Redis数据类型之散列表
Redis五大数据类型以及操作
目录:
一、redis的两种链接方式
二、redis的字符串操作(string)
三、redis的列表操作(list)
四、redis的散列表操作(类似于字典里面嵌套字典)
五、redis的集合操作(set)
六、redis的有序集合操作(zset)
一、redis的两种链接方式
1、简单连接
import redis
conn = redis.Redis(host='10.0.0.200',port=6379)
conn.set('k1','年后')
print(conn.get('k1'))
2、连接池
如果要连接redis的时候推荐用连接池的方式;如果每次操作都用同一个链接,可以用连接池链接
redis使用connection pool来管理对一个redis服务的所有连接,避免每次建立,释放连接的开销。默认 ,每个redis实例都会维护一个自己的链接池。可以直接建立一个连接池,
然后作为参数redis,这样就可以实现多个redis实例共享一个连接池。

#连接池
import redis
pool = redis.ConnectionPool(host='10.0.0.200',port=6379)
conn = redis.Redis(connection_pool=pool) conn.set('a','lalla')
print(conn.get('a'))
举例
pool.py
import redis
POOL = redis.ConnectionPool(host='10.0.0.200',port=6379)
view.py
from django.shortcuts import render,HttpResponse
import redis
from app01.pool import POOL
# Create your views here.
def index(request):
pool = redis.Redis(connection_pool=POOL) #连接redis
return HttpResponse('ok') def home(request):
pool = redis.Redis(connection_pool=POOL)
return HttpResponse('ok')
3、Django-redis组件
安装:pip install django-redis
配置文件
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://10.0.0.200:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
#"PASSWORD": "asdfasdf",
}
}
}
使用:
#利用django-redis组件进行连接
from django.core.cache import caches
import os
import django_redis
os.environ['DJANGO_SETTINGS_MODULE'] = 'redis之集合练习.settings' conn = django_redis.get_redis_connection()
conn.set('b','666')
二、redis的字符串操作(string)
String操作,redis中的String在在内存中按照一个name对应一个value来存储。

1、set(name, value, ex=None, px=None, nx=False, xx=False) #设置值
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
2、setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加) #相当于只是添加,不能进行修改操作
3、setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
4、psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
5、mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mset({'k1': 'v1', 'k2': 'v2'})
6、get(name) 获取值
7、mget(keys, *args)
批量获取
如:
mget('ylr', 'zzz')
或
r.mget(['ylr', 'zzz'])
8、getset(name, value) 设置新值并获取原来的值
9、getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "拉销量" ,0-3表示 "拉"
待续。。
三、redis的列表操作(list)
四、redis的散列表操作
Hash操作,也叫做散列表操作。redis中Hash在内存中的存储格式如下图:
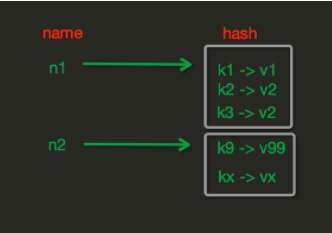
1、hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value # 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
2、hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
3、hget(name,key)
# 在name对应的hash中获取根据key获取value
4、hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3 # 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
5、hgetall(name) 获取name对应的hash中的所有键值
6、hlen(name) 获取name对应的hash中键值对的个数
7、hkeys(name) 获取name对应的hash中所有的key的值
8、hvals(name) 获取name对应的hash中所有的value的值
9、hexists(name, key) 检查name对应的hash是否存在当前传入的key
10、hdel(name,*keys) 将name对应的hash中指定key的键值对删除
11、hincrby(name, key, amount=1) 吧原来的值自加1
hincrby ('xxx','slex',amount=-1) #吧原来的值自减1
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
12、hincrbyfloat(name, key, amount=1.0) 支持浮点型的
13、hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
14、hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# for item in r.hscan_iter('xx'):
# print item
# for item in r.hscan_iter('xx',match='*lx'): #匹配以lx结尾的
# print item
五、redis的集合操作
六、redis的有序集合操作
Redis数据类型之散列表的更多相关文章
- Redis数据类型之散列类型hash
在redis中用的最多的就是hash和string类型. 问题 假设有User对象以JSON序列化的形式存储到redis中, User对象有id.username.password.age.name等 ...
- Redis数据类型之散列(hash)
1. 什么是散列 散列类似于一个字典,是一个<K, V>对的集合,不过这个key和value都只能是字符串类型的,不能嵌套,可以看做Java中的Map<String, String& ...
- redis数据类型-散列类型
Redis数据类型 散列类型 Redis是采用字典结构以键值对的形式存储数据的,而散列类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他 ...
- redis学习-散列表常用命令(hash)
redis学习-散列表常用命令(hash) hset,hmset:给指定散列表插入一个或者多个键值对 hget,hmget:获取指定散列表一个或者多个键值对的值 hgetall:获取所欲哦键值以及 ...
- Redis数据类型之列表(list)
1. 什么是列表 redis的列表使用双向链表实现,往列表中放元素的时候复杂度是O(1),但是随机访问的时候速度就不行了,因为需要先遍历到指定的位置才可以取到元素. 既然列表是使用链表实现的,那么就说 ...
- 算法导论 第十章 基本数据类型 & 第十一章 散列表(python)
更多的理论细节可以用<数据结构>严蔚敏 看几遍,数据结构很重要是实现算法的很大一部分 下面主要谈谈python怎么实现 10.1 栈和队列 栈:后进先出LIFO 队列:先进先出FIFO p ...
- Redis-cluster集群【第一篇】:redis安装及redis数据类型
Redis介绍: 一.介绍 redis 是一个开源的.使用C语言编写的.支持网络交互的.可以基于内存也可以持久化的Key-Value数据库. redis的源码非常简单,只要有时间看看谭浩强的C语言,在 ...
- redis数据类型-有序集合
有序集合类型 在集合类型的基础上有序集合类型为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入.删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高(或最低)的前N个元素.获得指 ...
- redis笔记总结之redis数据类型及常用命令
三.常用命令 3.1 字符串类型(string) 字符串类型是Redis中最基本的数据类型,一个字符串类型的键允许存储的数据的最大容量为512MB. 3.1.1 赋值与取值: SET key valu ...
随机推荐
- Selenium 2自动化测试实战16(多窗口切换)
一.多窗口切换 在页面操作过程中有时候点击某个链接会弹出新的窗口,这时就需要主机切换到新打开的窗口上进行操作.WebDriver提供了switch_to.window()方法.可以实现在不同的窗口之间 ...
- vsftp软件安装部署
1.安装vsftp yum install -y vsftpd db4-utils2.默认可以支持系统用户账号远程登录.不安全,建立虚拟账号体系为好.或者在服务器端对vsftpd.conf配置文件进行 ...
- django.db.migrations.exceptions.BadMigrationError: Migration tests in app bl
这个错误基本上都是 替换文件后才会出现的问题 因为你替换后他的日志文件没有完全替换的话,那么日志对应不到就会出现这样的问题, 一个模糊的处理办法:重新进行数据迁移:首先删除migrations中除去_ ...
- Adobe出品(支持IOS,android,web调用)免费插件编辑图片
<head runat="server"><meta http-equiv="Content-Type" content="text ...
- Linux进程后台执行nohup(OpenTSDB后台运行方法)
1.问题描述 OpenTSDB执行./tsdb tsd启动之后,占有控制台执行并且Ctrl+C后就退出了,关闭控制台同样会退出. 2.解决方法(在/opt/module/opentsdb-2.3.1/ ...
- mysql分表规则(转)
author:skatetime:2013/05/14 Mysql分表准则 在大量使用mysql时,数据量大.高访问时,为了提高性能需要分表处理,简介下mysql分表的标准,后续会继续补充 环境:业务 ...
- 洛谷 P1073 最优贸易 题解
题面 大家都是两遍SPFA吗?我这里就一遍dp啊: 首先判断对于一个点u,是否可以从一号点走到这里,并且可以从u走到n号点: 对于这样的点我们打上标记: 那么抛出水晶球的点一定是从打上标记的点中选出一 ...
- python中常见的一些错误异常类型
python提供了两个非常重要的功能来处理python程序在运行中出现的异常和错误.你可以使用该功能来调试python程序. 什么是异常? 异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的 ...
- .Net Core 认证系统源码解析
不知不觉.Net Core已经推出到3.1了,大多数以.Net为技术栈的公司也开始逐步的切换到了Core,从业也快3年多了,一直坚持着.不管环境怎么变,坚持自己的当初的选择,坚持信仰 .Net Cor ...
- ELK-全文检索技术-lucene
ELK : ELK是ElasticSearch,LogStash以及Kibana三个产品的首字母缩写 一.倒排索引 学习elk,必须先掌握倒排索引思想, 参考文档: https://www.cn ...