Libvirt Live Migration 与 Pre-Copy 实现原理
目录
文章目录
Libvirt 的 Live Migration
Libvirt 的 Live Migration 主要分为两个层面:
- 网络数据传输层面
- 控制层面
网络数据传输层
- 基于 Hypervisor 的传输,两个 Hypervisor 之间直接建立数据传输连接。优点:数据传输量少。缺点:需要额外配置 Hypervisor Network。需要在防火墙上面打开更多的端口来支持并发迁移,数据不一定支持加密(取决于 Hypervisor 实现)。
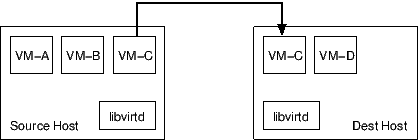
- 基于 libvirtd Tunnel 的传输,源主机和目标主机上运行的 libvirtd 之间建立 RPC 隧道来传输数据。数据要先拷贝到 libvirtd,再由 libvirtd 中继到目标主机的 libvirtd。优点:不需要重新配置网络,防火墙上面只需要一个端口就可以支持并发迁移,数据强加密。缺点:相关的数据拷贝多,所有流量都通过一个端口,容易造成网络拥堵。
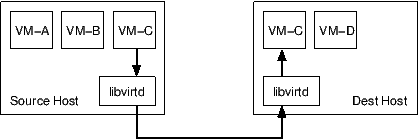
在 Tunnel 传输模式下,同一份数据需要被拷贝多次,并且所有的流量都通过一个端口,在大内存、高业务(快速增加 RAM 脏数据)的场景下,同样的网络带宽,Tunnel 传输模式迁移速率较慢。因此,对于大内存、业务繁忙的场景下,首选基于 Hypervisor 的传输。
控制层
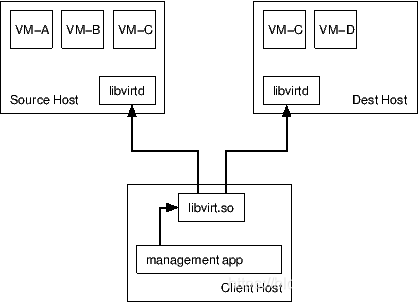
- Client 控制:由 Libvirt Client 直接控制迁移。Client 跟源主机 libvirtd 连接,也跟目的主机 libvirtd 连接,当目的主机迁移过程出现异常会反馈给 Client,再由 Client 通知源 libvirtd。整个过程,由 Client 主导控制。
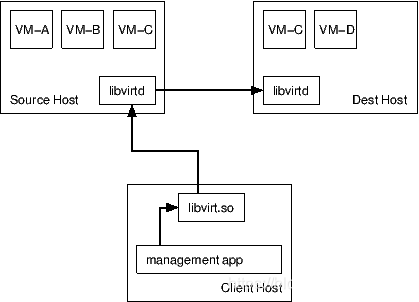
- 源主机 libvirtd 控制:由源主机 libvirtd 主导整个迁移过程。Client 仅作为迁移指令的发起者,将迁移指令异步发送给源主机 libvirtd。如果目的主机迁移过程出现异常会反馈给源主机 libvirtd。这种方式的好处是,Client 故障也不会影响到整个迁移过程。
- Hypervisor 控制:有源主机 Hypervisor 控制整个迁移过程,Client 向源主机 Hypervisor 发送迁移指令,源主机和目的主机的 libvirtd 不参与控制。这种方式的前提是 Hypervisor 自身支持热迁移,好处在于 Client 和 libvirtd 的故障不会影响到整个迁移过程。
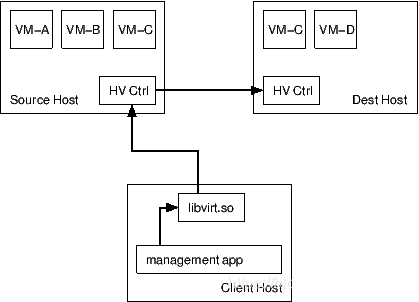
通过 libvirt 库实现虚拟机迁移的示例
import libvirt
import pprint
conn_src = libvirt.open('qemu+tcp://username@src_server/system')
conn_dest = libvirt.open('qemu+tcp://username@dest_server/system')
vm_domain = conn_src.lookupByName('instance_name')
vm_domain.migrate(conn_dest, True, 'instance_name', None, 0)
pprint.pprint(help(vm_domain.migrate))
KVM 的预拷贝(Pre-Copy)Live Migration 过程
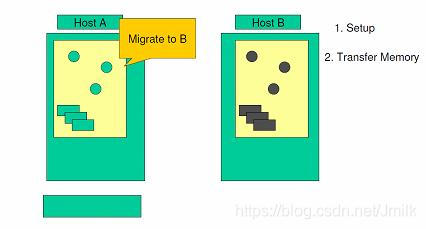
Step 1. 系统验证目标服务器的存储器和网络设置是否正确,并预保留目标服务器虚拟机的资源。
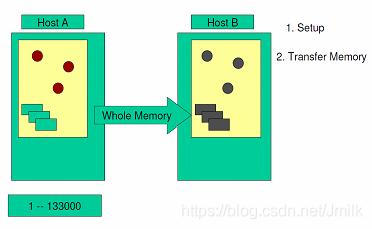
Step 2. 当虚拟机还在源服务器上运转时,第一个循环内将全部内存镜像复制到目标服务器上。在这个过程中,KVM 依然会监视内存的任何变化。
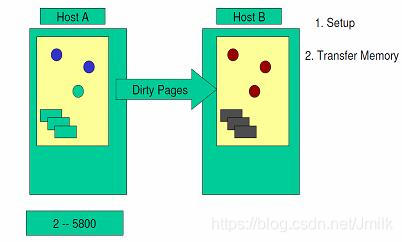
Step 3. 以后的循环中,检查上一个循环中内存是否发生了变化。 假如发生了变化,那么 VMM 会将发生变化的内存页即 dirty pages 重新复制到目标服务器中,并覆盖掉先前的内存页。在这个阶段,VMM 依然会继续监视内存的变化情况。
Step 4. VMM 会持续这样的内存复制循环。随着循环次数的增加,所需要复制的 dirty pages 就会明显减少,而复制所耗费的时间就会逐渐变短,那么内存就有可能没有足够的时间发生变化。最后,当源服务器与目标服务器之间的差异达到一定标准时,内存复制操作才会结束,同时暂停源系统。
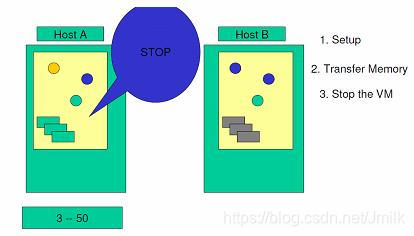
Step 5. 在源系统和目标系统都停机的情况下,将最后一个循环的 dirty-pages 和源系统设备的工作状态复制到目标服务器。
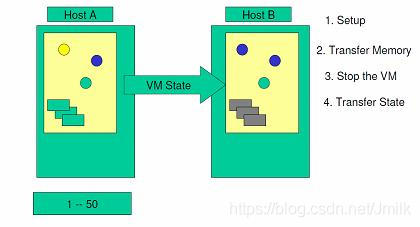
Step 6. 然后,将存储从源系统上解锁,并锁定在目标系统上。启动目标服务器,并与存储资源和网络资源相连接。
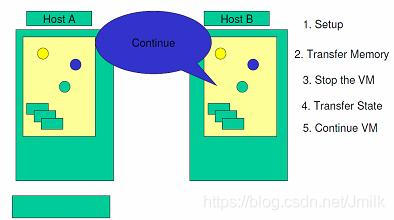
参考资料
https://www.ibm.com/developerworks/cn/linux/l-cn-mgrtvm1/index.html
Libvirt Live Migration 与 Pre-Copy 实现原理的更多相关文章
- OpenStack 虚拟机冷/热迁移的实现原理与代码分析
目录 文章目录 目录 前文列表 冷迁移代码分析(基于 Newton) Nova 冷迁移实现原理 热迁移代码分析 Nova 热迁移实现原理 向 libvirtd 发出 Live Migration 指令 ...
- va_list原理及用法
最后更新:2017-02-22 这是一篇很早很早的博客文章,虽然很基础,但是毕竟曾经历程,因此也保存下来 1. 概念 va_list 是在C语言中定义的宏,指在解决 变参问题是指参数的个数不定,可以是 ...
- Python的深浅copy详解
Python的深浅copy详解 目录 Python的深浅copy详解 一.浅copy的原理 1.1 浅copy的定义 1.2 浅copy的方法 二.深copy的原理 2.1 深copy的定义 2.2 ...
- openstack Icehouse发布
OpenStack 2014.1 (Icehouse) Release Notes General Upgrade Notes Windows packagers should use pbr 0.8 ...
- KVM虚拟机配置笔记
KVM 全称是 Kernel-Based Virtual Machine.也就是说 KVM 是基于 Linux 内核实现的,KVM有一个内核模块叫 kvm.ko,只用于管理虚拟 CPU 和内存. 在 ...
- OpenStack 2014.1(Icehouse) 更新说明
OpenStack 2014.1(Icehouse) 更新说明 1.综合升级说明 Windows安装包应使用PBR 0.8版本,以避免发生bug1294246 log-config选项 ...
- OpenStack 虚拟机冷/热迁移功能实践与流程分析
目录 文章目录 目录 前文列表 虚拟机迁移的应用场景 需要迁移的虚拟机数据类型 虚拟机迁移的存储场景 文件存储 块存储 非共享存储 迁移的类型 迁移的方式 执行虚拟机冷迁移 冷迁移日志分析 执行虚拟机 ...
- Linux入门详解
Linux基础知识 Linux&Unix 说起Linux,就不得不提Unix操作系统. Unix系统号称世界上最稳定的系统,就连苹果公司也从中获取灵感开发出了移动端大名鼎鼎的IOS. Unix ...
- openstack学习(一)kvm-libvirt
准备工作: 操作系统:ubuntu 16.04 安装KVM Kernel-based Virtual Machine的简称,是一个开源的系统虚拟化模块,自Linux 2.6.20之后集成在Linux的 ...
随机推荐
- google的CacheBuilder缓存
适用性: 计算或检索一个值的代价很高,并且对同样的输入需要不止一次获取值的时候,就应当考虑使用缓存. 常用用法: LoadingCache<Key, Graph> graphs = Cac ...
- 介绍知道的http返回的状态码
100 Continue 继续.客户端应继续其请求 101 Switching Protocols 切换协议.服务器根据客户端的请求切换协议.只能切换到更高级的协议,例如,切换 ...
- mahout从入门到放弃--安装(1)
1.稀里糊涂下载 我的集群是hadoop 2.7.3 ,本来想找到对应的mahout版本,但是没有找到.本着安全原则,mahout最新版本是0.14.0,回退一个版本使用0.13.0 mahout地址 ...
- IPC 进程间通信方式——共享内存
共享内存 共享内存区域是被多个进程共享的一部分物理内存. 多个进程都可以把共享内存映射到自己的虚拟空间.所有用户空间的进程要操作共享内存,都要将其映射到自己的虚拟空间,通过映射的虚拟内存空间地址去操作 ...
- 用DevExpress.textEdit控件限定数据录入格式
例:只允许输入4位数字 第一步 第二部 例:只允许IP格式 设置Mask属性项的EditMask属性值为:(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5 ...
- 手动解析网易云音乐MP3真实地址
火狐打开音乐播放页面 然后按F12 点击网络选项卡 点击音乐播放按钮 然后过滤输入“url” 选中筛选出来的结果 点击右边的相应选项卡 下面的url里面就是真实的预约MP3地址
- 数据库之MySQL-基本知识(与Oracle简单对比)
一.什么是数据库 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库, 每个数据库都有一个或多个不同的API用于创建,访问,管理,搜索和复制所保存的数据. 我们也可以将数据存储在文件 ...
- 【leetcode】1248. Count Number of Nice Subarrays
题目如下: Given an array of integers nums and an integer k. A subarray is called nice if there are k odd ...
- 【leetcode】1239. Maximum Length of a Concatenated String with Unique Characters
题目如下: Given an array of strings arr. String s is a concatenation of a sub-sequence of arr which have ...
- SharpCompress 压缩解压
public class SharpCompressHelper { public static void UnRAR(string srcUrl,string targetUrl) { using ...