集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别
一、HashMap 的原理
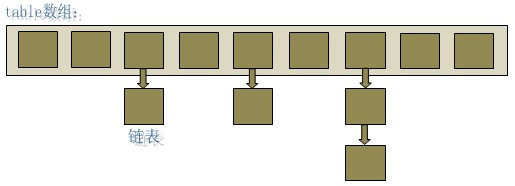
1.HashMap简介
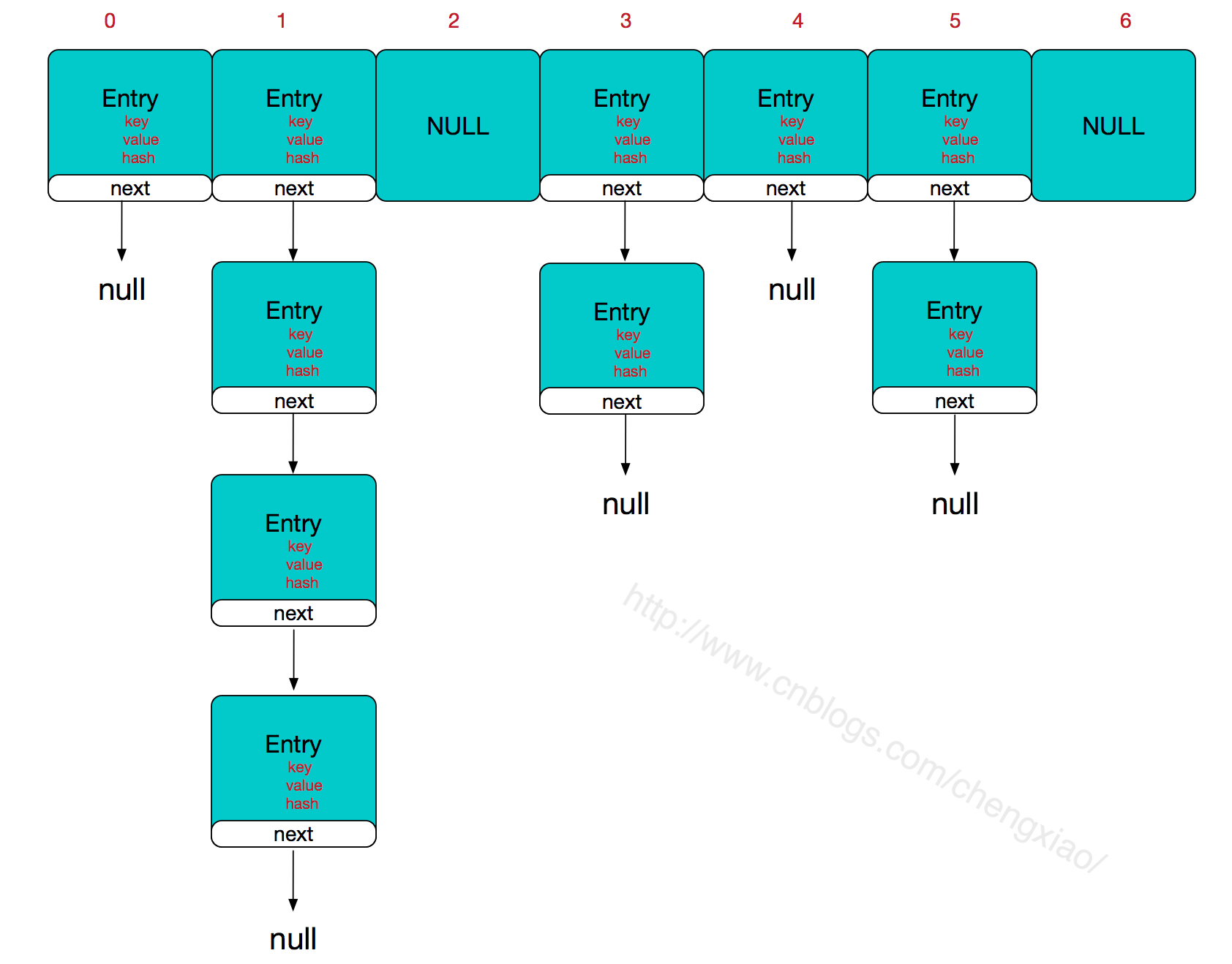
简单来讲,HashMap底层是由数组+链表的形式实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。当新建一个HashMap的时候,就会初始化一个数组(数组默认大小是16),可以允许存入null键和null值,线程不安全。
源码如下:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
可以看出,Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
2.HashMap存储和读取 源码如下:
//存储
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 如果发现已有该键值,则存储新的值,并返回原始值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
} //读取
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
} //hash算法
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
我们可以看到在HashMap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表,这样就大大优化了查询的效率。
根据上面 put 方法的源代码可以看出,当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
3.归纳总结:
HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
4.上面HashMap原理是基于JDK1.7介绍的,在JDK1.8中对HashMap进行了优化:
JDK1.7中一个很明显的地方是:当 Hash 冲突严重时,在数组上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。
因此 1.8 中重点优化了这个查询效率。区别具体体现在:1.增加了TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值(默认是8),一旦链表中的数据较多(即>8个)之后,就会转用红黑树来进行存储,优化存储速度,查询效率也直接提高到了 O(logn);2.HashEntry 修改为 Node,Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。
二、HashMap 与 Hashtable、ConcurrentHashMap 的区别
| HashTable | HashMap | ConcurrentHashMap | |
| 底层数据结构 | 数组+链表 | 数组+链表 | 数组+链表 |
| key可为空 | 否 | 是 | 否 |
| value可为空 | 否 | 是 | 否 |
| 线程安全 | 是 | 否 | 是 |
| 默认初始容量 | 11 | 16 | 16 |
| 扩容方式 | (oldSize << 1)+1 | oldSize << 1 | 桶的扩容 |
| 扩容时间 | size超过(容量*负载因子) | size超过(容量*负载因子) | 桶超数超过(容量*负载因子) |
| hash | key.hashCode() | (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16) | (key.hashCode() ^ (key.hashCode() >>> 16)) & 0x7fffffff |
| index计算方式 | (hash & 0x7FFFFFFF) % tab.length | (tab.length - 1) & hash | (tab.length - 1) & hash |
| 默认负载因子 | 0.75f | 0.75f | 0.75f |
三者主要区别:
1.存储时key、value能否为空问题:
HashTable和ConcurrentHashMap都不允许NULL键和NULL值,而HashMap允许
2.线程安全问题:
HashMap仅限运用于单线程,在多线程中可能存在问题,是线程不安全的;而HashTable和ConcurrentHashMap都是线程安全的。
HashTable实现线程安全的方式是在修改数据时锁住整个HashTable,让当前线程独占,效率低,而ConcurrentHashMap对此做了相关优化,ConcurrentHashMap通过把整个Map分为N个Segment(分段),在修改数据时会局部锁住某段部分数据,但不会把整个表都锁住。ConcurrentHashMap读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。因为volatile定义的变量保证了对所有线程可见。
参考博文:
http://www.cnblogs.com/yuanblog/p/4441017.html
集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别的更多相关文章
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- HashMap底层原理以及与ConCurrentHashMap区别
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象.当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bu ...
- HashMap,HashTable,concurrentHashMap,LinkedHashMap 区别
HashMap 不是线程安全的 HashTable,concurrentHashMap 是线程安全 HashTable 底层是所有方法都加有锁(synchronized) 所以操作起来效率会低 con ...
- HashMap工作原理 和 HashTable
原文链接: Javarevisited 翻译: ImportNew.com - 唐小娟 译文链接: http://www.importnew.com/7099.html 你用过HashMap吗 譬如H ...
- .net学习之集合、foreach原理、Hashtable、Path类、File类、Directory类、文件流FileStream类、压缩流GZipStream、拷贝大文件、序列化和反序列化
1.集合(1)ArrayList内部存储数据的是一个object数组,创建这个类的对象的时候,这个对象里的数组的长度为0(2)调用Add方法加元素的时候,如果第一次增加元神,就会将数组的长度变为4往里 ...
- HashMap不安全后果及ConcurrentHashMap线程安全原理
Java集合HashMap不安全后果及ConcurrentHashMap 原理 目录 HashMap JDK7 HashMap链表循环造成死循环 HashMap数据丢失 JDK7 Concurrent ...
- [Java集合] 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhanger ...
- Java集合——HashMap、HashTable以及ConCurrentHashMap异同比较
0. 前言 HashMap和HashTable的区别一种比较简单的回答是: (1)HashMap是非线程安全的,HashTable是线程安全的. (2)HashMap的键和值都允许有null存在,而H ...
- hashmap,hashTable concurrentHashMap 是否为线程安全,区别,如何实现的
线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多 ...
随机推荐
- Eclipes 安装windowbuilding
一.找到对应版本的windowbuilder 打开这个链接:http://www.eclipse.org/windowbuilder/download.php eclipse的版本号可以在eclips ...
- linux replace \r\n to \n
cat test.log | tr -d '\r' | hexdump -C | tail
- js中函数的创建和调用都发生了什么?执行环境,函数作用域链,变量对象
博客搬迁,给你带来的不便,敬请谅解! http://www.suanliutudousi.com/2017/11/26/js%E4%B8%AD%E5%87%BD%E6%95%B0%E7%9A%84%E ...
- DB2连接
ibm_db.connect 创建非持久连接. ibm_db.pconnect 创建持久连接. 在最初的Python脚本请求之后,持久的连接保持打开状态,这允许后续的Python请求重新使用连接. 后 ...
- multiple-cursors做代码对齐
multiple-cursors做代码对齐 */--> code {color: #FF0000} pre.src {background-color: #002b36; color: #839 ...
- vue aliasConfig(模块别名配置)
今天研究了下鹏哥搭建的项目代码,一个人捣鼓了半天模块别名配置,边写边测试,才慢慢明白,所有写下来当个笔记: 在vue项目中,经常根据需要引入不同的功能模块,默认情况下我们通过代码 import mod ...
- 为什么要用webpack!
为什么要用webpack? 现今的很多网页其实可以看做是功能丰富的应用,它们拥有着复杂的JavaScript代码和一大堆依赖包. 模块化,让我们可以把复杂的程序细化为小的文件; 类似于Type ...
- shell egrep 引号
[jg73178@hdcgcgdbsla01dv ~]$ egrep \'SI\' tt.txt 'SI' [jg73178@hdcgcgdbsla01dv ~]$ egrep \"SI\& ...
- Codeforces 19E&BZOJ 4424 Fairy(好题)
日常自闭(菜鸡qaq).不过开心的是看了题解之后1A了.感觉这道题非常好,必须记录一下,一方面理清下思路,一方面感觉自己还没有完全领会到这道题的精髓先记下来以后回想. 题意:给定 n 个点,m 条边的 ...
- Java的类加载器都有哪些,每个类加载器都有加载那些类,什么是双亲委派模型,是做什么的?
类加载器按照层次,从顶层到底层,分为以下三种: (1)启动类加载器(Bootstrap ClassLoader) 这个类加载器负责将存放在JAVA_HOME/lib下的,或者被-Xbootclassp ...