PyTorch中的backward [转]
转自:https://sherlockliao.github.io/2017/07/10/backward/
backward只能被应用在一个标量上,也就是一个一维tensor,或者传入跟变量相关的梯度。
特别注意Variable里面默认的参数requires_grad=False,所以这里我们要重新传入requires_grad=True让它成为一个叶子节点。
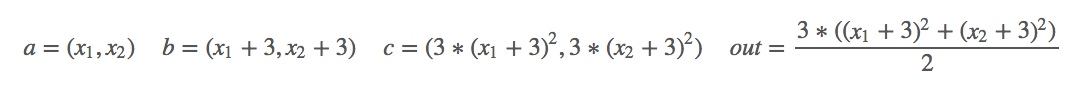
对其求偏导:

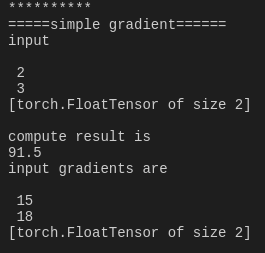
import torch as t
from torch.autograd import Variable as v # simple gradient
a = v(t.FloatTensor([2, 3]), requires_grad=True)
b = a + 3
c = b * b * 3
out = c.mean()
out.backward()
print('*'*10)
print('=====simple gradient======')
print('input')
print(a.data)
print('compute result is')
print(out.data[0])
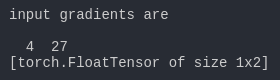
print('input gradients are')
print(a.grad.data)
下面研究一下如何能够对非标量的情况下使用backward。backward里传入的参数是每次求导的一个系数。
首先定义好输入m=(x1,x2)=(2,3),然后我们做的操作就是n=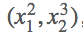 ,这样我们就定义好了一个向量输出,结果第一项只和x1有关,结果第二项只和x2有关,那么求解这个梯度,
,这样我们就定义好了一个向量输出,结果第一项只和x1有关,结果第二项只和x2有关,那么求解这个梯度,
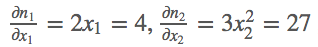
# backward on non-scalar output
m = v(t.FloatTensor([[2, 3]]), requires_grad=True)
n = v(t.zeros(1, 2))
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3
n.backward(t.FloatTensor([[1, 1]]))
print('*'*10)
print('=====non scalar output======')
print('input')
print(m.data)
print('input gradients are')
print(m.grad.data)
jacobian矩阵
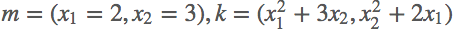
对其求导:
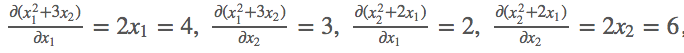
k.backward(parameters)接受的参数parameters必须要和k的大小一模一样,然后作为k的系数传回去,backward里传入的参数是每次求导的一个系数。
# jacobian
j = t.zeros(2 ,2)
k = v(t.zeros(1, 2))
m.grad.data.zero_()
k[0, 0] = m[0, 0] ** 2 + 3 * m[0 ,1]
k[0, 1] = m[0, 1] ** 2 + 2 * m[0, 0]
# [1, 0] dk0/dm0, dk1/dm0
k.backward(t.FloatTensor([[1, 0]]), retain_variables=True) # 需要两次反向求导
j[:, 0] = m.grad.data
m.grad.data.zero_()
# [0, 1] dk0/dm1, dk1/dm1
k.backward(t.FloatTensor([[0, 1]]))
j[:, 1] = m.grad.data
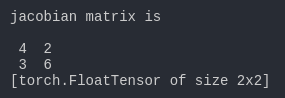
print('jacobian matrix is')
print(j)
我们要注意backward()里面另外的一个参数retain_variables=True,这个参数默认是False,也就是反向传播之后这个计算图的内存会被释放,这样就没办法进行第二次反向传播了,所以我们需要设置为True,因为这里我们需要进行两次反向传播求得jacobian矩阵。
PyTorch中的backward [转]的更多相关文章
- 关于Pytorch中autograd和backward的一些笔记
参考自<Pytorch autograd,backward详解>: 1 Tensor Pytorch中所有的计算其实都可以回归到Tensor上,所以有必要重新认识一下Tensor. 如果我 ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- pytorch 中的重要模块化接口nn.Module
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 对于自己 ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- pytorch中调用C进行扩展
pytorch中调用C进行扩展,使得某些功能在CPU上运行更快: 第一步:编写头文件 /* src/my_lib.h */ int my_lib_add_forward(THFloatTensor * ...
- 关于Pytorch中accuracy和loss的计算
这几天关于accuracy和loss的计算有一些疑惑,原来是自己还没有弄清楚. 给出实例 def train(train_loader, model, criteon, optimizer, epoc ...
- 【PyTorch】PyTorch中的梯度累加
PyTorch中的梯度累加 使用PyTorch实现梯度累加变相扩大batch PyTorch中在反向传播前为什么要手动将梯度清零? - Pascal的回答 - 知乎 https://www.zhihu ...
- PyTorch中的C++扩展
今天要聊聊用 PyTorch 进行 C++ 扩展. 在正式开始前,我们需要了解 PyTorch 如何自定义module.这其中,最常见的就是在 python 中继承torch.nn.Module,用 ...
- PyTorch中的Batch Normalization
Pytorch中的BatchNorm的API主要有: 1 torch.nn.BatchNorm1d(num_features, 2 3 eps=1e-05, 4 5 momentum=0.1, 6 7 ...
随机推荐
- FFmpeg configure: rename cuda to ffnvcodec 2018-03-06
FFmpeg version of headers required to interface with Nvidias codec APIs. Corresponds to Video Codec ...
- Linux下的进程结构
Linux系统是一个多进程的系统,它的进程之间具有并行性.互不干扰等特点.也就是说,每个进程都是一个独立的运行单位,拥有各自的权利和责任.其中,各个进程都运行在独立的虚拟地址空间.因此,即使一个进程发 ...
- redis-3.2.11哨兵模式的配置
设置内核参数: echo never > /sys/kernel/mm/transparent_hugepage/enabled > /proc/sys/vm/overcommit_mem ...
- mysql报ERROR:Deadlock found when trying to get lock; try restarting transaction(nodejs)
1 前言 出现错误 Deadlock found when trying to get lock; try restarting transaction.然后通过网上查找资料,重要看到有用信息了. 错 ...
- 利用zxing生成二维码
使用zxing类库可以很容易生成二维码QRCode,主要代码如下: private Bitmap createQRCode(String str,int width,int height) { Bit ...
- 如何使用Jquery直接导入记事本的内容
直接上代码 <!DOCTYPE html> <html> <head> <title> </title> </head> < ...
- 4)django-视图view
视图是django功能函数,结合url使用 1.视图方式 视图方式经常用的有两种 用户GET获取数据 用户POST提交数据 用户第一次访问页面是GET 用户 ...
- 并发性能的隐形杀手之伪共享(false sharing)
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- headless&unittest
为什么要使用 headless 测试? headless broswer 可以给测试带来显著好处: 对于 UI 自动化测试,少了真实浏览器加载 css,js 以及渲染页面的工作.无头测试要比真实浏览器 ...
- Confluence 6 用户宏示例 - NoPrint
这个示例演示了如何创建一个用户宏,这个宏包括了在查看页面中显示的内容,但是不被打印. Macro name noprint Visibility Visible to all users in the ...