httprunner如何提取数据串联上下游接口
httprunner进行接口测试时,从上一个接口提取参数传递给下游接口,如何获取数据里最后一个值?
突然被学员问道一个httprunner的问题,惭愧的是大猫之前没有是通过httprunner,又不好意思说不会,只能硬着头皮去看源码了。
问题其实很简单,怎么处理我不管,反正你得给答案。看一眼同学反馈的截图,确实不难,问题很简单。请求某一个接口,接口返回的content里包含多个字段,需要获取到最后一个字典里的数据。是不是觉得很简单?
对于这么具体的问题,大猫当然是第一反应去百度啦!当然,如果能简单百度到答案,学员也不会来问我,因此,结果可想而知,百度没有标准答案!
不过百度一点用处也没有么,也不尽然,至少对于一只从来没有使用过httprunner的大猫来说,知道从响应提取数据使用extract关键字。
既然百度没有标准答案,我们就代码里找,大猫最不怕的就是看代码,大江大浪都走过来了,还能这几千行代码里翻船?
看代码先要去github把代码拉取到本地(这里就不写怎么做了),用pycharm打开,然后使用pycharm的“find in path...”进行全局查找,像这样:
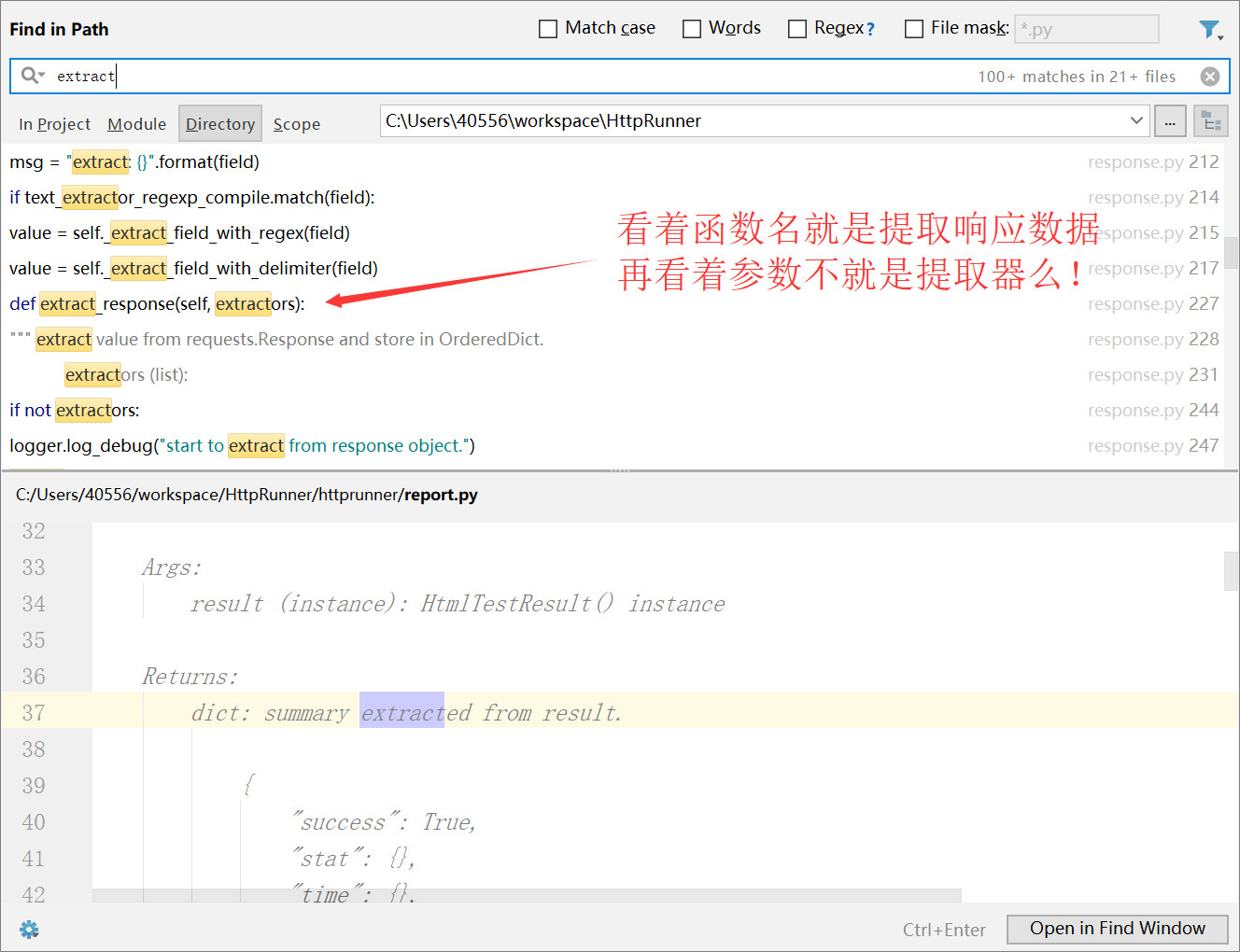
我们点击去看下代码的实现细节,没准可以发现蛛丝马迹。
if not extractors:
return {}
logger.log_debug("start to extract from response object.")
extracted_variables_mapping = OrderedDict()
extract_binds_order_dict = utils.ensure_mapping_format(extractors)
for key, field in extract_binds_order_dict.items():
extracted_variables_mapping[key] = self.extract_field(field)
return extracted_variables_mapping
代码实现相当简洁,实例化一个OrderedDict用于存储提取后的数据,采用extract_field函数来执行具体的提取数据操作。我们接着看extract_field函数。
text_extractor_regexp_compile = re.compile(r".*\(.*\).*")
if text_extractor_regexp_compile.match(field):
value = self._extract_field_with_regex(field)
else:
value = self._extract_field_with_delimiter(field)
extract_field的核心逻辑也非常简洁,采用re.compile判断表达式是否为正则,是的话执行正则表达式提取_extract_field_with_regex,如果不是正则采用分隔符提取方式,_extract_field_with_delimiter,我们需要的是分隔符方式提取,因此看_extract_field_with_delimiter函数的实现。
_extract_field_with_delimiter函数实现略微复杂,函数里对查询字符串进行了分级处理,content.person.name.first_name被分成top_query:content和sub_query:[person, name, first_name]。
同时不同的top_query有不同的处理方法,例如top_query若是status_code,encoding,ok,reason,url等则不能有sub_query,否则会抛出异常(这里和响应对象结构有关系);
if top_query in ["status_code", "encoding", "ok", "reason", "url"]:
if sub_query:
# status_code.XX
err_msg = u"Failed to extract: {}\n".format(field)
logger.log_error(err_msg)
raise exceptions.ParamsError(err_msg)
return getattr(self, top_query)
对于top_query是cookies和headers的处理,若存在sub_query则以sub_query为key进行取值,否则返回cookie或header整体。
elif top_query == "cookies":
cookies = self.cookies
if not sub_query:
# extract cookies
return cookies
try:
return cookies[sub_query]
except KeyError:
err_msg = u"Failed to extract cookie! => {}\n".format(field)
err_msg += u"response cookies: {}\n".format(cookies)
logger.log_error(err_msg)
raise exceptions.ExtractFailure(err_msg)
如果top_query是content,text或json则使用query_json函数进一步处理。当然,处理前进行了一次判断,sub_query是字典、列表还是数字。
elif top_query in ["content", "text", "json"]:
try:
body = self.json
except exceptions.JSONDecodeError:
body = self.text
if not sub_query:
# extract response body
return body
if isinstance(body, (dict, list)):
# content = {"xxx": 123}, content.xxx
return utils.query_json(body, sub_query)
elif sub_query.isdigit():
# content = "abcdefg", content.3 => d
return utils.query_json(body, sub_query)
else:
# content = "<html>abcdefg</html>", content.xxx
err_msg = u"Failed to extract attribute from response body! => {}\n".format(field)
err_msg += u"response body: {}\n".format(body)
logger.log_error(err_msg)
raise exceptions.ExtractFailure(err_msg)
query_json函数是实现取值的关键,函数使用分隔符讲sub_query切分成字符串数据,采用循环遍历数据。
for key in query.split(delimiter):
if isinstance(json_content, (list, basestring)):
json_content = json_content[int(key)] <- 这里是关键
elif isinstance(json_content, dict):
json_content = json_content[key]
else:
logger.log_error(
"invalid type value: {}({})".format(json_content, type(json_content)))
raise_flag = True
这里如果数据是列表则将key转化为数字取值,否则认为是字典直接用key取值。既然代码是转化成整形,整数有正整数,负整数和零,理论上提取数据的字符串可以有content.person.-1.name.first_name
这样的存在。这里可以理解为从content里取最后一个person的name的first_name。
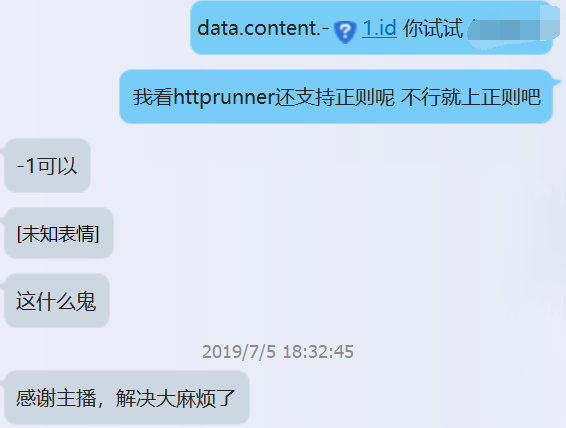
另外,这里多说一句,可以看见httprunner的代码并不难,python测开的学员应该都能看到懂,希望大家多看看开源框架的代码,提升自己的代码能力,也希望大家报名我的课程。
作 者:Testfan 大猫
出 处:微信公众号:自动化软件测试平台
版权说明:欢迎转载,但必须注明出处,并在文章页面明显位置给出文章链接
httprunner如何提取数据串联上下游接口的更多相关文章
- HttpRunner学习3--extract提取数据和引用
前言 在HttpRunner中,我们要想从当前 HTTP 请求的响应结果中提取参数,可以通过 extract 关键字来实现. 本人环境:HttpRunner V1.5.8 测试场景 在这里,我将以一个 ...
- HttpRunner学习4--使用正则表达式提取数据
前言 在HttpRunner中,我们可通过extract提取数据,当响应结果为 JSON 结构,可使用 content 结合 . 运算符的方式,如 content.code,用起来十分方便,但如果响应 ...
- scrapy框架Selector提取数据
从页面中提取数据的核心技术是HTTP文本解析,在python中常用的模块处理: BeautifulSoup 非常流行的解析库,API简单,但解析的速度慢. lxml 是一套使用c语言编写的xml解析 ...
- JMETER从JSON响应中提取数据
如果你在这里,可能是因为你需要使用JMeter从Json响应中提取变量. 好消息!您正在掌握掌握JMeter Json Extractor的权威指南.作为Rest API测试指南的补充,您将学习掌握J ...
- 如何使用JMETER从JSON响应中提取数据
如果你在这里,可能是因为你需要使用JMeter从Json响应中提取变量. 好消息!您正在掌握掌握JMeter Json Extractor的权威指南.作为Rest API测试指南的补充,您将学习掌握J ...
- 返回数据中提取数据的方法(JSON数据取其中某一个值的方法)
返回数据中提取数据的方法 比如下面的案例是,取店铺名称 接口返回数据如下: {"Code":0,"Msg":"ok","Data& ...
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
- 曲线提取数据Engauge Digitizer
可导出CSV格式数据 其它参考: http://blog.sina.com.cn/s/blog_4ae65b4d0100z8cg.html 其它曲线提取数据的软件还有: GetData.Windig ...
- 提取数据用strpos函数比较,预期和实际不符问题解决
在我提取数据时,数据是一串字符串,第一个数据和要比较的字符是相等的可是却是相反的结果 . 测试if(0==false)结果如图 执行结果 说明0和false相等.我的程序开始是这样的 第一个数据是正确 ...
随机推荐
- mesh之孔洞检测
mesh之孔洞检测 图1 检测孔洞点 图2 检测孔洞点 图3 检测孔洞点 图4 细节
- UVa 839 -- Not so Mobile(树的递归输入)
UVa 839 Not so Mobile(树的递归输入) 判断一个树状天平是否平衡,每个测试样例每行4个数 wl,dl,wr,dr,当wl*dl=wr*dr时,视为这个天平平衡,当wl或wr等于0是 ...
- ajaxfrom 和ajaxgird的区别
ajaxfrom 和ajaxgird区别ajaxfrom适合单条数据,主要是用来显示主表的信息<hy:ajaxform2 id="ajaxform" name="d ...
- nginx不记录指定文件类型日志
1.指定记录文件日志记录的内容. vim /usr/local/nginx/conf/nginx.conf如下部分: log_format dd '$remote_addr $http_x_forwa ...
- python的dict,set,list,tuple应用详解
python的dict,set,list,tuple应用详解 本文深入剖析了python中dict,set,list,tuple应用及对应示例,有助于读者对其概念及原理的掌握.具体如下: 1.字典(d ...
- ssm遇到的问题
1. Caused by: java.lang.IllegalArgumentException at org.springframework.asm.ClassReader.<init> ...
- beego框架学习(二) -路由设置
路由设置 什么是路由设置呢?前面介绍的 MVC 结构执行时,介绍过 beego 存在三种方式的路由:固定路由.正则路由.自动路由,接下来详细的讲解如何使用这三种路由. 基础路由 从beego1.2版本 ...
- Tutorial : Implementing Django Formsets
A step-by-step tutorial for setting up and testing a standard Django formset. I’ve noticed on #djang ...
- CDH日常运维
1/ 作业有问题: 查log,没log再跑一次查log. 如果没有log的情况,比如hiveserver2挂了,查strr. 2/ 查集群名字 #看hdfs集群的名字,在cdh的hdfs配置中查:na ...
- [Python3] 026 常用模块 calendar
目录 calendar 1. calendar.calendar(year, w, l, c, m) 2. calendar.prcal(year, w, l, c, m) 3. calendar.m ...