关系网络数据可视化:2. Python数据预处理
将数据中导演与演员的关系整理出来,得到导演与演员的关系数据,并统计合作次数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 读取数据 import os
# os.chdir('C:/Users/Hjx/Desktop/')
os.chdir(r'C:\Users\Administrator\Desktop\ch0304_data')
df = pd.read_excel('豆瓣电影数据.xlsx',sheetname=0,header=0)
print('数据总共%i条' % len(df))
print('数据字段为:\n',df.columns.tolist())
df.head(2)
# 查看数据

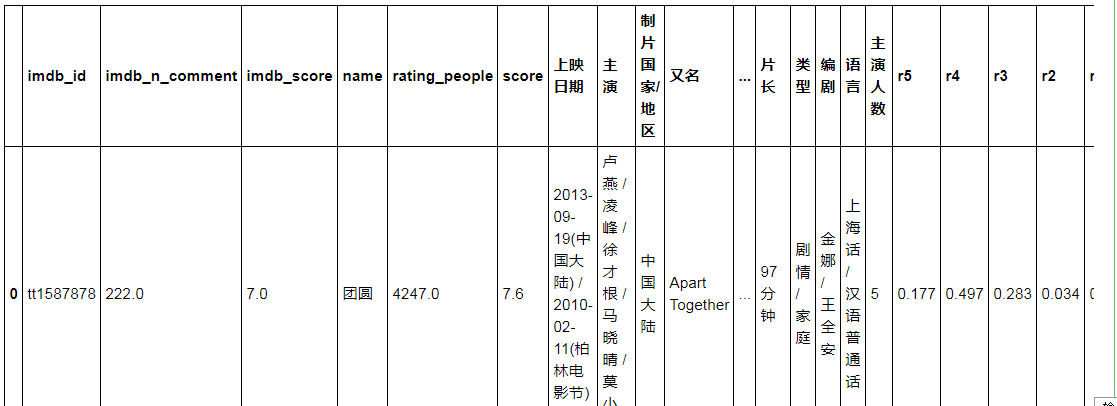
#数据清洗
data = df[['name', '导演', '主演']]
data.dropna(inplace = True)
data.head()
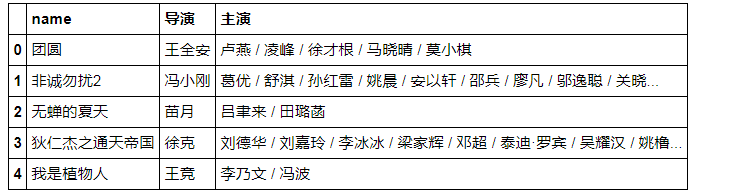
data_yy = data['主演'].str.split('/ ', expand=True)
col_len1 = len(data_yy.columns)
data_yy.columns = ['yy'+str(i) for i in range(col_len1)]
data_yy.head()

data_dy = data['导演'].str.split('/ ', expand=True)
col_len2 = len(data_dy.columns)
data_dy.columns = ['dy'+str(i) for i in range(col_len2)]
data_dy.head()
data2 = data_dy.join(data_yy).join(data['name'])
data2.head()

#拆分+合并 data_re = pd.DataFrame(columns=['name','导演','演员'])
# 创建一个空的Dataframe col_yy = data_yy.columns
col_dy = data_dy.columns for dy in col_dy:
for yy in col_yy:
data_i = data2[['name', dy, yy]].dropna() # 提取数据
data_i.columns = ['name', '导演', '演员'] ## 列名重命名
# print(data_i)
data_re = pd.concat([data_re, data_i]) # 添加数据
print(data_re.head())
# 遍历数据后,得到一个导演与演员的关系数据,并做去重处理
# 这里index是有重复的,但作为过程数据可忽略

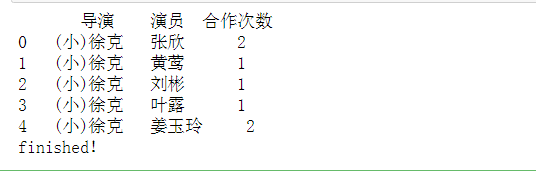
# 汇总统计导演和演员的合作次数 result = data_re.groupby(['导演','演员']).count()
result.reset_index(inplace=True)
result.columns = ['导演','演员','合作次数']
print(result.head())
# 按照导演-演员进行计数统计,得到结果数据
# reset_index() → 将所有索引级别转换为列 writer = pd.ExcelWriter('output.xlsx')
result.to_excel(writer,'sheet1')
writer.save()
# 存为excel
# 注意:output.xlsx文件不能是打开状态 print('finished!')
关系网络数据可视化:2. Python数据预处理的更多相关文章
- 【数据科学】Python数据可视化概述
注:很早之前就打算专门写一篇与Python数据可视化相关的博客,对一些基本概念和常用技巧做一个小结.今天终于有时间来完成这个计划了! 0. Python中常用的可视化工具 Python在数据科学中的地 ...
- 分形、分形几何、数据可视化、Python绘图
本系列采用turtle.matplotlib.numpy这三个Python工具,以分形与计算机图像处理的经典算法为实例,通过程序和图像,来帮助读者一步步掌握Python绘图和数据可视化的方法和技巧,并 ...
- caffe(13) 数据可视化(python接口)配置
caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较 ...
- 数据可视化:使用python代码实现可视数据随机漫步图
#2020/4/5 ,是开博的第一天,希望和大家相互交流学习,很开森,哈哈~ #像个傻子哟~ #好,我们进入正题, #实现功能:利用python实现数据随机漫步,漫步点数据可视化 #什么是 ...
- 数据透视:Excel数据透视和Python数据透视
作者 | leo 早于90年代初,数据透视的概念就被提出,主要的应用场景是处理大量数据的交互式汇总查询,它实现了行或列的移动,使得行可以移到列上,列移到行上,从而根据使用者的诉求取对关注的数据子集进行 ...
- 数据可视化(8)--D3数据的更新及动画
最近项目组加班比较严重,D3的博客就一拖再拖,今天终于不用加班了,赶紧抽点时间写完~~ 今天就将D3数据的更新及动画写一写~~ 接着之前的博客写~~ 之前写了一个散点图的例子,下面可以自己写一个柱状图 ...
- <数据可视化>样例+数据+画图
1 样例 1.1样例1 子图系列 from pylab import * def f(x): return np.exp(-x) * np.cos(2*np.pi*x) x1 = np.arange( ...
- Python数据可视化的四种简易方法
摘要: 本文讲述了热图.二维密度图.蜘蛛图.树形图这四种Python数据可视化方法. 数据可视化是任何数据科学或机器学习项目的一个重要组成部分.人们常常会从探索数据分析(EDA)开始,来深入了解数据, ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
- python grib气象数据可视化
基于Python的Grib数据可视化 利用Python语言实现Grib数据可视化主要依靠三个库——pygrib.numpy和matplotlib.pygrib是欧洲中期天气预报中心 ...
随机推荐
- 借助dubbo-admin来管理你的服务
1. Github上下载最新的dubbo源码包并解压 2. 修改配置信息(打开 dubbo-admin/src/main/webapp/WEB-INF下的dubbo.properties,修 ...
- 24)django-信号
目录 1)django信号简介 2)django内置信号 3)django自定义信号 一:django信号简介 Django中提供了“信号调度”,用于在框架执行操作时解耦. 通俗来讲,就是一些动作发生 ...
- JS知识点随笔
1.为什么 0.1 + 0.2 != 0.3? 原因: 因为 JS 采用 IEEE 754 双精度版本(64位),并且只要采用 IEEE 754 的语言都有该问题. 我们都知道计算机是通过二进制来存储 ...
- Confluence 6 管理协同编辑
协同编辑能够让项目小组中的协同合作达到下一个高度.这个页面对相关协同编辑中的问题进行了讨论,能够提供给你所有希望了解的内容. 进入 Collaborative editing 页面来获得项目小组是如何 ...
- ionic2 子页面隐藏去掉底部tabs导航,子页面全占满显示方法(至今为止发现的最靠谱的方法)
项目中遇到 tabs 字页面 可以用以下代码隐藏的方式: imports: [ BrowserModule, // IonicModule.forRoot(MyApp), HttpModule, Io ...
- linux学习笔记:第二单元 UNIX和Linux操作系统概述
第二单元 UNIX和Linux操作系统概述 UNIX是什么 UNIX操作系统的特点 UNIX 与Linux的关系 GNU项目与自由软件 GUN计划 自由软件意味着什么 Linux简介 Linux是什么 ...
- 【转载】中文输入法下onKeyPress不能触发的问题
onKeypress---->oninput https://segmentfault.com/a/1190000008820968
- 利用map和stringstream数据流解题
题目描述 喜闻乐见A+B.读入两个用英文表示的A和B,计算它们的和并输出. 输入 第一行输入一个字符串,表示数字A:第二行输入一个字符串表示数字B.A和B均为正整数. 输出 输出一个正整数n,表示A+ ...
- Vue中使用Vue.component定义两个全局组件,用单标签应用组件时,只显示一个组件的问题和 $emit的使用。
解决方法: 定义了两个 Vue.component 在 el 中使用的时候要用 双标签, 用单表标签的时候,只会显示第个 组件间 这样写只显示 welcome-button 组件 <welcom ...
- 异常小结:上一张图搞清楚Java的异常机制
下面是Java异常类的组织结构,红色区域的异常类表示是程序需要显示捕捉或者抛出的. Throwable Throwable是Java异常的顶级类,所有的异常都继承于这个类. Error,Excepti ...