字符串模式匹配算法系列(二):KMP算法
算法背景:
KMP算法是由Donald Knuth和Vaughan Pratt于1970年共同提出的,而James H.Morris也几乎同时间独立提出了这个算法。因此人们将其称作“克努特-莫里斯-普拉特”算法(简称KMP)。
KMP算法的学习,可以在掌握了BF算法原理、并结合“BF算法效率低”作为切入点来理解,这样感觉比较符合大家的思维习惯。
算法原理:
上一篇博文《BF算法》的最后,有提到BF算法每次发现不匹配时,目标字符串只能向后挪动一个字符的距离,隐约感觉这样效率很低。
所以自然想到:发现不匹配时,目标字符串能不能向后多挪动几个字符的距离、从而加快整个算法的速度?甚至说极端一些,直接把目标字符串挪动到不匹配的位置上然后继续呢?



观察上面两张图,可以发现,向后挪动太多了是不行的,这样可能错过了原本可以匹配的基准点:
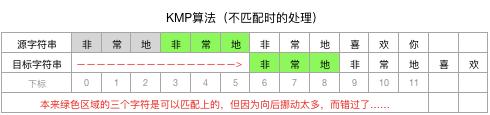
小结一下:
BF算法,是把目标字符串向后挪动一个字符(第一轮在下标0的位置上,第二轮挪到下标1、第三轮挪到下标2、第四轮挪到下标3并匹配成功),这样可以确保不会错过可以匹配的基准点,但效率太低;
我们的新想法,是把目标字符串向后多挪动几个字符,但不确定应该挪动几个字符,如果挪多了,就会错过潜在可以匹配的基准点(就像上面说的极端情况:一次向后挪动了6个位置,结果错过了下标3的那个可以匹配的基准点)
既想把目标字符串向后多挪动几个字符、从而加快速度,但又不能因为挪动的太快太多、而错过了原本可以匹配的字符。怎样才能同时做到这两点?
KMP算法,就是预先计算好这个应该挪动的字符数,这样问题就迎刃而解:即加快了向后挪动目标字符串的距离,又确保不会错过可能匹配的基准点。
我们仍然借用整个算法的执行过程,来说明“应该挪动的字符数”是如何确定的,然后再说明其是可以提前计算好的。
假定现在的不匹配点在下标6的位置,因此要计算目标字符串前面的字符串“非常地非常地”的最大向后挪动距离。

首先可以看到,下标6前面的字符串是“非常地非常地”,这个字符串在源字符串和目标字符串里是一样的(肯定是一样的,不然也不会到下标6才发现不匹配……),我们将其称作匹配子串。
仔细想一下:此时目标字符串向后挪动一段“恰当”的距离,是因为:挪动后的目标字符串中的匹配子串的前n个字符,与源字符串中的匹配子串的后n个字符有可能会匹配上。
因为我们不能错过这个潜在的匹配,所以才不能像前文说的那样,一次挪动的太多:

将上面两段描述综合起来看,其实就是在寻找:不匹配点前面的匹配子串的相同且最长的前n个字符和后n个字符,我们来实际演示一下寻找过程:



综上,下标6的这个不匹配点,它的匹配子串“非常地非常地”的长度为6,其前3个字符和后3个字符一样,即n=3
所以目标字符串可以向后挪动的距离就是6-3=3个位置(到下标3),这样就加快了挪动速度,又不会错过潜在的匹配基准点。

为了巩固说明,再举一个类似的例子,我们换一个目标字符串为:“非常地喜欢”,则现在不匹配点是在下标3的位置:
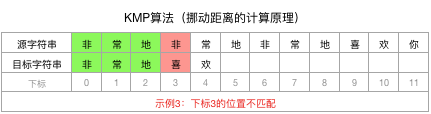
拿到下标3前面的字符串“非常地”,计算其相同且最长的前n个字符和后n个字符
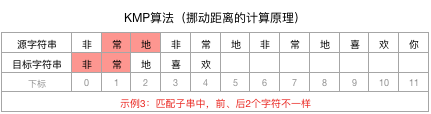
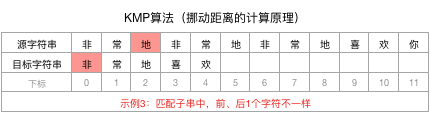
进而得到结论,“非常地”没有相同的前、后n个字符,即n=0。
匹配子串的长尾为3,其中没有相同的前后n个字符(n为0),所以就可以直接让目标字符串向后移动3-0=3个位置,并开始新一轮匹配:

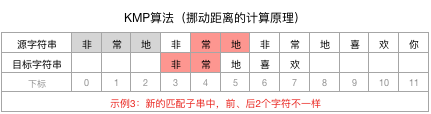
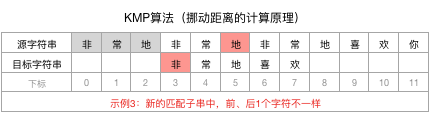
类似地,匹配子串长尾是3,相同且最长的前后n个字符没有找到,即n=0,所以目标字符串可以再向后移动3-0=3个字符,并开始新一轮匹配:

最终匹配成功。
从上面的例子可以看到几个现象:
1. “可以向后挪动的距离” = 位置 - 最长且相同的前/后缀子串
2. 在实际执行匹配算法之前,1可以只依靠目标字符串得到
3. 在实际使用算法之前无法知道具体在哪个位置不匹配,所以只能假设目标字符串每个位置都可能不匹配,并将不匹配点前面部分作为匹配子串来计算“相同且最长的前、后n个字符”,进而结合当前位置,得到这个不匹配点上可以向后挪动的距离。
进一步,可以将每个位置的【配置子串中最长且相同的前/后缀串】存储成为一个备份表,在实际算法执行时,根据目标字符串不匹配的实际位置,直接查询这张备份表,两者相减就可以得到此时此刻向后挪动的距离。这张备份表的学名就是【部分匹配表】
举个例子,如果目标字符串为“非常地非常地喜欢”,则其【部分匹配表】的内容为:
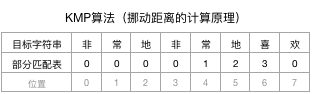
强调一下:部分匹配表中每一列的部分匹配表的值,是以其前面的子串来计算的。例如:位置6的“喜”字,其部分匹配表的值(3),是根据其前面的匹配子串“非常地非常地”计算来的,而不是“非常地非常地喜”(即不包括本身)!
实际使用时,用对应的位置值 - 备份表的值,就是目标字符串可以向后移动的距离。例如:位置6不匹配了,其目标字符串可以向挪动:6-3=3个位置。如果位置7不匹配了,目标字符串可以向后挪动7-0=7个位置。
类似地,如果目标字符串为“非常地喜欢”,则其部分匹配表的内容为:
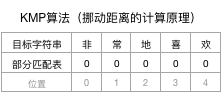
这张部分匹配表所有值都是0,说明任何位置不匹配都可以直接跳到不匹配点重新比较,这种情况无疑是速度最快的情况。
由此也可以看出,目标字符串里前后重复的字符越少,目标字符串向后挪动的速度就越快,整个算法的效率就越高。
下面介绍一下【部分匹配表】的计算过程。
(此处稍后补充)
算法实现
KMP的python实现如下:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import sys reload(sys)
sys.setdefaultencoding('utf-8') class KMP(object):
"""KMP算法
成员变量:
s: 源字符串
t: 目标字符串
pmt: 部分匹配表(向右挪动了1格, 位置0赋-1)
"""
def __init__(self, s, t):
self.s = s
self.t = t
self.pmt = {} def _get_pmt_1(self):
"""根据目标字符串,计算前后缀的最大重复子串
此方法简单,但dn指针可能回退到-1,且up不是每次都递增,所以while循环次数最多可能是t长度的两倍
"""
self.pmt[0] = -1 # 位置0赋值-1,为了计算方便
up = 0 # up表示上指针,用来向后移动从而实现错位
dn = -1 # dn表示下指针,用来记录匹配的位置 while up < len(self.t):
if dn == -1 or self.t[up] == self.t[dn]:
up += 1
dn += 1
self.pmt[up] = dn
else:
dn = self.pmt[dn] def _get_pmt_2(self):
"""根据目标字符串,计算前后缀的最大重复子串
此方法略复杂,但dn指针不后退且up每次都递增1,所以while循环次数为t的长度
"""
self.pmt[0] = -1 # 位置0赋值-1,为了计算方便
self.pmt[1] = 0 # 位置1赋值0,表示没有匹配
up = 1 # up表示上指针,用来向后移动从而实现错位
dn = 0 # dn表示下指针,用来记录匹配的位置
same_len = 0 # 表示匹配的字符串长度 while up < len(self.t):
if self.t[up] == self.t[dn]:
dn += 1
same_len += 1
else:
same_len = 0
up += 1
self.pmt[up] = same_len def run_1(self):
"""完全匹配则返回源字符串匹配成功的起始点的下标,否则返回-1
此方法简单,但循环次数比run_2多一倍
"""
ptr_s = 0
ptr_t = 0 # 获取pmt
self._get_pmt_1() #也可以用self._get_pmt_2() while ptr_t == -1 or ptr_s < len(self.s) and ptr_t < len(self.t):
if self.s[ptr_s] == self.t[ptr_t]:
ptr_s += 1
ptr_t += 1
else:
ptr_t = self.pmt[ptr_t] if ptr_t == len(self.t):
return ptr_s - ptr_t
return -1 def run_2(self):
"""完全匹配则返回源字符串匹配成功的起始点的下标,否则返回-1
此方法复杂,但循环次数比run_1少一半
"""
base = 0
same_len = 0
len_s = len(str_s)
len_t = len(str_t) # 获取pmt
self._get_pmt_2() #也可以用self._get_pmt_1() while base + len_t <= len_s:
step = 0
while step + same_len < len_t:
if self.t[step + same_len] == self.s[base + step + same_len]:
# 当前字符相同,则继续比较下一个字符
step += 1
continue
# 当前字符不相同,则结束次轮比较,更新base基准位置,启动下一轮比较
same_len = self.pmt[step]
base += step - same_len
break
# 完全匹配成功,算法结论,返回匹配成功的基准点位置下标
if step + same_len == len_t:
return base
# 遍历了所有情况,最终匹配失败,返回-1
return -1 if __name__ == '__main__':
str_s = u"非常地非常地非常地喜欢你"
str_t = u"非常地喜欢"
model = KMP(str_s, str_t)
print model.run_2()
算法评估
假设源字符串长度为m,目标字符串长度为n
KMP的时间复杂度为O(m+n)
KMP的空间复杂度为O(n),因为多了一个和目标字符串相同长度的备份表
字符串模式匹配算法系列(二):KMP算法的更多相关文章
- 字符串模式匹配算法--BF和KMP详解
1,问题描述 字符串模式匹配:串的模式匹配 ,是求第一个字符串(模式串:str2)在第二个字符串(主串:str1)中的起始位置. 注意区分: 子串:要求连续 (如:abc 是abcdef的子串) ...
- 常用算法3 - 字符串查找/模式匹配算法(BF & KMP算法)
相信我们都有在linux下查找文本内容的经历,比如当我们使用vim查找文本文件中的某个字或者某段话时,Linux很快做出反应并给出相应结果,特别方便快捷! 那么,我们有木有想过linux是如何在浩如烟 ...
- 字符串模式匹配算法系列(一):BF算法
算法背景: BF(Brute Force)算法,是一种在字符串匹配的算法中,比较符合人类自然思维方式的方法,即对源字符串和目标字符串逐个字符地进行比较,直到在源字符串中找到完全与目标字符串匹配的子字符 ...
- 字符串模式匹配算法系列(三):Trie树及AC改进算法
Trie树的python实现(leetcode 208) #!/usr/bin/env python #-*- coding: utf-8 -*- import sys import pdb relo ...
- [转] 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 转载自:http://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boy ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法
ref : https://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 KMP ...
- Java数据结构之字符串模式匹配算法---Brute-Force算法
模式匹配 在字符串匹配问题中,我们期待察看源串 " S串 " 中是否含有目标串 " 串T " (也叫模式串).其中 串S被称为主串,串T被称为子串. 1.如果在 ...
- Java数据结构之字符串模式匹配算法---KMP算法
本文主要的思路都是参考http://kb.cnblogs.com/page/176818/ 如有冒犯请告知,多谢. 一.KMP算法 KMP算法可以在O(n+m)的时间数量级上完成串的模式匹配操作,其基 ...
随机推荐
- Java JDK在Mac下的配置方法
Java JDK在Mac.Windows下的配置方法 Mac 第一步:下载JDK 官网下载地址 第二步:安装JDK 安装步骤很简单,一直点击下一步即可. 第三步:配置环境变量 打开terminal(终 ...
- Git基本常用指令
开发十年,就只剩下这套架构体系了! >>> Git基本常用命令如下: mkdir: XX (创建一个空目录 XX指目录名) pwd: 显示当前目 ...
- JS中数组和字符串方法的简单整理
一.数组: 数组的基本方法: 1.增:arr.unshift() /push() 前增/后增 2.删:arr.shift() /pop ...
- WPF的DataTrigger使用
首先创建一个空的项目 然后看看前台写的代码,如下图所示 <Grid> <StackPanel HorizontalAlignment="Center" Verti ...
- 详聊js中的原型/原型链
先以一段简单的代码为例: function Dog(params){ this.name = param.name; this.age = param.age; this.ba ...
- 2018-2-13-win10-uwp-读写csv-
title author date CreateTime categories win10 uwp 读写csv lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17 ...
- kali优化配置(2)
下次再安Java吧...心累小赵在线哭泣... 0x01 安装显卡驱动 安装GPU,加速密码破解: grub--kali的启动器 0x02 并发线程限制 ulimit由于限制当前shell内进程的资源 ...
- 学Python的第五天
最近忙着学MySQL,但是小编也不会放弃学Python!!! 因为热爱所以学习~ 好了各位,进入正题,由于时间问题今天学的不是很多.... #!/usr/bin/env python # -*- co ...
- CA认证机制的简明解释
公钥机制面临的问题: 假冒身份发布公钥! 可以用CA来认证公钥的身份.CA有点像公安局,公钥就像身份证.公安局可以向任何合法用户颁发身份证以证明其合法身份.第三方只要识别身份证的真伪就能判断身份证持有 ...
- ps:图像尺寸
在课程#01中我们知道了显示器上的图像是由许多点构成的,这些点称为像素,意思就是“构成图像的元素”.但是要明白一点:像素作为图像的一种尺寸,只存在于电脑中,如同RGB色彩模式一样只存在于电脑中.像素是 ...