Spark 大数据文本统计
此程序功能:
1.完成对10.4G.csv文件各个元素频率的统计
2.获得最大的统计个数
3.对获取到的统计个数进行降序排列
4.对各个元素出现次数频率的统计
import org.apache.spark.{SparkConf, SparkContext}
/**
*/
object 大数据统计 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("大数据").setMaster("local[4]")
val sc=new SparkContext(conf)
// val text= sc.textFile("/home/soyo/桌面/shell编程测试/1.txt")
val text= sc.textFile("/home/soyo/下载/Hadoop+Spark+Hbase/all2.csv")
//text.foreach(println)
val wordcount= text.flatMap(line=>line.split(",")).map(word=>(word,))
.reduceByKey((a,b)=>a+b)
wordcount.collect().foreach(println)
// wordcount.saveAsTextFile("/home/soyo/桌面/shell编程测试/1-1-1.txt")
println("单独文件中各个数的统计个数")
// wordcount.map(_._2).foreach(println)
println("获取统计的最大数")
// wordcount.map(_._2).saveAsTextFile("/home/soyo/下载/Hadoop+Spark+Hbase/77.txt")
println(wordcount.map(_._2).max())
println("对获取到的数降序排列")
wordcount.map(_._2).sortBy(x=>x,false).foreach(println) //false:降序 true:升序
println("转变为key-value形式")
wordcount.map(_._2).map(num=>(num,)).reduceByKey((a,b)=>a+b).foreach(println)
println("对key-value按key再排序,获得结果表示:假设文件中'soyo5'总共出现10次,可文件'soyo1'也出现10次,最后整个排序获得的是(10,2)10次的共出现2次")
wordcount.map(_._2).map(num=>(num,)).reduceByKey((a,b)=>a+b).sortByKey().foreach(println)
}
}
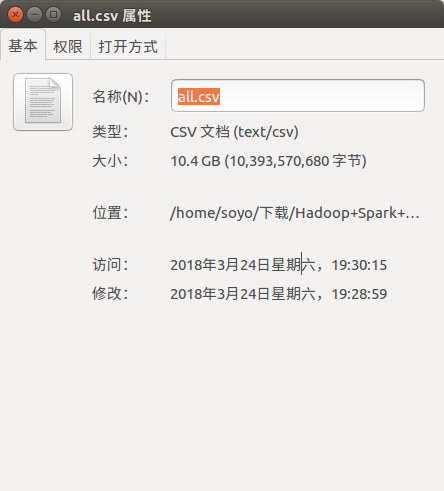
数据内容:
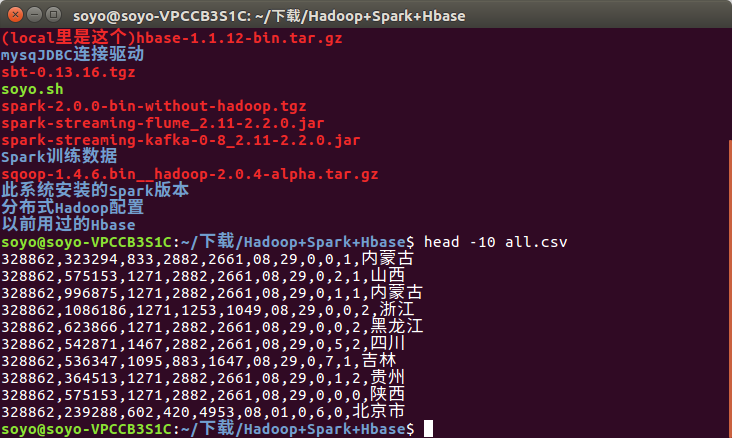
Spark 保存的文件是这样的:
这里可以用一个脚本将这么多的文件进行合并:
#!/bin/bash
cat * >>soyoo.txt
结果太多只写一个:
获取统计的最大数
294887496 (数据中有一个元素出现了这么多次)
Spark 大数据文本统计的更多相关文章
- C#大数据文本高效去重
C#大数据文本高效去重 转载请注明出处 http://www.cnblogs.com/Huerye/ TextReader reader = File.OpenText(@"C:\Users ...
- SQL大数据操作统计
SQL大数据操作统计 1:select count(*) from table的区别SELECT object_name(id) as TableName,indid,rows,rowcnt FROM ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- 教你如何成为Spark大数据高手?
教你如何成为Spark大数据高手? Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么如何成为Spark大数据高手?下面就来个深度教程. Spark ...
- Spark大数据针对性问题。
1.海量日志数据,提取出某日访问百度次数最多的那个IP. 解决方案:首先是将这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^32个IP.同样可以采 ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- Spark大数据的学习历程
Spark主要的编程语言是Scala,选择Scala是因为它的简洁性(Scala可以很方便在交互式下使用)和性能(JVM上的静态强类型语言).Spark支持Java编程,但对于使用Java就没有了Sp ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 小试牛刀ElasticSearch大数据聚合统计
ElasticSearch相信有不少朋友都了解,即使没有了解过它那相信对ELK也有所认识E即是ElasticSearch.ElasticSearch最开始更多用于检索,作为一搜索的集群产品简单易用绝对 ...
随机推荐
- mysql与时间有关的查询
date(str)函数可以返回str中形如"1997-05-26"格式的日期,str要是合法的日期的表达式,如2008-08-08 22:20:46 时间是可以比较大小的,例如: ...
- SA模板
#include<cstdio> #include<algorithm> #include<cstring> using namespace std; ; char ...
- codeforces 1041 c 乱搞
#include <bits/stdc++.h> using namespace std; struct po { int val; int id; }; po a[]; vector&l ...
- HDU 6390
GuGuFishtion Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tota ...
- HTML5 <template>标签元素简介
一.HTML5 template元素初面 <template>元素,基本上可以确定是2013年才出现的.干嘛用的呢,顾名思意,就是用来声明是“模板元素”. 目前,我们在HTML中嵌入模板H ...
- php 获取TZ时间格式
php将时间格式化成T Z的方法 gmdate("c") 这个函数的用法,学会了吧!!! <?php var_dump(gmdate("c")); ini ...
- Spring4.0MVC学习资料,注解自己主动扫描bean,自己主动注入bean(二)
Spring4.0的新特性我们在上一章已经介绍过了. 包含它对jdk8的支持,Groovy Bean Definition DSL的支持.核心容器功能的改进,Web开发改进.測试框架改进等等.这张我们 ...
- Win7 本地打印后台处理程序服务没有运 怎么办
找到名为Print Spooler的服务,启动类型改为自动,服务状态改为启动即可.
- 深入浅出Redis(二)高级特性:事务
第一篇中介绍了Redis是一个强大的键-值仓储,支持五种灵活的数据结构.其实,Redis还支持其他的一些高级特性:事务.公布与订阅.管道.脚本等,本篇我们来看一下事务. 前一篇中我们提到,在Redis ...
- Android 项目导入常见错误
1.SDK版本号不正确应,你能够打开你项目中的project.properties文件,改动target=android-18(我这是18) ,将18改 为14(其它都能够),再改回18会又一次载入. ...