{j}^{k} | k \neq c\right\},\left|\mathbf{N}_{c, i}\right|=\sum_{k \neq c} N_{k}$。
难样本挖掘:
难样本挖掘因为收敛速度快,性能好被广泛使用,所谓难样本就是那些违反成对约束,loss值不为0的点。没有使用难样本挖掘在梯度融合时,这些信息量比较大的样本的贡献将被那些梯度为0的样本对削弱。所以我们先找出有贡献的样本。也就是:$\mathbf{P}_{c, i}^{*}=\left\{\mathbf{x}_{j}^{c} | j \neq i, d_{i j}>(\alpha-m)\right\}$与$\mathbf{N}_{c, i}^{*}=\left\{\mathbf{x}_{j}^{k} | k \neq c, d_{i j}<\alpha\right\}$。
基于损失的负样本挖掘:
对于每个query $\mathbf{x}_{i}^{c}$,存在大量困难负样本,它们具有不同的损失值。为了更好的利用它们,作者提出基于损失值来加权负样本,也就是每个负样本违反约束的程度。加权策略可以公式化为:
$w_{i j}=\exp \left(T \cdot\left(\alpha-d_{i j}\right)\right), \mathbf{x}_{j}^{k} \in \mathbf{N}_{c, i}^{*}$
作者注意到前面成对损失相对每个嵌入的梯度都是1.也就是:
$\left\|\frac{\partial L_{\mathrm{m}}\left(\mathbf{x}_{i}, \mathbf{x}_{j} ; f\right)}{\partial f\left(\mathbf{x}_{j}\right)}\right\|_{2}=\left\|\frac{f\left(\mathbf{x}_{i}\right)-f\left(\mathbf{x}_{j}\right)}{\left\|f\left(\mathbf{x}_{i}\right)-f\left(\mathbf{x}_{j}\right)\right\|_{2}}\right\|_{2}=1$
相对而言,作者提出来的则会被$w_{i j}$加权。$T$是一个温度因子,当T等于0时,就会退化为无困难负样本挖掘,当T趋近于无穷大,就会变成最困难负样本挖掘。
优化目标:
对于每个query $\mathbf{x}_{i}^{c}$,优化的目标是让他离正例集合$\mathbf{P}_{c, i}$比负例集合$\mathbf{N}_{c, i}$的距离近$m$。同时,强迫所有的负样本离query的距离大于$\alpha$。这样一来,其实所有的正例也被约束在离query距离$\alpha-m$的范围内。对于正例集的约束如下:
$L_{\mathrm{P}}\left(\mathbf{x}_{i}^{c} ; f\right)=\frac{1}{\left|\mathbf{P}_{c, i}^{*}\right|} \sum_{\mathbf{x}_{j}^{c} \in \mathbf{P}_{c, i}^{*}} L_{\mathrm{m}}\left(\mathbf{x}_{i}^{c}, \mathbf{x}_{j}^{c} ; f\right)$
可以看到作者没有对正例进行加权,这是因为正样本很少。对困难负例的约束为:
$L_{\mathrm{N}}\left(\mathrm{x}_{i}^{c} ; f\right)=\sum_{\mathbf{x}_{j}^{k} \in\left[\mathrm{N}_{c, i}^{*}\right]} \frac{w_{i j}}{\sum_{\mathbf{x}_{j}^{k} \in\left[\mathrm{N}_{c, i}^{*}\right]}^{w_{i j}} L_{\mathrm{m}}\left(\mathbf{x}_{i}^{c}, \mathbf{x}_{j}^{k} ; f\right)}$
总体的损失便是两者的相加:$L_{\mathrm{RLL}}\left(\mathbf{x}_{i}^{c} ; f\right)=L_{\mathrm{P}}\left(\mathbf{x}_{i}^{c} ; f\right)+\lambda L_{\mathrm{N}}\left(\mathbf{x}_{i}^{c} ; f\right)$。在$\mathbf{x}_{i}^{c}$的列表中,我们把其他样本的特征当作固定值,只有$f(\mathbf{x}_{i}^{c})$会通过其他样本影响的加权和进行更新。
学习过程:

首先同样通过$P*K$的采样方式,也就是每批由$P$个人物,每个人物的$K$张图片组成。然后每张图片都被轮流当作query,剩下的就被当成gallery。可以公式化为:
$L_{\mathrm{RLL}}(\mathbf{X} ; f)=\frac{1}{N} \sum_{\forall c, \forall i} L_{\mathrm{RLL}}\left(\mathbf{x}_{i}^{c} ; f\right)$
其中$N$为批大小,算法流程如下:

《Ranked List Loss for Deep Metric Learning》CVPR 2019的更多相关文章
- 论文笔记之: Deep Metric Learning via Lifted Structured Feature Embedding
Deep Metric Learning via Lifted Structured Feature Embedding CVPR 2016 摘要:本文提出一种距离度量的方法,充分的发挥 traini ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
- 论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息 论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning论文作者:Qinghua Zheng ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week2 Neural Networks Basics课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week2 Neural Networks Basics 2.1 ...
- 《Neural Network and Deep Learning》_chapter4
<Neural Network and Deep Learning>_chapter4: A visual proof that neural nets can compute any f ...
- Reading | 《DEEP LEARNING》
目录 一.引言 1.什么是.为什么需要深度学习 2.简单的机器学习算法对数据表示的依赖 3.深度学习的历史趋势 最早的人工神经网络:旨在模拟生物学习的计算模型 神经网络第二次浪潮:联结主义connec ...
- 《Deep Learning》(深度学习)中文版PDF免费下载
<Deep Learning>(深度学习)中文版PDF免费下载 "深度学习"经典著作<Deep Learning>中文版pdf免费下载. <Deep ...
- 《Deep Learning》(深度学习)中文版 开发下载
<Deep Learning>(深度学习)中文版开放下载 <Deep Learning>(深度学习)是一本皆在帮助学生和从业人员进入机器学习领域的教科书,以开源的形式免费在 ...
- 【DeepLearning学习笔记】Coursera课程《Neural Networks and Deep Learning》——Week1 Introduction to deep learning课堂笔记
Coursera课程<Neural Networks and Deep Learning> deeplearning.ai Week1 Introduction to deep learn ...
随机推荐
- 共读《redis设计与实现》-单机(一)
上一章我们讲了 redis 基本类型的数据结构 和 对象系统 ,这篇来说一下单机redis 的知识点. 一.数据库 一个数据库在redis中就有一个结构体,而数据库的结构体是由redisServer这 ...
- 深入理解vue 修饰符sync【 vue sync修饰符示例】
在说vue 修饰符sync前,我们先看下官方文档:vue .sync 修饰符,里面说vue .sync 修饰符以前存在于vue1.0版本里,但是在在 2.0 中移除了 .sync .但是在 2.0 发 ...
- pdf.js 预览文件中文内容丢失
问题: 在.netcore中使用pdf.js,pdf中有部分中文无法显示 在浏览器控制台发现有报错 发现在pdf.view.js中url路径异常,没有指向cmaps文件,于是调整了正确的相对路径 再次 ...
- vue-cli4 vue-config.js配置及其备注
// vue.config.js const path = require('path'); const CompressionWebpackPlugin = require("compre ...
- Oracle 存储过程使用总结
参考 https://blog.csdn.net/weixin_41968788/article/details/83659164/ 创建 注意:一定不要漏掉了语句末尾的分号 DBMS_OUTPUT. ...
- mybatis混淆概念
1.resultMap与resultType <mapper namespace="com.dao.FilmMapper"> <resultMap id=&quo ...
- C# 有关List<T>的Contains与Equals方法
[以下内容仅为本人在学习中的所感所想,本人水平有限目前尚处学习阶段,如有错误及不妥之处还请各位大佬指正,请谅解,谢谢!] !!!观前提醒!!! [本文内容可能较为复杂,虽然我已经以较为清晰的方式展 ...
- 【已解决】vscode窗口控制台闪现(不用更改原代码)
打开launch.json 将"type": "cppdbg"改为"type": "cppvsdbg" 会出现密钥ext ...
- 团队Arpha4
队名:观光队 组长博客 作业博客 组员实践情况 王耀鑫 **过去两天完成了哪些任务 ** 文字/口头描述 完成服务器连接数据库部分代码 展示GitHub当日代码/文档签入记录 接下来的计划 服务器网络 ...
- 老生常谈系列之Aop--CGLIB动态代理的底层实现原理
老生常谈系列之Aop--CGLIB动态代理的底层实现原理 前言 上一篇老生常谈系列之Aop--JDK动态代理的底层实现原理简单讲解了JDK动态代理的实现,动态代理常用实现里面的双子星还有另一位--CG ...