PyTorch中的backward [转]
转自:https://sherlockliao.github.io/2017/07/10/backward/
backward只能被应用在一个标量上,也就是一个一维tensor,或者传入跟变量相关的梯度。
特别注意Variable里面默认的参数requires_grad=False,所以这里我们要重新传入requires_grad=True让它成为一个叶子节点。
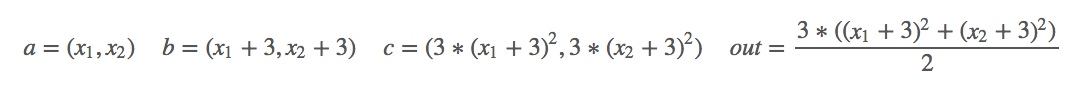
对其求偏导:

import torch as t
from torch.autograd import Variable as v # simple gradient
a = v(t.FloatTensor([2, 3]), requires_grad=True)
b = a + 3
c = b * b * 3
out = c.mean()
out.backward()
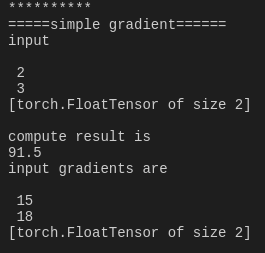
print('*'*10)
print('=====simple gradient======')
print('input')
print(a.data)
print('compute result is')
print(out.data[0])
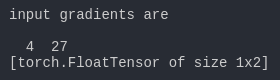
print('input gradients are')
print(a.grad.data)
下面研究一下如何能够对非标量的情况下使用backward。backward里传入的参数是每次求导的一个系数。
首先定义好输入m=(x1,x2)=(2,3),然后我们做的操作就是n=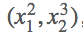 ,这样我们就定义好了一个向量输出,结果第一项只和x1有关,结果第二项只和x2有关,那么求解这个梯度,
,这样我们就定义好了一个向量输出,结果第一项只和x1有关,结果第二项只和x2有关,那么求解这个梯度,
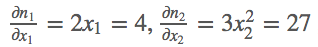
# backward on non-scalar output
m = v(t.FloatTensor([[2, 3]]), requires_grad=True)
n = v(t.zeros(1, 2))
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3
n.backward(t.FloatTensor([[1, 1]]))
print('*'*10)
print('=====non scalar output======')
print('input')
print(m.data)
print('input gradients are')
print(m.grad.data)
jacobian矩阵
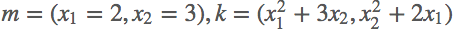
对其求导:
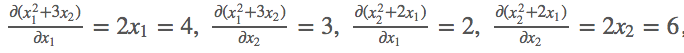
k.backward(parameters)接受的参数parameters必须要和k的大小一模一样,然后作为k的系数传回去,backward里传入的参数是每次求导的一个系数。
# jacobian
j = t.zeros(2 ,2)
k = v(t.zeros(1, 2))
m.grad.data.zero_()
k[0, 0] = m[0, 0] ** 2 + 3 * m[0 ,1]
k[0, 1] = m[0, 1] ** 2 + 2 * m[0, 0]
# [1, 0] dk0/dm0, dk1/dm0
k.backward(t.FloatTensor([[1, 0]]), retain_variables=True) # 需要两次反向求导
j[:, 0] = m.grad.data
m.grad.data.zero_()
# [0, 1] dk0/dm1, dk1/dm1
k.backward(t.FloatTensor([[0, 1]]))
j[:, 1] = m.grad.data
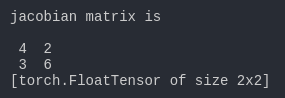
print('jacobian matrix is')
print(j)
我们要注意backward()里面另外的一个参数retain_variables=True,这个参数默认是False,也就是反向传播之后这个计算图的内存会被释放,这样就没办法进行第二次反向传播了,所以我们需要设置为True,因为这里我们需要进行两次反向传播求得jacobian矩阵。
PyTorch中的backward [转]的更多相关文章
- 关于Pytorch中autograd和backward的一些笔记
参考自<Pytorch autograd,backward详解>: 1 Tensor Pytorch中所有的计算其实都可以回归到Tensor上,所以有必要重新认识一下Tensor. 如果我 ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- pytorch 中的重要模块化接口nn.Module
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 对于自己 ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- pytorch中调用C进行扩展
pytorch中调用C进行扩展,使得某些功能在CPU上运行更快: 第一步:编写头文件 /* src/my_lib.h */ int my_lib_add_forward(THFloatTensor * ...
- 关于Pytorch中accuracy和loss的计算
这几天关于accuracy和loss的计算有一些疑惑,原来是自己还没有弄清楚. 给出实例 def train(train_loader, model, criteon, optimizer, epoc ...
- 【PyTorch】PyTorch中的梯度累加
PyTorch中的梯度累加 使用PyTorch实现梯度累加变相扩大batch PyTorch中在反向传播前为什么要手动将梯度清零? - Pascal的回答 - 知乎 https://www.zhihu ...
- PyTorch中的C++扩展
今天要聊聊用 PyTorch 进行 C++ 扩展. 在正式开始前,我们需要了解 PyTorch 如何自定义module.这其中,最常见的就是在 python 中继承torch.nn.Module,用 ...
- PyTorch中的Batch Normalization
Pytorch中的BatchNorm的API主要有: 1 torch.nn.BatchNorm1d(num_features, 2 3 eps=1e-05, 4 5 momentum=0.1, 6 7 ...
随机推荐
- jquery源码解析
//局部作用域,外部引用不到这个闭合函数里面的东西,这时候需要用提供的对外访问接口来访问里面的变量 (function(){ ; function $() { alert(a) } window.$ ...
- Webpack2 中的 NamedModulesPlugin 与 HashedModuleIdsPlugin
要讨论Webpack 2中新增的这两个plugin的功能,还要先从使用Webpack打包的项目的前端资源缓存方案说起. 通常在使用了Webpack的项目中我们会使用CommonsChunkPlugin ...
- HTTP笔记01-http相关的基础知识
这个系列文章是阅读<图解HTTP>后写下的笔记 当我们在浏览器输入url,点击回车后,浏览器显示我们需要的web页面,那么,这个界面是如何产生的? 根据浏览器地址中输入的url,浏览器从相 ...
- Python3学习笔记33-正则表达式
学习文章传送门 正则表达式是用来匹配字符串的.只要符合规则的字符串.就可以认为匹配了.否则,这个字符串不合法. \d:可以匹配一个数字 ‘00\d’可以匹配001不能匹配00A \w:可以匹配 ...
- 题解-USACO18DEC Balance Beam详细证明
(翻了翻其他的题解,觉得它们没讲清楚这个策略的正确性) Problem 洛谷5155 题意概要:给定一个长为\(n\)的序列,可以选择以\(\frac 12\)的概率进行左右移动,也可以结束并得到当前 ...
- centos6.9安装crontab
yum install vixie-cron crontabs //安装 chkconfig crond on //开机自启动 service crond start //启动 然后就是执行 cron ...
- nginx 403 forbidden
2018年3月9日14:11:59 总结一下: 1. 查看目录或者文件是否是可读可执行 2. 查看nginx配置的server -> location -> index指令, 看其列出的入 ...
- 分析Vue框架源码心得
1.在封装一个公用组件,比如button按钮,我们多个地方使用,不同类型的button调用不同的方法,我们就可以这样用 代码片段: <lin-button v-for="(item,i ...
- CF767C Garland--树形dp
今天无聊的我又来切树形dp了,貌似我与树形dp有仇似的. n个节点的树 第i个节点权值为 n<=10^6 −100<=ai<=100 问是否能够删除掉两条边,使得该树分成三个不为空 ...
- 分布式Dubbo快速入门
目录 Dubbo入门 背景 zookeeper安装 发布Dubbo服务 Dubbo Admin管理 消费Dubbo服务 抽取与依赖版本管理 Dubbo入门 Editor:SimpleWu Dubbo是 ...