Java 流处理之收集器
Java 流(Stream)处理操作完成之后,我们可以收集这个流中的元素,使之汇聚成一个最终结果。这个结果可以是一个对象,也可以是一个集合,甚至可以是一个基本类型数据。
以记录 Record 为例:
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Record {
private String col1;
private String col2;
private int col3;
}
记录 Record 包含三个属性:列1(col1)、列2(col2)和 列3(col3)。
创建四个记录实例:
Record r1 = new Record("a", "1", 1);
Record r2 = new Record("a", "2", 2);
Record r3 = new Record("b", "3", 3);
Record r4 = new Record("c", "4", 4);
添加到列表:
List<Record> records = new ArrayList<>();
records.add(r1);
records.add(r2);
records.add(r3);
records.add(r4);
收集所有记录的 列1 值,以列表形式存储结果
List<String> col1List = records.stream()
.map(Record::getCol1)
.collect(Collectors.toList());
log.info("col1List: {}", Json.toJson(col1List));
输出结果:
col1List: ["a","a","b","c"]
收集所有记录的 列1 值,且去重,以集合形式存储
Set<String> col1Set = records.stream()
.map(Record::getCol1)
.collect(Collectors.toSet());
log.info("col1Set: {}", Json.toJson(col1Set));
输出结果:
col1Set: ["a","b","c"]
收集记录的 列2 值和 列3 值的对应关系,以字典形式存储
Map<String, Integer> col2Map = records.stream()
.collect(Collectors.toMap(Record::getCol2, Record::getCol3));
log.info("col2Map: {}", Json.toJson(col2Map));
输出结果:
col2Map: {"1":1,"2":2,"3":3,"4":4}
记录的 列2 不能有重复值,否则会抛出 Duplicate key 异常。
收集所有记录中 列3 值最大的记录
Record max = records.stream()
.collect(Collectors.maxBy(Comparator.comparing(Record::getCol3)))
.orElse(null);
log.info("max: {}", Json.toJson(max));
输出结果:
max: {"col1":"c","col2":"4","col3":4}
收集所有记录中 列3 值的总和
int sum = records.stream()
.collect(Collectors.summingInt(Record::getCol3));
log.info("sum: {}", sum);
输出结果:
sum: 10
流的收集需要通过 Stream.collect() 方法完成,方法的参数是一个 Collector(收集器);收集结果时,需要根据收集结果的目标类型,传递特定的收集器实例,如上:
- Collectors.toList()
- Collectors.toSet()
- Collectors.toMap()
- Collectors.maxBy()
- Collectors.summingInt()
Collectors(java.util.stream.Collectors) 是一个工具类,内置若干收集器,我们可以通过调用不同的方法快速获取相应的收集器实例。
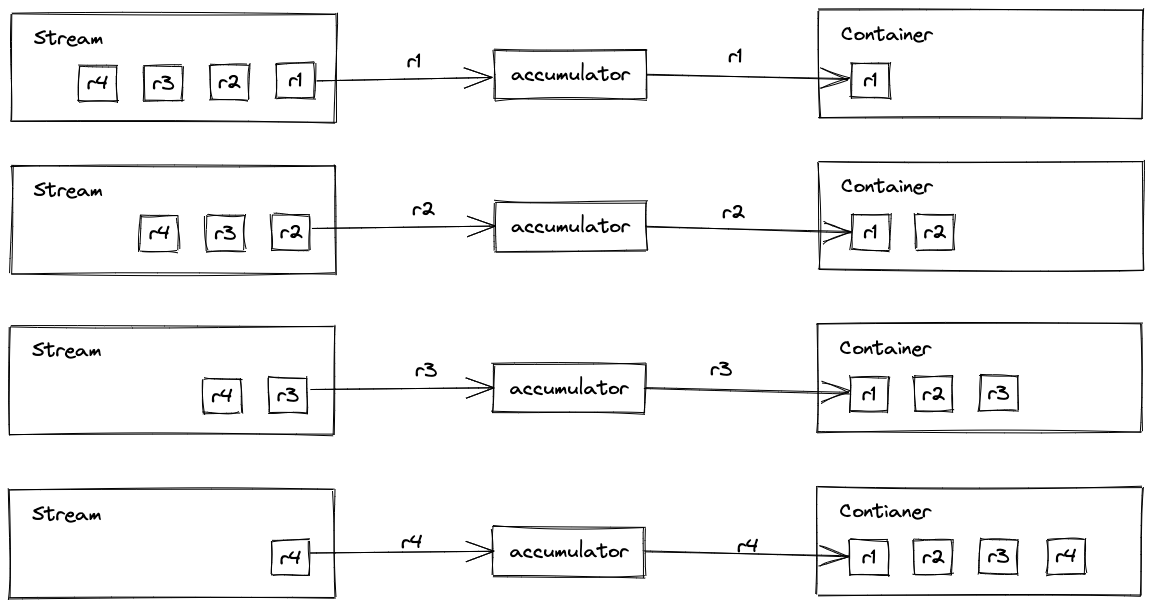
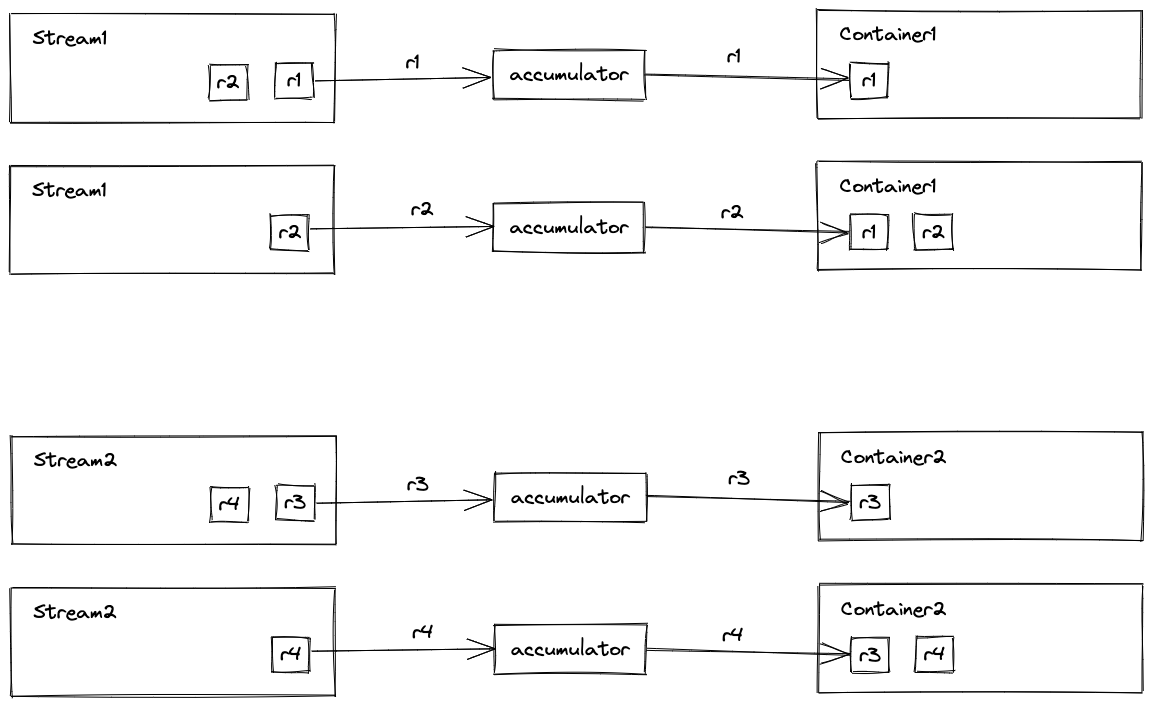
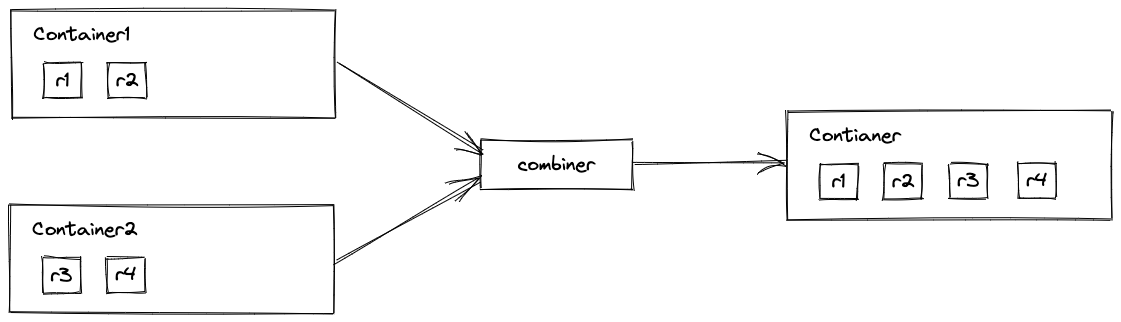
收集器(java.util.stream.Collector)本质是一个 接口,包含以下五个方法:


Java 流处理之收集器的更多相关文章
- JAVA流式布局管理器--JAVA基础
JAVA流式布局管理器的使用: FlowLayoutDeme.java: import java.awt.*;import javax.swing.*;public class FlowLayoutD ...
- JAVA 流式布局管理器
//流式布局管理器 import java.awt.*; import javax.swing.*; public class Jiemian2 extends JFrame{ //定义组件 JBut ...
- 深入理解Java虚拟机03--垃圾收集器与内存分配策略
一.概述 哪些内存需要回收? 什么时候回收? 如何回收? 二.对象已死吗 1.引用计数算法 定义:给对象添加一个引用计数器,当增加一个引用时,加1,当一个引用时,减1; 缺陷:当对象之间互相循环 ...
- [一] java8 函数式编程入门 什么是函数式编程 函数接口概念 流和收集器基本概念
本文是针对于java8引入函数式编程概念以及stream流相关的一些简单介绍 什么是函数式编程? java程序员第一反应可能会理解成类的成员方法一类的东西 此处并不是这个含义,更接近是数学上的 ...
- JAVA8给我带了什么——流的概念和收集器
到现在为止,笔者不敢给流下定义,从概念来讲他应该也是一种数据元素才是.可是在我们前面的代码例子中我们可以看到他更多的好像在表示他是一组处理数据的行为组合.这让笔者很难去理解他的定义.所以笔者不表态.各 ...
- Stream01 定义、迭代、操作、惰性求值、创建流、并行流、收集器、stream运行机制
1 Stream Stream 是 Java 8 提供的一系列对可迭代元素处理的优化方案,使用 Stream 可以大大减少代码量,提高代码的可读性并且使代码更易并行. 2 迭代 2.1 需求 随机创建 ...
- Java GC收集器配置说明
根据Java GC收集器具体分类,我们可以看出JVM根据需求不同提供了三种选择:串行收集器.并行收集器.并发收集器. 串行收集器只适用于小数据量的情况,我们主要了解一下并行收集器和并发收集器.默认情况 ...
- JAVA G1收集器 第11节
JAVA G1收集器 第11节 上两章我们讲了新生代和年老代的收集器,那么这一章的话我们就要讲一个收集范围涵盖整个堆的收集器——G1收集器. 先讲讲G1收集器的特点,他也是个多线程的收集器,能够充分利 ...
- JAVA 年老代收集器 第10节
JAVA 年老代收集器 第10节 上一章我们讲了新生代的收集器,那么这一章我们要讲的就是关于老年代的一些收集器.老年代的存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域 ...
随机推荐
- 图片64base转码与解码
场景一:图片转码成base64,传输,接收后解码成png等格式图片 import base64 # 读取图片,转换为base64编码格式 with open("F:\Archer\pictu ...
- JAVA语言的跨平台性和JDK,JRE与JVM
Java虚拟机--JVM ~JVM:java虚拟机简称JVM是运行所有java程序的假想计算机,是java程序的运行环境,是java最具有吸引力的特性之一,我们编写的java代码,都运行在JVM之上 ...
- vue this.getOptions is not a function
错误提示截图: 问题原因:是由于sass-loader引用的版本过低导致 解决方法:在package.json中增加以下配置后 "sass-loader": "^10&q ...
- Java开发学习(十二)----基于注解开发依赖注入
Spring为了使用注解简化开发,并没有提供构造函数注入.setter注入对应的注解,只提供了自动装配的注解实现. 1.环境准备 首先准备环境: 创建一个Maven项目 pom.xml添加Spring ...
- windows10:vscode下go语言的适配
ps:本篇依赖golang的sdk已经安装完成: url:https://www.cnblogs.com/mrwhite2020/p/16475731.html 一.下载vscode,选择wind ...
- Python图像处理丨三种实现图像形态学转化运算模式
摘要:本篇文章主要讲解Python调用OpenCV实现图像形态学转化,包括图像开运算.图像闭运算和梯度运算 本文分享自华为云社区<[Python图像处理] 九.形态学之图像开运算.闭运算.梯度运 ...
- ACWing95. 费解的开关
题解 这道题目有三个状态条件值得考虑: 每一个开关被按0次或者1次才有意义,如果超过1次,那么等同于按0或1次. 最终的结果与按的顺序无关 因为2,所以可以人为地规定比较合理的顺序. 现在以每一行为顺 ...
- Dubbo源码(三) - 服务导出(生产者)
前言 本文基于Dubbo2.6.x版本,中文注释版源码已上传github:xiaoguyu/dubbo 在了解了Dubbo SPI后,我们来了解下Dubbo服务导出的过程. Dubbo的配置是通过Du ...
- DelayQueue达到定时触发效果
DelayQueue的特点就是插入Queue中的数据可以按照自定义的delay时间进行排序.只有delay时间小于0的元素才能够被取出. 这样子,只要开启一个线程循环从DelayQueue中取值执行, ...
- 第十九天python3 json和messagepack
json的数据类型官网:https://www.json.org/ 值: 双引号内的字符串,数值,true和false,null,对象,数组:字符串: 双引号内的任意字符的组合,可以有专一字符:数值: ...