MaskRCNN:三大基础结构DeepMask、SharpMask、MultiPathNet
MaskXRCnn俨然成为一个现阶段最成功的图像检测分割网络,关于MaskXRCnn的介绍,需要从MaskRCNN看起。
当然一个煽情的介绍可见:何恺明团队推出Mask^X R-CNN,将实例分割扩展到3000类。
MaskRCnn取得的精细结果有三个主要技术构架:DeepMask、SharpMask、MultiPathNet。MaskRCNN与普通FNN的典型不同之处,重要两点为添加了SharpMask、MultiPathNet。
文章链接:FaceBook的物体检测新框架研究
Index
FAIR开发了一项用于发现和切割单张图像中每个物体的新技术,这一技术的主要驱动算法是DeepMask——一个新的图像分割框架,以及SharpMask——一个图像分割refine模型,二者结合使得FAIR的机器视觉系统能够感知并且精确的描绘一张图片中任何物体的轮廓。这一识别管道中的最后一步,研究院使用了一个特殊的卷积网络,称为MultiPathNet,为图片中检测到的物体添加标签。也就是说Facebook研究院的物体检测系统遵循一个三阶段的过程:(1)DeepMask生成初始物体mask(2)SharpMask优化这些mask(3)MutiPathNet识别每个mask框定的物体。
- DeepMask的技巧是把分割看成是一个海量的二进制分类问题
- 对一张图像中的每一个重叠的图像块:这个图像块包含一个物体吗?如果包含,那对于一个图像块中的每个像素:这个像素是图像块中心物体的一部分吗?用深度网络来回答每一个Yes/No的问题
- 上层功能以相当低的空间分辨率计算,这为mask预测带来一个问题:mask能捕捉一个物体大致外形,但不能准确捕捉物体边界。
- SharpMask优化DeepMask的输出,产生具有更高保真度的能精确框定物体边界的mask
- 在DeepMask预测前向通过网络时,SharpMask反转信息在深度网络的流向,并通过使用progressively earlier layers的特性来优化DeepMask做的预测。
- 要捕捉物体外形,你必须高度理解你正在看的是什么(DeepMask);但是要准确框出边界,你需要使用低层次的特性一直到像素级(SharpMask)
- DeepMask不知道具体对象类型,尽管可以框定但不能区分物体;以及没有选择性,会为不是很有趣的图像区域生成mask
- 训练一个单独的深度网络来对每一个DeepMask产生的mask的物体类型进行分类(包括“无”),采用R-CNN
- 改进是使用DeepMask作为R-CNN的第一阶段。
- 对于RCNN的第二阶段,使用一个专门的网络架构来对每一个mask进行分类,也就是MultiPathNet,允许信息以多种路径通过网络,从而使其能够在多种图像尺寸和图像背景中挖掘信息。
- MultiPathNet目的是提高物体检测性能,包括定位的精确度和解决一些尺度、遮挡、集群的问题。网络的起点是Fast R-CNN。
- 基本上,MultiPathNet就是把Fast
R-CNN与DeepMask/SharpMask一起使用,但是做了一些特殊的改造,例如:skip connections、foveal regions和integral loss function。
- 基本上,MultiPathNet就是把Fast
请继续参考原文...............
MultiPathNet
A MultiPath Network for Object Detection
- intro: BMVC 2016. Facebook AI Research (FAIR)
- arxiv: http://arxiv.org/abs/1604.02135
- github: https://github.com/facebookresearch/multipathnet
原文链接: ******A MultiPath Network for Object Detection-分割网络
CNN一般完成对框的检测,而MaskRCNN则识别Mask。
有了DeepMask输出的粗略分割mask,经过SharpMask refine边缘,接下来就要靠MultiPathNet来对mask中的物体进行识别分类了。MultiPathNet目的是提高物体检测性能,包括定位的精确度和解决一些尺度、遮挡、集群的问题。网络的起点是Fast R-CNN,基本上,MultiPathNet就是把Fast R-CNN与DeepMask/SharpMask一起使用,但是做了一些特殊的改造,例如:skip
connections、foveal regions和integral loss function。
1.背景工作
显然自从Fast R-CNN出现以来的object detector基本都是将它作为起点,进行一些改造,我们先来总结一下这些改造,以便理解本文的想法。Context核心思想就是利用物体周围的环境信息,比如有人在每个物体周围crop了10个contextual区域辅助检测。本文就是借鉴这种做法不过只用了4个contextual区域,涉及特殊的结构。
Skip connections
Classifers
大家都知道现在基本上是CNN结构的天下啦。。。本文用的是VGG-D,如果和何凯明的ResNet结合效果应该会更好哒。
2.网络结构
先上整个结构图:
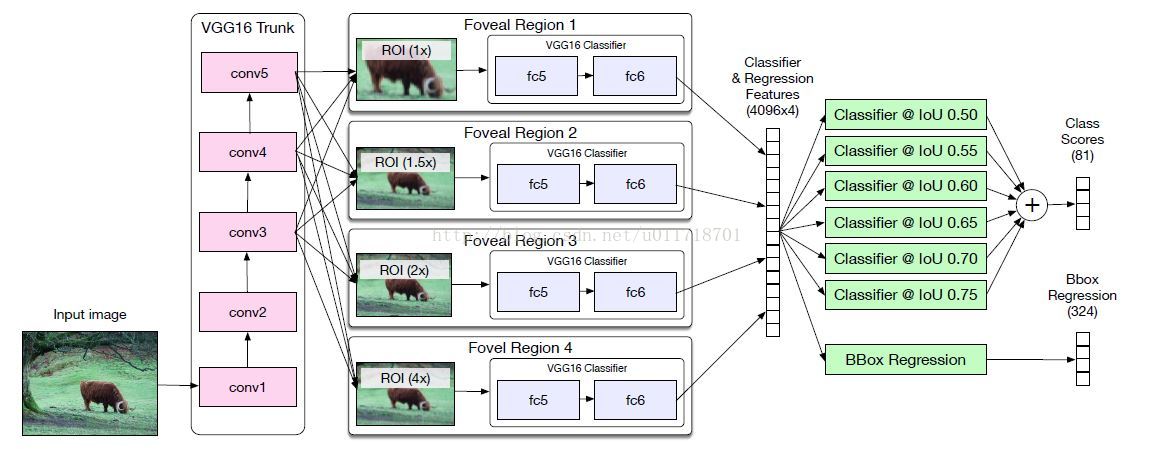
Foveal regions
Skip connections
- Integral Loss
loss代替了原来Fast-RCNN的分类loss:
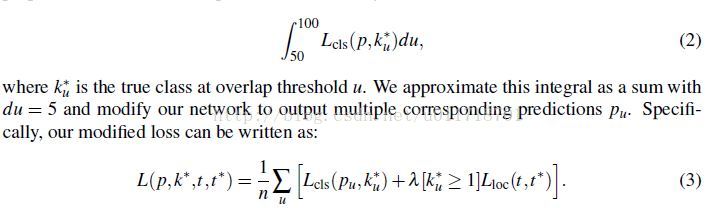
至此,Mask识别完成。
参考:
P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to segmentobject candidates. In NIPS, 2015. 2, 3[33] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P.
P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P . Doll´ar. Learningto refine object segments. In ECCV, 2016. 2, 3
MaskRCNN:三大基础结构DeepMask、SharpMask、MultiPathNet的更多相关文章
- Analyzing The Papers Behind Facebook's Computer Vision Approach
Analyzing The Papers Behind Facebook's Computer Vision Approach Introduction You know that company c ...
- 理解DeepBox算法
理解DeepBox算法 基本情况 论文发表在ICCV2015,作者是Berkeley的博士生Weicheng Kuo: @inproceedings{KuoICCV15DeepBox, Author ...
- Go 面向对象三大特性
#### Go 中面向对象的三大特性上周因为有一些事情,停更了; 停更的这段时间,花了点时间做了一个小项目(https://github.com/yioMe/node_wx_alipay_person ...
- Fis3的前端工程化之路[三大特性篇之声明依赖]
Fis3版本:v3.4.22 Fis3的三大特性 资源定位:获取任何开发中所使用资源的线上路径 内容嵌入:把一个文件的内容(文本)或者base64编码(图片)嵌入到另一个文件中 依赖声明:在一个文本文 ...
- Fis3的前端工程化之路[三大特性篇之资源定位]
Fis3版本:v3.4.22 Fis3的三大特性 资源定位:获取任何开发中所使用资源的线上路径 内容嵌入:把一个文件的内容(文本)或者base64编码(图片)嵌入到另一个文件中 依赖声明:在一个文本文 ...
- Fis3的前端工程化之路[三大特性篇之内容嵌入]
Fis3版本:v3.4.22 Fis3的三大特性 资源定位:获取任何开发中所使用资源的线上路径 内容嵌入:把一个文件的内容(文本)或者base64编码(图片)嵌入到另一个文件中 依赖声明:在一个文本文 ...
- [C#] async 的三大返回类型
async 的三大返回类型 序 博主简单数了下自己发布过的异步文章,已经断断续续 8 篇了,这次我想以 async 的返回类型为例,单独谈谈. 异步方法具有三个可让开发人员选择的返回类型:Task&l ...
- atitit.管理学三大定律:彼得原理、墨菲定律、帕金森定律
atitit.管理学三大定律:彼得原理.墨菲定律.帕金森定律 彼得原理(The Peter Principle) 1 彼得原理解决方案1 帕金森定律 2 如何理解墨菲定律2 彼得原理(The Pete ...
- SqlServer之数据库三大范式
分析: 数据库设计应遵循三大范式分别为: 第一范式:确保表中每列的原子性(不可拆分): 第二范式:确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依 ...
随机推荐
- Redis学习笔记3-Redis5个可运行程序命令的使用
在redis安装文章中,说到安装好redis后,在/usr/local/bin下有5个关于redis的可运行程序.以下关于这5个可运行程序命令的具体说明. redis-server Redisserv ...
- Ubuntu安装JDK及环境变量配置(sun java)
捣鼓了尽一天的时间,终于把sun的java安装上了,不是openjava了,网上试了好多的方法好多都是不可以的,所以当自己成功后就立马把方法贴出来,以方便后来者少走弯路,此文的方法绝对可行! 这里先简 ...
- 使用qemu
1 获取qemu启动linux kernel的log qemu-system-x86_64 -nographic -kernel xxx -initrd xxx -append "conso ...
- Selenium Webdriver弹出框 微博分享的内容控制与结果生成
browser.window_handles for i in ugc_url_l: js = 'window.location.href="{}"'.format(i) brow ...
- 网关 192.168.2.1 114.114.114.114 dns查询
在浏览器输入域名 分析抓包数据 分析 ip 192.168.3.123 网关192.168.2.1
- 在js中取选中的radio值
在js中取选中的radio值 <input type="radio" name="address" value="0" /> & ...
- HttpClient-02连接管理
2.1.持久连接 两个主机建立连接的过程是很复杂的一个过程,涉及到多个数据包的交换,并且也很耗时间.Http连接需要的三次握手开销很大,这一开销对于比较小的http消息来说更大.但是如果我们直接使用已 ...
- [noip模拟赛]跑跑步
https://www.zybuluo.com/ysner/note/1298652 题面 小胡同学是个热爱运动的好孩子. 每天晚上,小胡都会去操场上跑步,学校的操场可以看成一个由\(n\)个格子排成 ...
- Maximum Gap 典型线性排序
https://leetcode.com/problems/maximum-gap/ Given an unsorted array, find the maximum difference betw ...
- Ruby和Swift的Range
意义 Swift Ruby [1, 2, 3, 4, 5] 1...5 1..5 [1, 2, 3, 4] 1..<5 1...5 ...