机器学习--DIY笔记与感悟--②决策树(1)
在完成了K临近之后,今天我们开始下一个算法--->决策树算法。
一、决策树基础知识
如果突然问你"有一个陌生人叫X,Ta今天需要带伞吗?", 你一定会觉得这个问题就像告诉你"两千米外有一个超市,问超市里面有多少卷卫生纸"一样突兀. 可能几秒钟之后你会说"这要依情况而定, 如果今天烈日炎炎并且X是一个皮肤白皙的中国姑娘,或者外面下着大雨并且X是一个不得不去步行上班的屌丝码农, 那么Ta今天需要带伞, 否则不要."
当谈及这个看似无聊的问题的时候我们在谈什么?恩,在谈方法. 我们经常会遇到简单但又困难的抉择. 说简单,是因为候选方案简单而且清晰. 例如,要不要出国留学,要不要辞职创业,要不要投资黄金等等. 但是这些看似简单的选项背后却是困难的抉择. 面对这些困难的抉择, 一开始, 很可能不知所措. 值得庆幸的是, 很多时候, 这些看似不可能解决的问题, 最终可以被化解成一连串越来越简单的问题, 然后解决掉. 这个方法可以粗俗总结为: "如果这样这样这样, 那么选择A; 如果那样那样那样, 那么选择B", 当然这种方法有一个更加简洁形象的名字--决策树(Decision Tree)。
现在大家应该对决策树应该有了一个大致的了解。简单来说,决策树就是内心的一个决策过程,既:如果我要达成某个结果,那么我需要先怎么样,然后怎么样,满足什么样的条件balabala.....
举一个通俗的栗子,各位立志于脱单的单身男女在找对象的时候就已经完完全全使用了决策树的思想。假设一位母亲在给女儿介绍对象时,有这么一段对话:
母亲:给你介绍个对象。
女儿:年纪多大了?
母亲:。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
画成树状图即为:
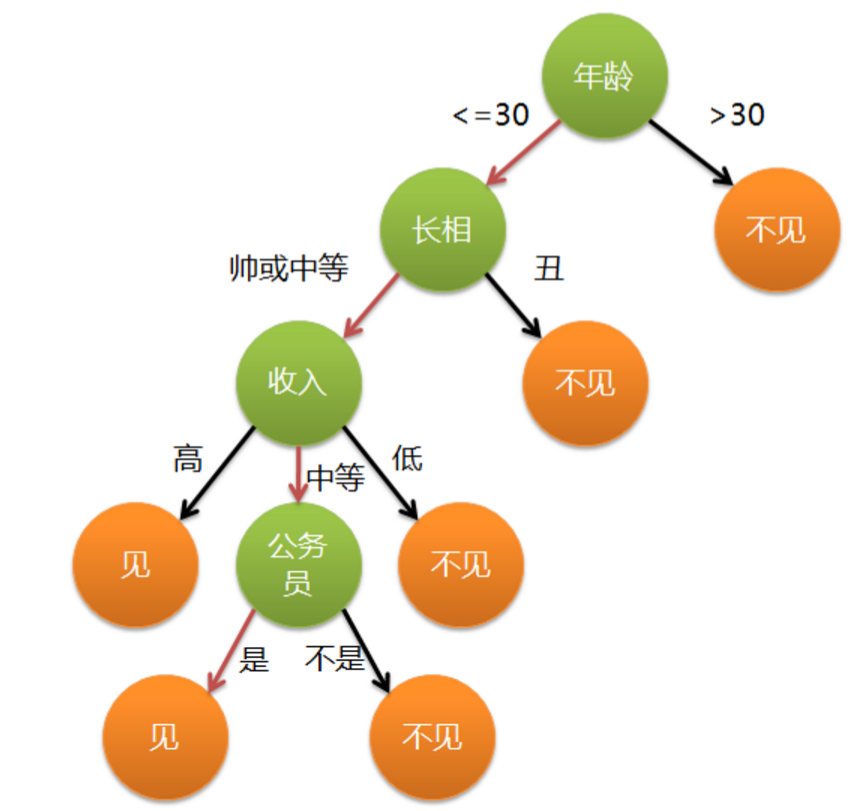
上图则为一个简单的决策树。
二、决策树理论--信息论
大家不要被高大上的信息论给吓到了,决策树算法中涉及信息论的知识很少,也就是几个概念。所以了解了对应的概念就没有问题了。
这里我准备使用一个例子来讲述相应理论。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别(是否发放贷款) |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
上面我加载了一张数据表格。这张表格的内容为贷款申请样本数据表。也就是说这张表格中每一行的结果均为是否成功申请到贷款。而能否成功申请到贷款取决于一些神秘的力量。
神秘的力量是什么呢?这个力量与四个特征有某些神奇的关系(这个关系就是我们要找的决策树)--申请人的年龄、是否有工作、是否有房子、信贷情况。
之后我们就要使用信息论中--熵的概念来提炼出哪一个特征对结果影响更大。
这里引入熵的概念:
通常,一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之就大。
通俗来说,在这个例子中,计算“是否发放贷款”这个信息的熵(这里表示为H),得到的H值的大小表示为该结果的不确定性。而H的值越大,不确定性越大。
对应的计算公式为: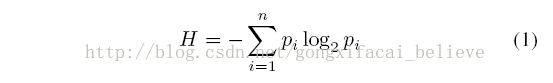
根据此公式计算经验熵H(D),分析贷款申请样本数据表中的数据。最终分类结果只有两类,即放贷和不放贷。根据表中的数据统计可知,在15个数据中,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集D的经验熵H(D)为:

经过计算可知,数据集D的经验熵H(D)的值为0.971。不确定度也就是为0.971Z这么大(这里不是概率)
三、编写代码计算熵
在编写代码之前,我们先对数据集进行属性标注。
- 年龄:0代表青年,1代表中年,2代表老年;
- 有工作:0代表否,1代表是;
- 有自己的房子:0代表否,1代表是;
- 信贷情况:0代表一般,1代表好,2代表非常好;
- 类别(是否给贷款):no代表否,yes代表是。
这样上述表格就可以规范化为
dataSet = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
这里放上代码:
#coding:utf-8 """基于信息量的决策树算法(Decision Tree),计算当前数据的香农熵""" from math import log def createData():
data = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']] labels = ['年龄', '有工作', '有房子', '信贷情况']
#分类标签
return data,labels def calcu_Entropy(data):
dataCount = len(data)
#计算data的个数
labelCounts = {}
#用来计算每个标签出现的次数
for everVec in data:
clac_label = everVec[-1]
#取出所需计算的标签(-1代表倒数第一列的值)
if clac_label not in labelCounts.keys():
labelCounts[clac_label] = 0
#.keys()函数为:返回当前字典里的键
#上述判断是为了查看当前的字典里是否有此键值,若没有将此键的值更新为0,为了方便以后计算数量
labelCounts[clac_label] += 1
#当前的键每出现一次,键值就加1(用来计算出现的次数)
shannonEn = 0.0
#初始化香农熵
for i in labelCounts:
prob = float(labelCounts[i]) / float(dataCount)
#prob为每一个键出现的概率
shannonEn -= prob * log(prob, 2)
#计算香农熵,H = -P1 * log(2,p1) - P2 * log(2,p2)....- Pn * log(2,pn)
return shannonEn if __name__ == '__main__':
data,labels = createData()
print calcu_Entropy(data)
经过计算,得到“是否发放贷款”的香农熵为:

四、决策树理论--互信息
互信息(Mutual Information)是信息论里一种有用的信息度量,它可以简单的形容为一个随机变量由于已知另一个随机变量而减少的不肯定性。
它的公式为: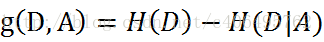
而H(D|A)为条件熵,既在已知A的前提下D的熵。而H(D) - H(D|A)则可以理解为什么都不知道的前提下求得的D的熵 - 已知A的前提下D的熵。又由于熵表示不确定程度,所以这个公式表示了不确定程度的减少,既已知A对D的不确定程度的减少量。
而条件熵的公式为:
这里放入一个链接,如果不是很明白这个概念的同学可以跳转学习下。
http://blog.csdn.net/xwd18280820053/article/details/70739368
这下是不是好理解了一些呢?对于例子来说,看下年龄这一列的数据,也就是特征A1,一共有三个类别,分别是:青年、中年和老年。
我们只看年龄是青年的数据,年龄是青年的数据一共有5个,所以年龄是青年的数据在训练数据集出现的概率是十五分之五,也就是三分之一。
同理,年龄是中年和老年的数据在训练数据集出现的概率也都是三分之一。
现在我们只看年龄是青年的数据的最终得到贷款的概率为五分之二,因为在五个数据中,只有两个数据显示拿到了最终的贷款,同理,年龄是中年和老年的数据最终得到贷款的概率分别为五分之三、五分之四。所以计算年龄的信息增益,过程如下:
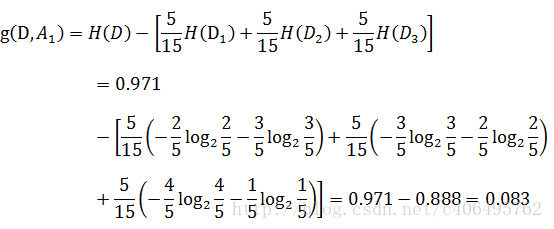
同理,计算其余特征的信息增益g(D,A2)、g(D,A3)和g(D,A4)。分别为:
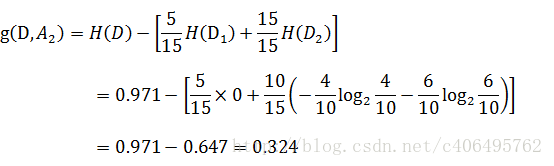
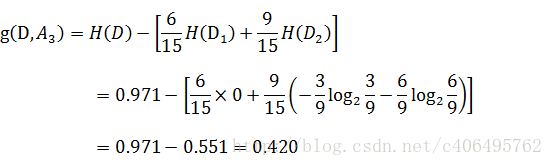
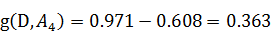
得到A3的互信息最大,既在知道A3的条件下对我们得到结果最有帮助(减少可能性最大)。
五、计算互信息量的代码
这里仍然使用了python 2.7.10版本。
from math import log def createData():
data = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']] labels = ['年龄', '有工作', '有房子', '信贷情况']
#分类标签
return data,labels def calcu_Entropy(data):
dataCount = len(data)
#计算data的个数
labelCounts = {}
#用来计算每个标签出现的次数
for everVec in data:
clac_label = everVec[-1]
#取出所需计算的标签
if clac_label not in labelCounts.keys():
labelCounts[clac_label] = 0
#.keys()函数为:返回当前字典里的键
#上述判断是为了查看当前的字典里是否有此键值,若没有将此键的值更新为0,为了方便以后计算数量
labelCounts[clac_label] += 1
#当前的键每出现一次,键值就加1(用来计算出现的次数)
shannonEn = 0.0
#初始化香农熵
for i in labelCounts:
prob = float(labelCounts[i]) / float(dataCount)
#prob为每一个键出现的概率
shannonEn -= prob * log(prob, 2)
#计算香农熵,H = -P1 * log(2,p1) - P2 * log(2,p2)....- Pn * log(2,pn)
return shannonEn def choose_column_in_data(data,column,value):
#该函数意义为选择当前数据集中以某一列(例如选择年龄、或者选择是否有房子等)作为依据的数据集合
#其中data是所有数据集,column是所选择列的编号,value为所需要选定的值(例如我需要年龄为青年的人,那么value就为:青年)
dataConsequence = []
for everVec in data:
if everVec[column] == value:
#对每一条数据进行处理,若该数据对应位置的值为value,则进行下一步
mid = everVec[:column]
mid.extend(everVec[column+1:])
dataConsequence.append(mid)
return dataConsequence def Choose_Best_Mutua_Information(data):
#此函数含义为选择当前数据中使熵增最大的特征
bestFeature = -1
#预设最优解
bestFeatureValue = -1000.0
#预设最大增益
Featurenum = len(data[0]) - 1
#提取单个数据的特征数量
baseEntropy = calcu_Entropy(data)
#计算总的熵
for i in range(Featurenum):
midList = [example[i] for example in data]
#中间变量暂存所有个体的第i个特征的数据(既将表格竖着存入数组)
columnType = set(midList)
#打印出每一列特征所包含的数据有哪些类型,例如[0,0,1,1,2,2] -> [0,1,2]
conditionsEnt = 0.0
#条件熵
for value in columnType:
#取当前特征下每一个类型出来
currentData = choose_column_in_data(data,i,value)
#既在data中,选择第i列中值为value的所有数据并组合到一起
prob = len(currentData) / float(len(data))
#类似于那个例子中的 5/15 * 2/5
conditionsEnt += prob * calcu_Entropy(currentData)
#H = -P(a) * P(D|a) * log(2,P(D|a))
increaseEntropy = baseEntropy - conditionsEnt
#得出:已知当前特征(i)时,得到的熵增益
print "第%d个特征熵的增益为:%.3f" %(i,increaseEntropy)
if increaseEntropy > bestFeatureValue:
bestFeatureValue = increaseEntropy
bestFeature = i
return bestFeature data,labels = createData()
final = Choose_Best_Mutua_Information(data)
print "当前数据中熵增益最大的特征的编号为: 编号",final,
得到了结果为:
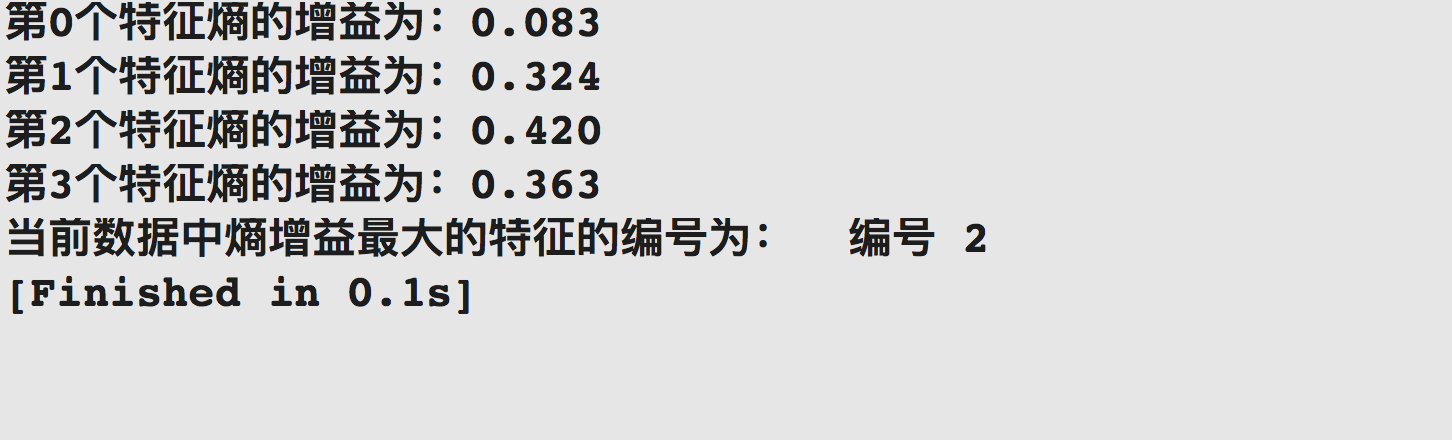
跟我们计算的值相同。
下一篇我将继续讲解如何构建具体的决策树。
机器学习--DIY笔记与感悟--②决策树(1)的更多相关文章
- 机器学习--DIY笔记与感悟--①K-临近算法
##“计算机出身要紧跟潮流” 机器学习作为如今发展的趋势需要被我们所掌握.而今我也需要开始learn机器学习,并将之后的所作所想记录在此. 今天我开始第一课--K临近算法. 一.k-临近的基础概念理解 ...
- 机器学习--DIY笔记与感悟--①K-临近算法(2)
上一篇博客我手动写了KNN算法,并且之后用手写的算法预测了约会的成功率. 而今天,我在大神博客的指导下调用sklearn这个库来预测图片的内容. 一.前期准备 由于我这里使用的是mac版本,而skle ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程
ng机器学习视频笔记(十六) --从图像处理谈机器学习项目流程 (转载请附上本文链接--linhxx) 一.概述 这里简单讨论图像处理的机器学习过程,主要讨论的是机器学习的项目流程.采用的业务示例是O ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- 机器学习&数据挖掘笔记_14(GMM-HMM语音识别简单理解)
为了对GMM-HMM在语音识别上的应用有个宏观认识,花了些时间读了下HTK(用htk完成简单的孤立词识别)的部分源码,对该算法总算有了点大概认识,达到了预期我想要的.不得不说,网络上关于语音识别的通俗 ...
- [自娱自乐] 4、超声波测距模块DIY笔记(四)——终结篇·基于C#上位机软件开发
前言 上一节我们已经基本上把超声波硬件的发射和接收模块全部做好了,接下来我们着手开发一个软硬结合的基于C#的平面定位软件! 目录 一.整体思路 二.效果提前展示 2-1.软件部分展示 2-2.硬件部分 ...
随机推荐
- BeagleBone Black Industrial 杂谈
前言 原创文章,转载引用务必注明链接.水平有限一己拙见,欢迎指正. 本文使用markdown写成,为获得更好的阅读体验,推荐访问我的博客原文: 初版BeagleBone Black(Rev A4) ...
- 杭电1708Fibonacci String
Fibonacci String Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- iOS开发之UITabBarController和UICollectionView的使用
这一篇要记录的是iOS开发中UITabBarController控件和UICollectionView控件的使用.APP跑起来之后的效果例如以下图: watermark/2/text/aHR0cDov ...
- C#中Queue<T>类的使用以及部分方法的源代码分析
Queue<T>类 表示对象的先进先出集合. 队列在按接收顺序存储消息方面很实用,以便于进行顺序处理. 存储在 Queue,<T> 中的对象在一端插入,从还有一端移除. Que ...
- windows 怎么验证域名是否开启了 https
由于 ping 是针对 IP 层的,只能检查当前系统网络与网络中某个IP,某个域名是否连通. 当我们需要验证域名是否开启了 https时,用如下方法: 1. 下载tcping.exe,放到本机C盘根目 ...
- Java经常使用类及其经常用法
1.ArrayList java.util.ArrayList<E> add(E e) //插入尾部 add(int index, E element) remove(int index) ...
- 《Java虚拟机原理图解》4.JVM机器指令集
0. 前言 Java虚拟机和真实的计算机一样,执行的都是二进制的机器码:而我们将.java 源码编译成.class 文件,class文件便是Java虚拟机可以认识的二进制机器码,Java可以识别cla ...
- Hdu 4274 Spy's Work
Spy's Work Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- OpenStack源码系列---nova-api
OpenStack源码实际上是比较规范的,但是对刚刚接触到源代码的人来说,却感觉有点混乱.我刚开始的时候也常常搞乱,比如service.Service类继承自openstack.common.serv ...
- linux输入子系统(5) - 学习框架
注:本系列转自: http://www.ourunix.org/post/290.html input子系统学习系列文章,是我在实际开发过程中遇到也是必须啃下去的第一个Linux驱动,所以有必要记载下 ...