CDH搭建和集成spark、kafka操作

系统:Centos7
CDH版本:5.14.0
请自己提前安装好:mysql、jdk
并下载好相关依赖(每一台机器)
yum -y install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse portmap fuse-libs redhat-lsb
包下载:
由于是离线部署,因此需要预先下载好需要的文件。
需要准备的文件有: Cloudera Manager
文件名: cloudera-manager-centos7-cm5..0_x86_64.tar.gz
下载地址: https://archive.cloudera.com/cm5/cm/5/
CDH安装包(Parecls包)
版本号必须与Cloudera Manager相对应
下载地址: https://archive.cloudera.com/cdh5/parcels/5.14.0/
需要下载下面3个文件:
CDH-5.14.-.cdh5.14.0.p0.-el7.parcel
CDH-5.14.-.cdh5.14.0.p0.-el7.parcel.sha1
manifest.json
MySQL jdbc驱动
文件名: mysql-connector-java-.tar.gz
下载地址: https://dev.mysql.com/downloads/connector/j/
解压出: mysql-connector-java-bin.jar
步骤:
1):安装服务
所有节点上传cloudera-manager-centos7-cm5..0_x86_64.tar.gz文件并解压
# tar -zxvf cloudera-manager-centos7-cm5..0_x86_64.tar.gz -C /opt
所有节点手动创建文件夹
# mkdir /opt/cm-5.14./run/cloudera-scm-agent
所有节点创建cloudera-scm用户
# useradd --system --home=/opt/cm-5.14./run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
初始化数据库(只需要在Cloudera Manager Server节点执行)
首先需要将mysql jdbc驱动放入相应位置:
# cp /path/to/mysql-connector-java-5.1.-bin.jar /opt/cm-5.14./share/cmf/lib/
然后执行命令:
# /opt/cm-5.14./share/cmf/schema/scm_prepare_database.sh mysql -h df2 -uroot -proot --scm-host df1 scm scm scm
脚本参数说明:
${数据库类型} -h ${数据库所在节点ip/hostname} -u${数据库用户名} -p${数据库密码} –scm-host ${Cloudera Manager Server节点ip/hostname} scm scm scm
提示下面这个说明执行成功:
All done, your SCM database is configured correctly!
所有节点修改Agent配置
# vim /opt/cm-5.14./etc/cloudera-scm-agent/config.ini
将其中的server_host参数修改为Cloudera Manager Server节点的主机名
将如下文件放到Server节点的/opt/cloudera/parcel-repo/目录中:
CDH-5.14.-.cdh5.14.0.p0.-el7.parcel
CDH-5.14.-.cdh5.14.0.p0.-el7.parcel.sha1
manifest.json
重命名sha1文件
# mv CDH-5.14.-.cdh5.14.0.p0.-el7.parcel.sha1 CDH-5.14.-.cdh5.14.0.p0.-el7.parcel.sha
所有节点更改cm相关文件夹的用户及用户组
# chown -R cloudera-scm:cloudera-scm /opt/cloudera
# chown -R cloudera-scm:cloudera-scm /opt/cm-5.14.
启动Cloudera Manager
Server节点:
# /opt/cm-5.14./etc/init.d/cloudera-scm-server start
# /opt/cm-5.14./etc/init.d/cloudera-scm-agent start
其它节点:
# /opt/cm-5.14./etc/init.d/cloudera-scm-agent start
小等若干分钟,然后登陆 serverIP:7180
2):安装服务
默认账号密码:admin admin
登陆之后,在协议页面点击继续

然后选择你要安装的版本(一般都是免费的--最左侧)
然后是一个感谢页面,点击继续即可

然后选择机器
然后选择你的parcel对应版本的包:
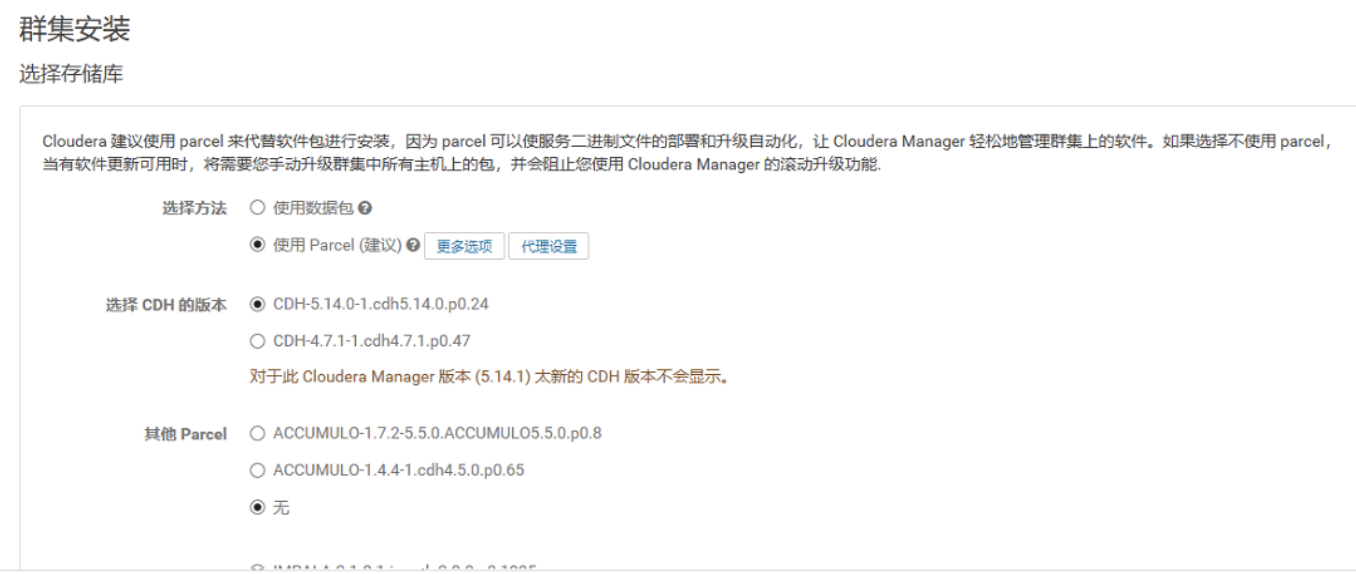
点击后,进入安装页面,稍等片刻

所有服务激活之后,点击继续 :
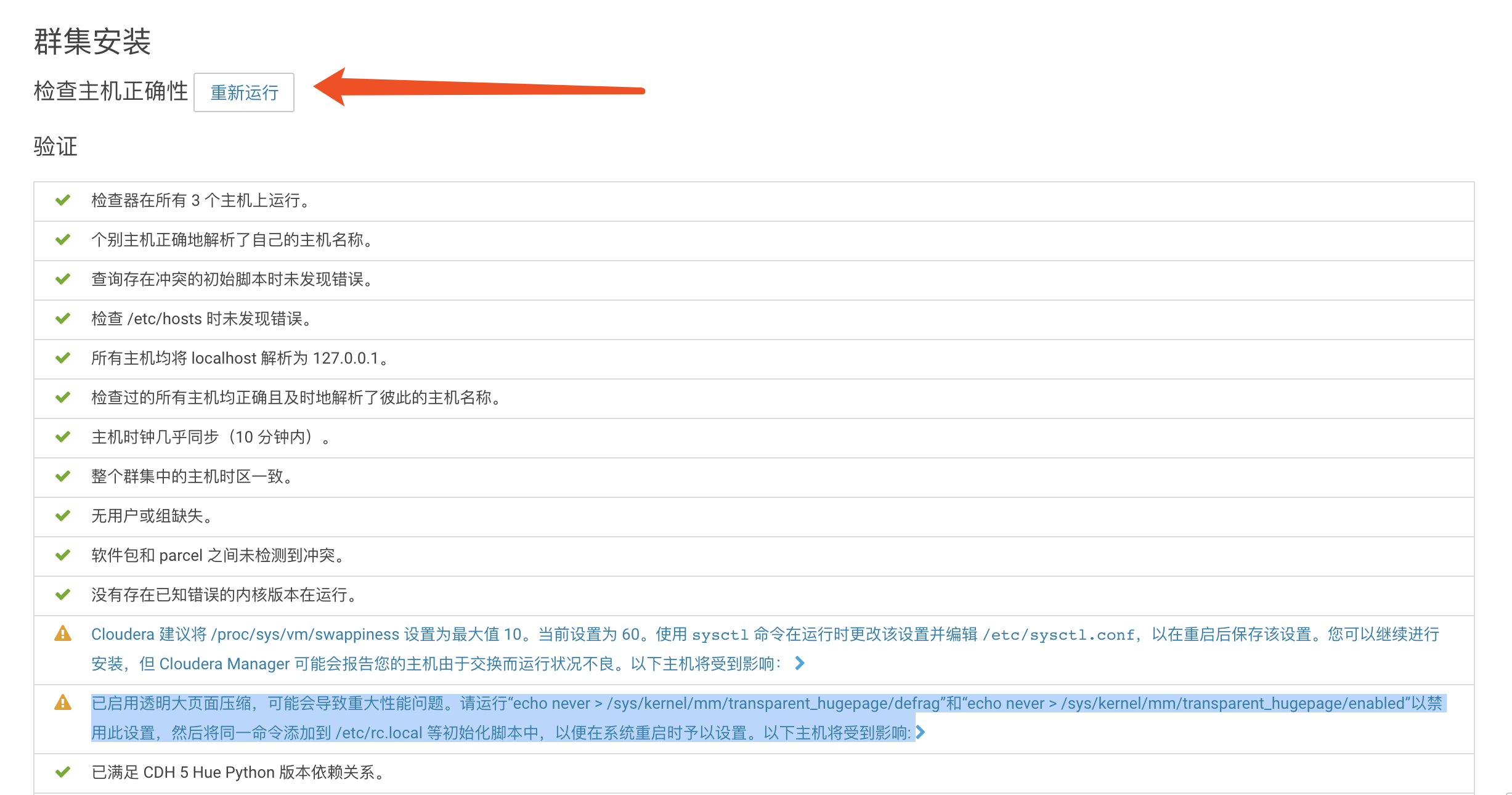
这个时候如果是第一次安装的话,那么页面不出意外会出现警告:

针对这样的警告,需要在每一台机器输入如下命令:
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo 'vm.swappiness=10'>> /etc/sysctl.conf
sysctl vm.swappiness=
然后点击重新运行,不出以为,就不会在出现警告了
然后点击继续,就进入hadoop这些软件的安装页面了,那么在安装之前,如果涉及到hive和oozie的安装,那么去mysql中,自己创建数据库,并赋予权限;
因为用root权限去作为hive的元数据库,容易出错的
因此:
grant all on *.* to hive identified by 'hive';
grant all on *.* to oozie identified by 'oozie';
create database hive;
create database oozie;
这样在安装软件!
比如,我要安装:hdfs 、yarn、hive、zookeeper、hbase、kafka(后续增加)
那么,选择自定义服务
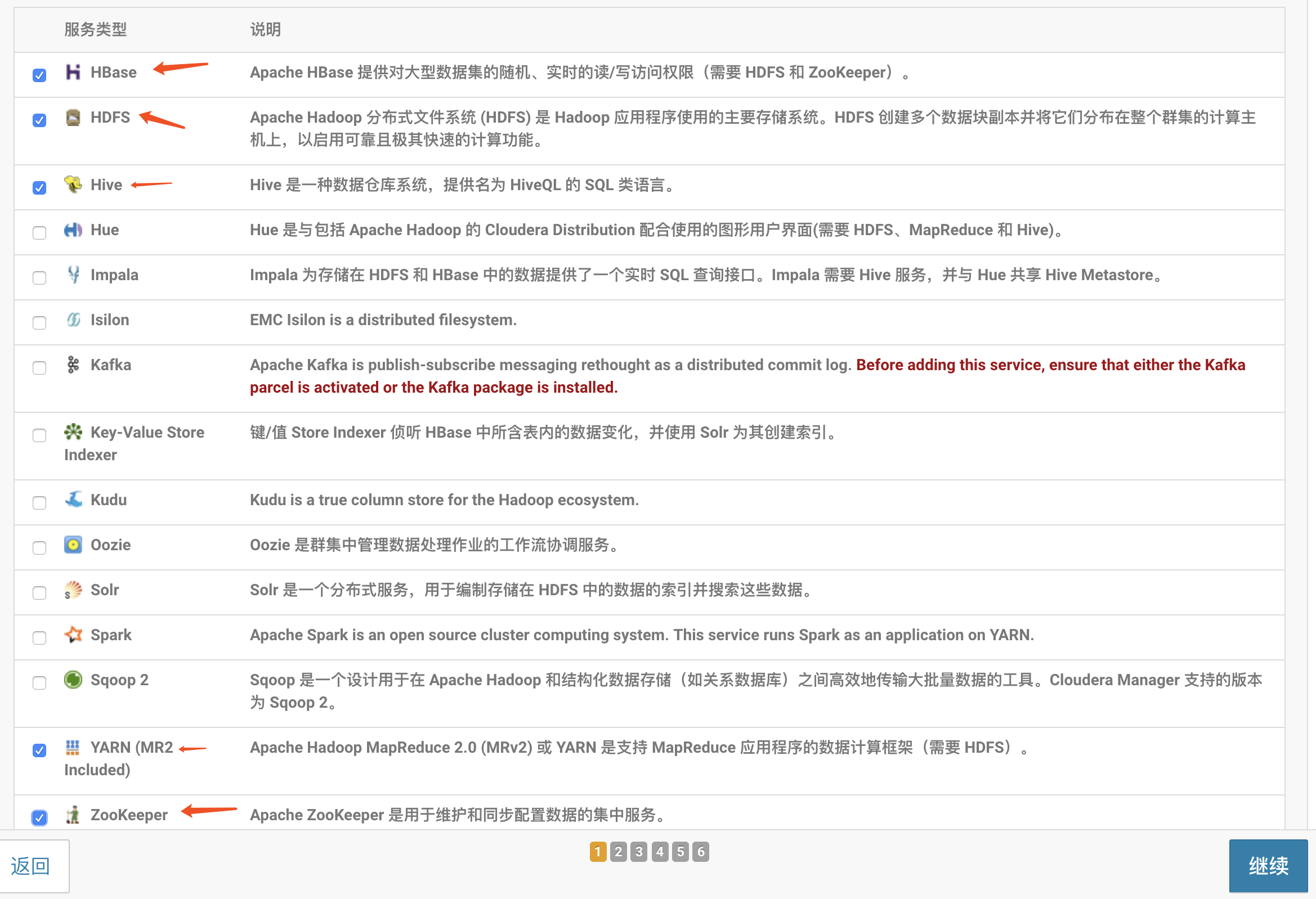
然后点击继续,进入选择服务添加分配页面,分配即可
然后点击继续,输入hive的元数据的库、用户、密码:
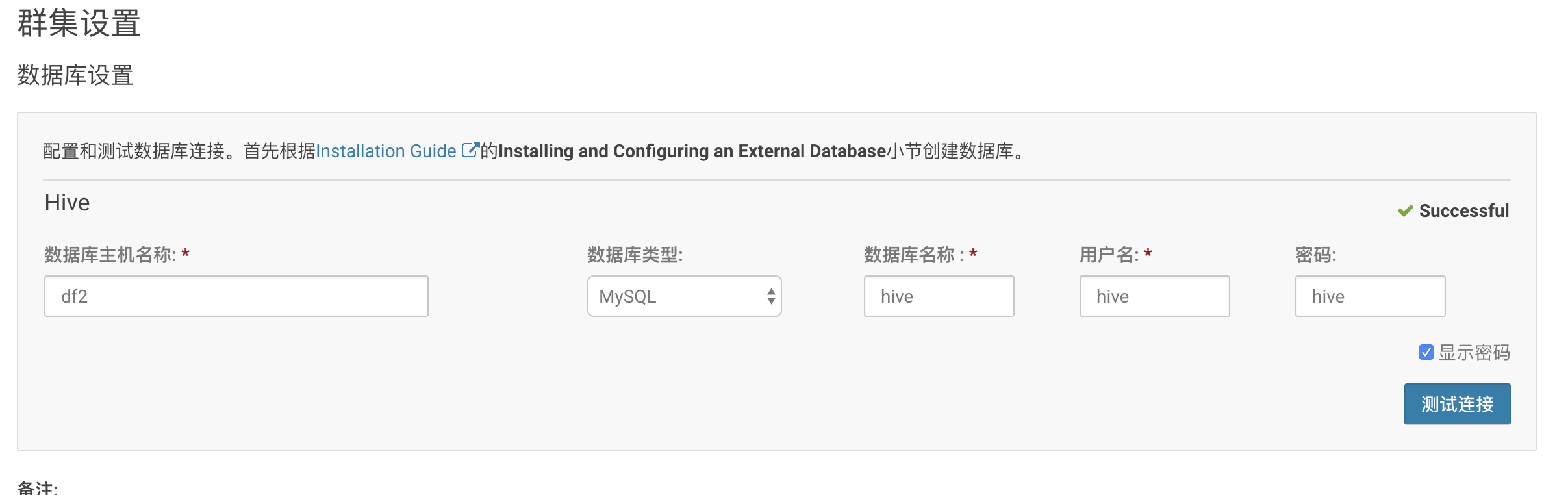
注意:在点击继续之前,需要在每一安装hive的那台服务器上,把mysql的驱动包放入hive的lib下
cp mysql-connector-java.jar /opt/cloudera/parcels/CDH-5.14.-.cdh5.14.0.p0./lib/hive/lib/
然后一路无脑继续,剩下的就是等待
集成spark
CDH版本是5.14.0
spark安装版本是:2.1.0
包下载:
CSD包下载 http://archive.cloudera.com/spark2/csd/
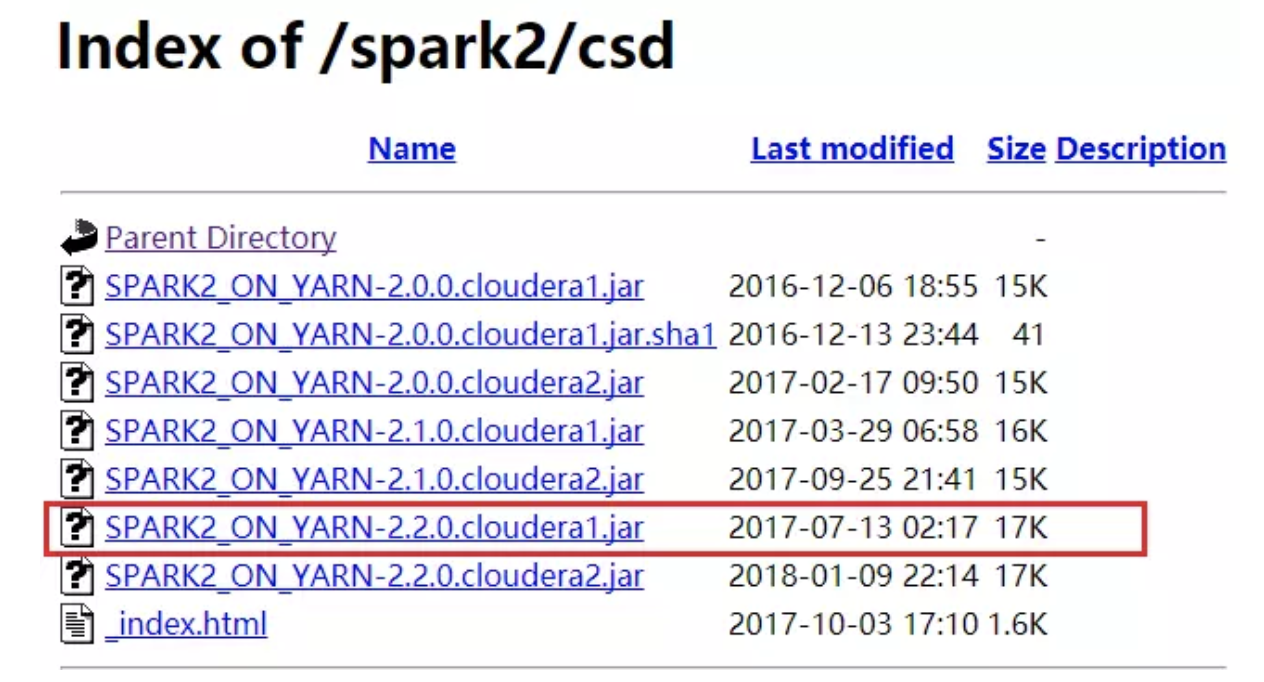
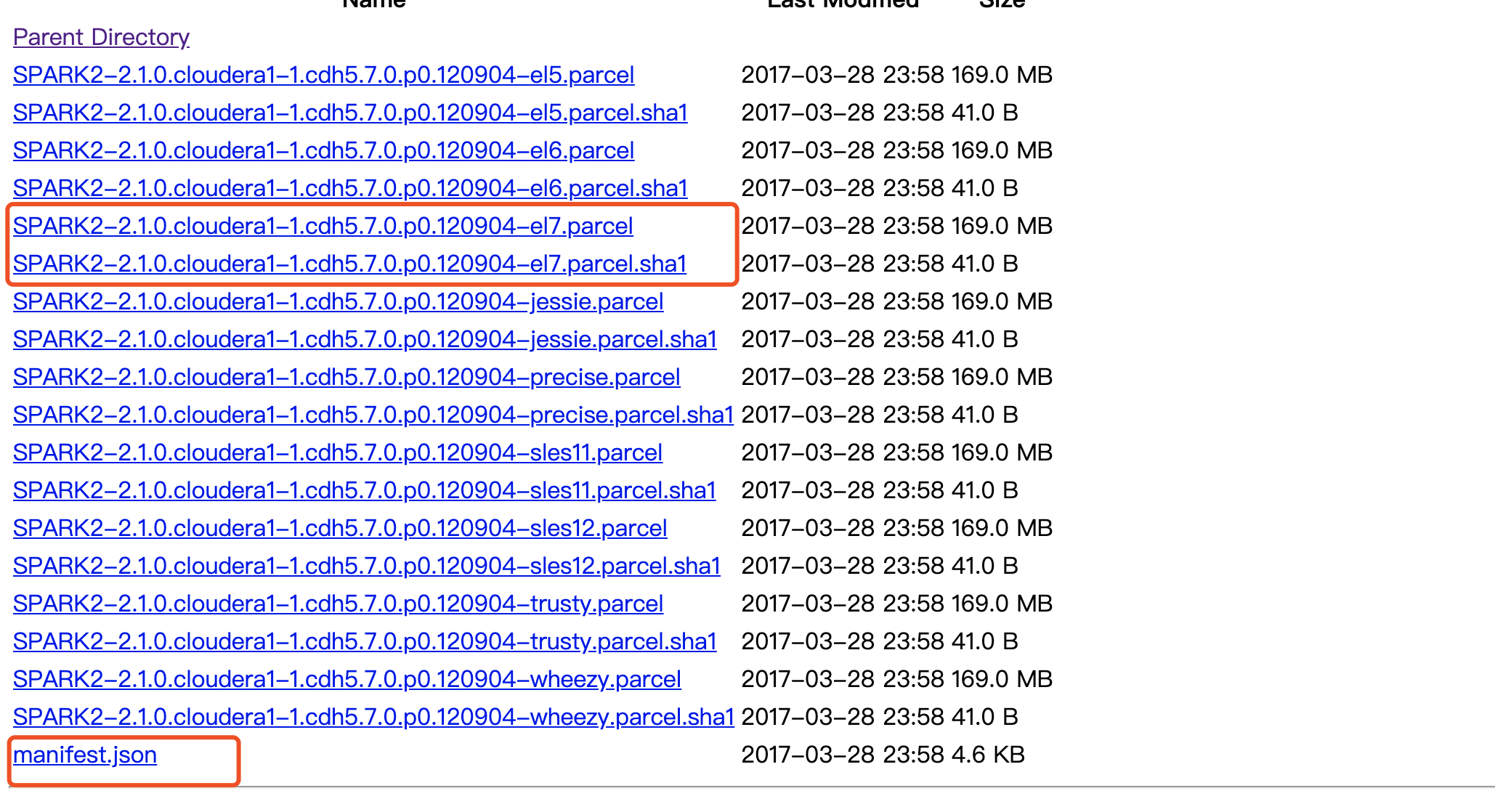
parcel包下载 http://archive.cloudera.com/spark2/parcels/
安装spark2
在所有节点进行下面操作
上传CSD包到机器的/opt/cloudera/csd目录。注意如果本目录下有其他的jar包,把删掉或者移到其他目录
修改SPARK_ON_YARN-2.2..cloudera1.jar的用户和组
chown cloudera-scm:cloudera-scm SPARK_ON_YARN-2.1..cloudera1.jar
将parcel包上传到机器的/opt/cloudera/parcel-repo目录。注意: 如果有其他的安装包,不用删除 ,但是如果本目录下有其他的重名文件比如manifest.json文件,把它重命名备份掉。然后把那3个parcel包的文件放在这里。
停掉CM和集群,现在将他们停掉。然后运行命令
service cloudera-scm-agent restart
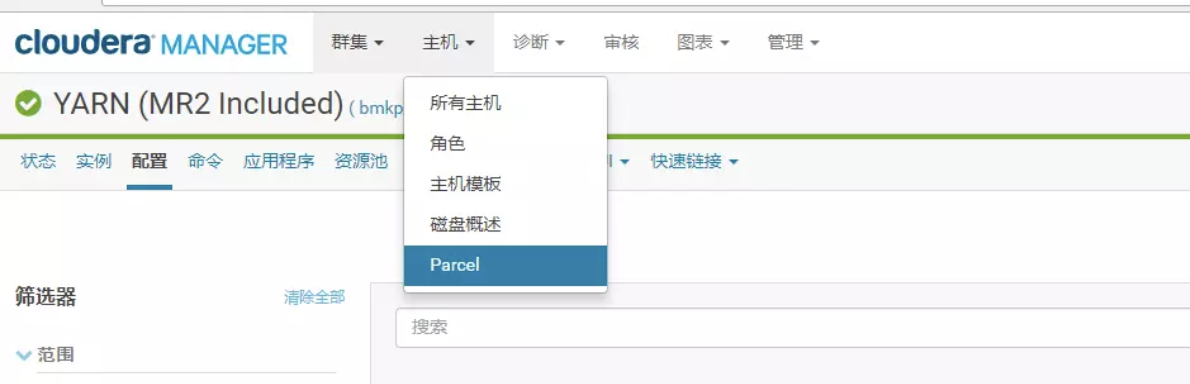
service cloudera-scm-server restart 把CM和集群启动起来。然后点击主机->Parcel页面,看是否多了个spark2的选项。如下图,你这里此时应该是分配按钮,点击,等待操作完成后,点击激活按钮
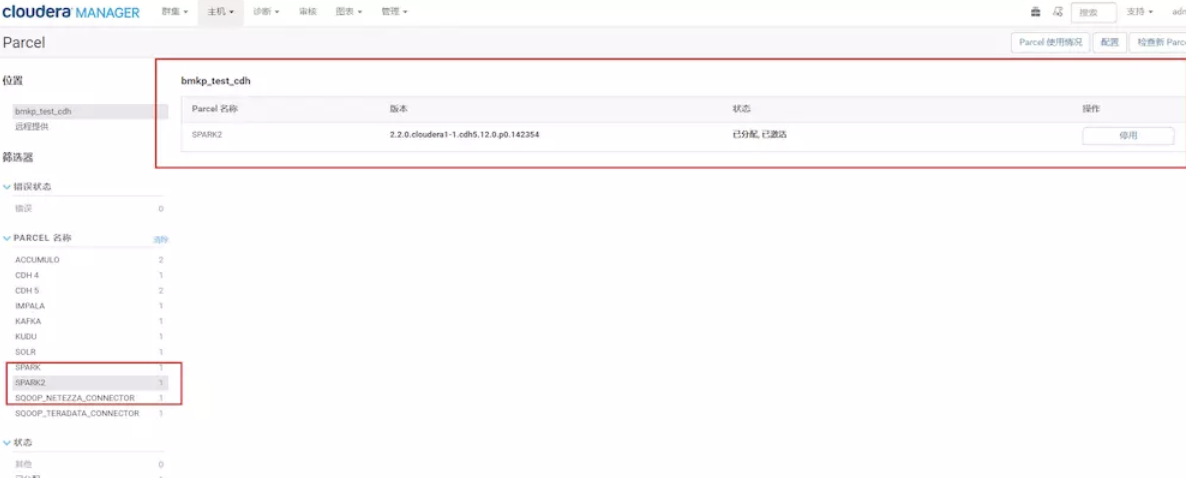
还要注意的是:在spark historyserver这台机器上,创建本队文件夹路径,并赋予权限,不然你的sparkhistory是启动不了的
[root@df3 csd]# mkdir -p /user/spark/spark2ApplicationHistory
[root@df3 csd]# chown -R spark:spark /user/spark
激活后,点击你的群集-》添加服务,添加spark2服务。注意,如果你这里看不到spark2服务,就请检查你的CSD包和parcel包是否对应,上面的步骤是否有漏掉。正常情况下,应该是能用了。
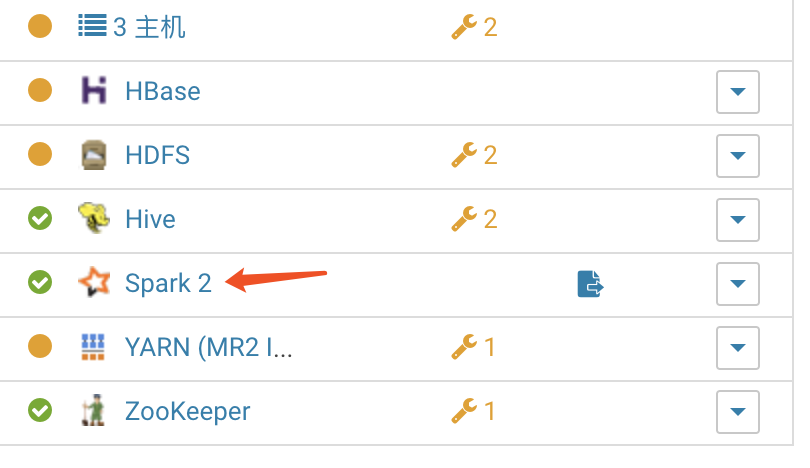
集成kafka
首先查看搭建cdh版本 和kafka版本,是否是支持的:
登录如下网址:
https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html#pcm_kafka
我的CDH版本是cdh5.14.0 ,我想要的kafka版本是1.0.1
因此选择:
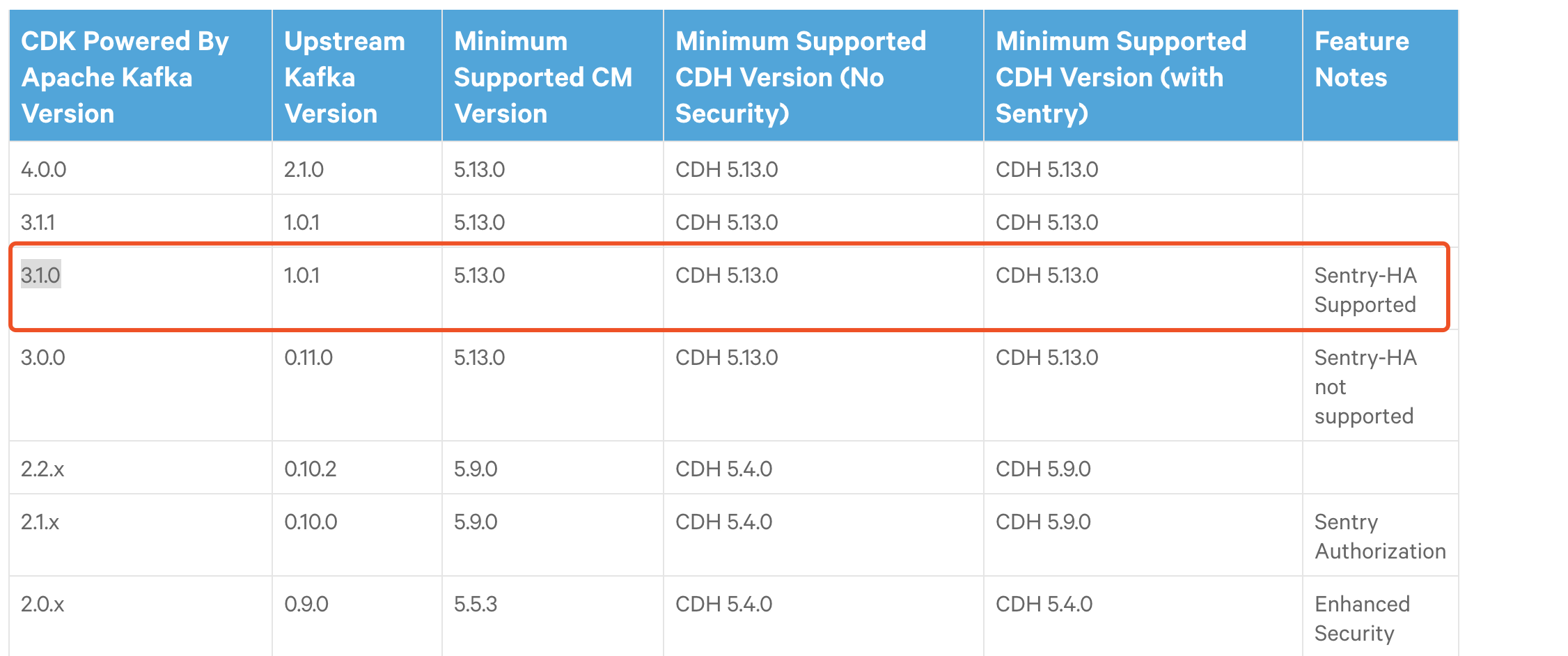
然后下载:http://archive.cloudera.com/kafka/parcels/3.1.0/

注意:需要将KAFKA-3.1.0-1.3.1.0.p0.35-el7.parcel.sha1 改成 KAFKA-3.1.0-1.3.1.0.p0.35-el7.parcel.sha
mv KAFKA-3.1.-1.3.1.0.p0.-el7.parcel.sha1 KAFKA-3.1.-1.3.1.0.p0.-el7.parcel.sha
然后替换一下KAFKA-3.1.0-1.3.1.0.p0.35-el7.parcel.sha这个文件的hash值,指定我们下载的parcel包
打开 manifest.json
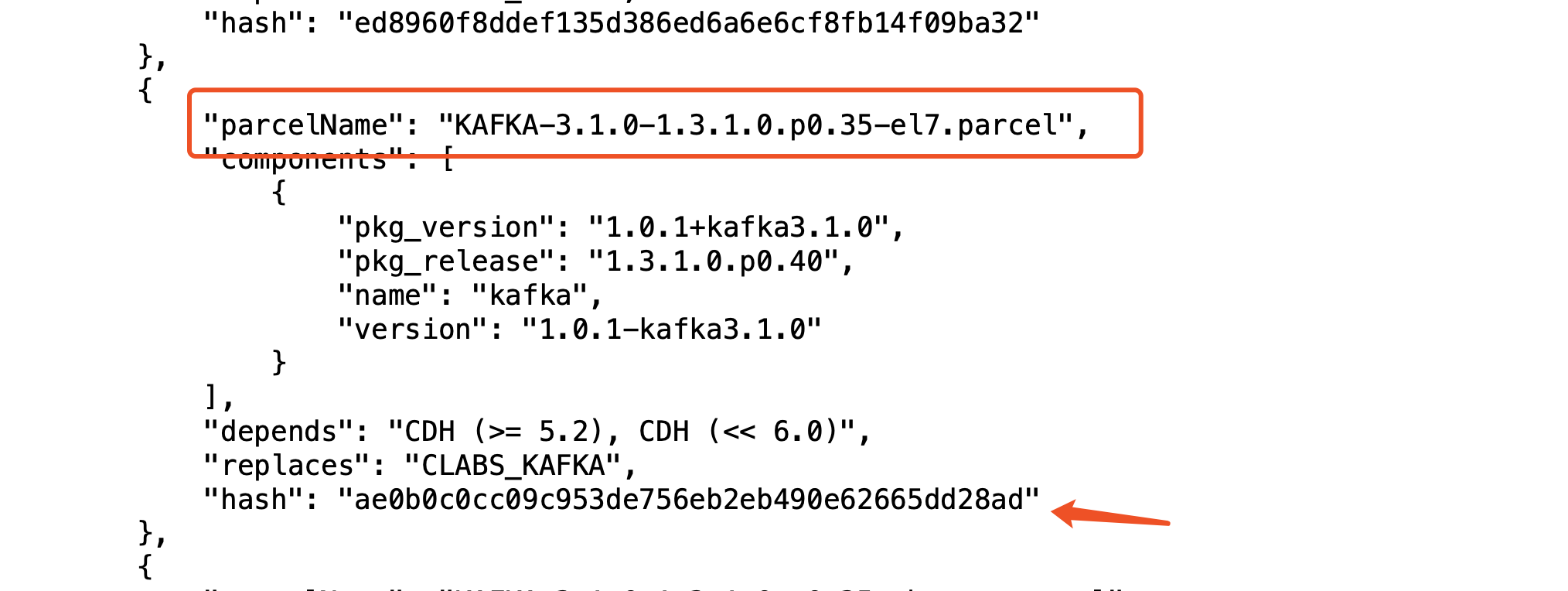
替换到:KAFKA-3.1.0-1.3.1.0.p0.35-el7.parcel.sha
[root@df1 kafka_parcel]# cat KAFKA-3.1.-1.3.1.0.p0.-el7.parcel.sha
ae0b0c0cc09c953de756eb2eb490e62665dd28ad
[root@df1 kafka_parcel]#
然后将这三个文件,拷贝到parcel-repo目录下。如果有相同的文件,即manifest.json,只需将之前的重命名即可。
cd /opt/cloudera/parcel-repo/
mv manifest.json manifest.json.bak2
[root@df1 ~]# cp kafka_parcel/* /opt/cloudera/parcel-repo/
下载Kafka-1.2.0.jar
下载网址:http://archive.cloudera.com/csds/kafka/
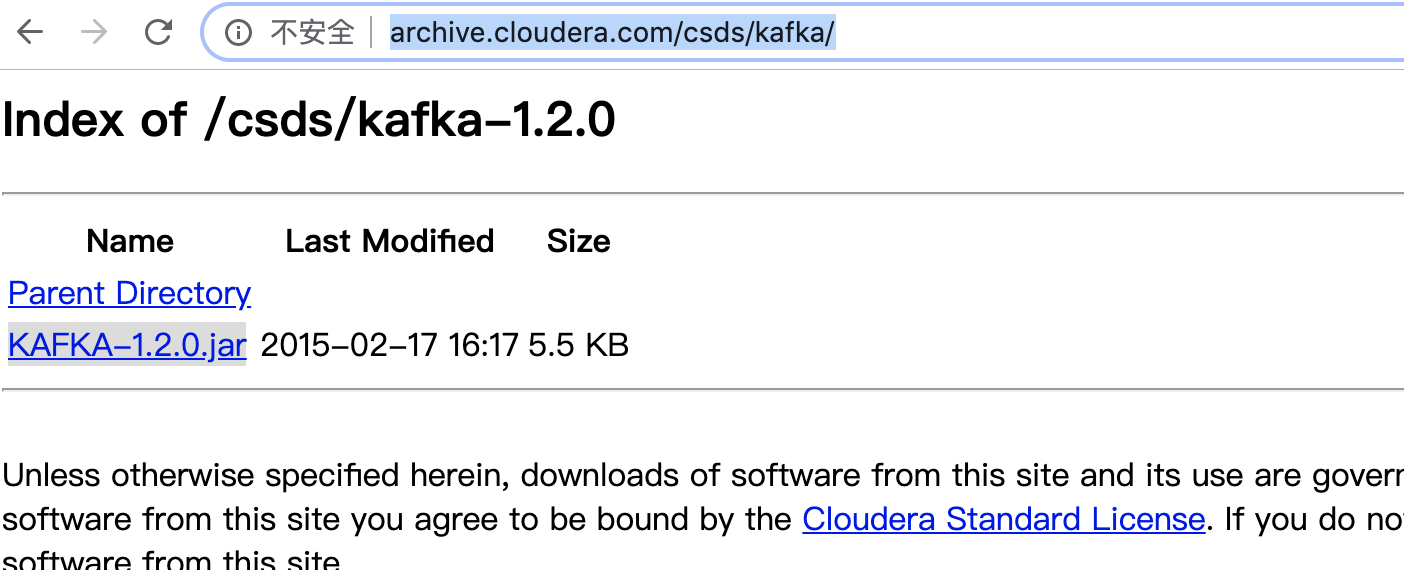
将下载的包上传到:/opt/cloudera/csd , 并修改权限

1:先重启服务
2:然后像集成spark一样,分配和激活kafka
进入CDH的管理界面,点击主机->parcel->检查新parcel
然后多按几下检查parel更新
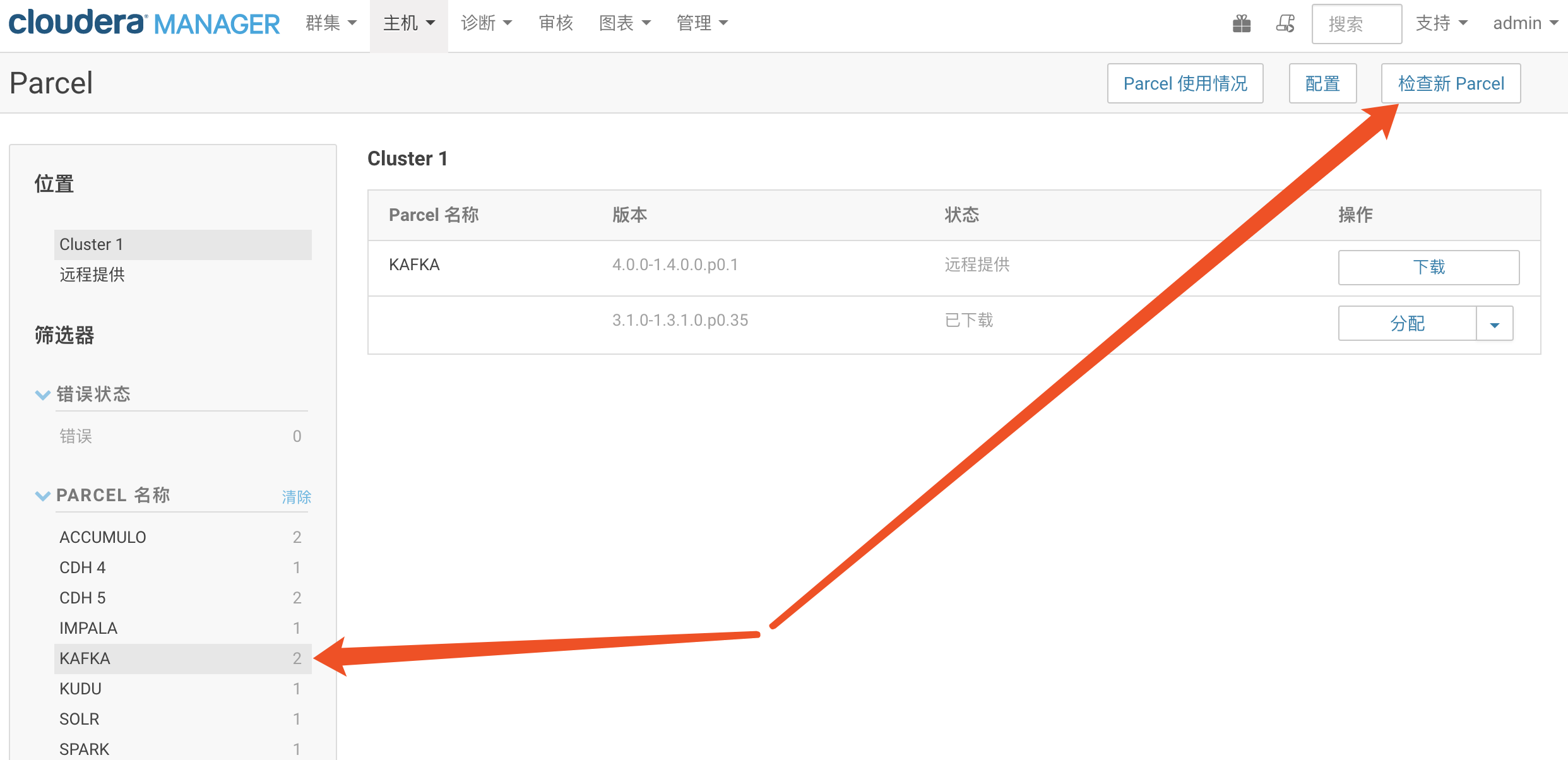
点击分配:

点击分配,等待,然后分配按钮编程激活按钮,点击激活,等待

激活之后,回到主页添加服务,把kafka添加进来就可以了
然后kafka在启动中肯定会报错,因为默认broker最低内存是1G
但是CDH给调节成50M了
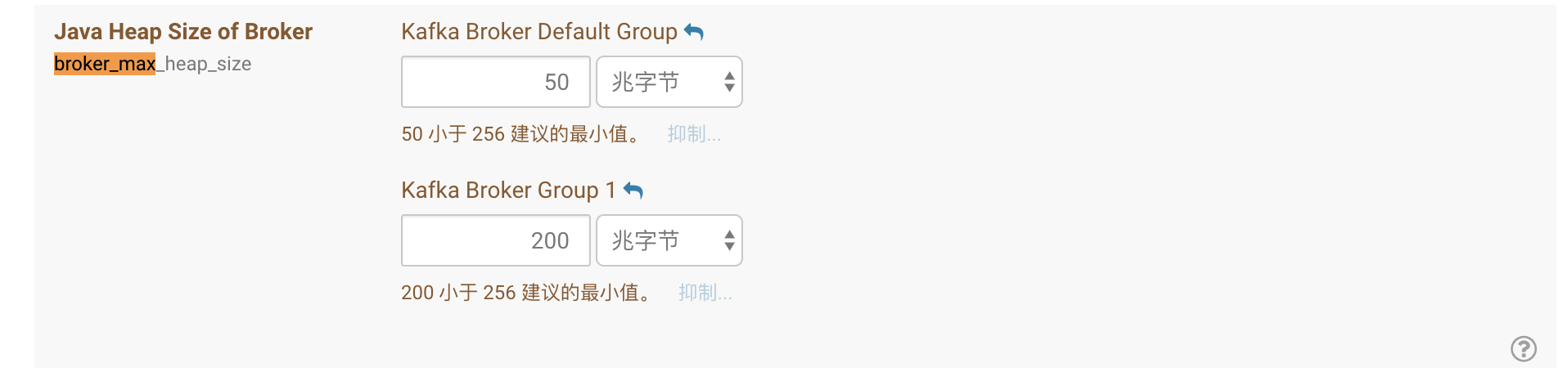
因此调整过来

最后:
CDH搭建和集成spark、kafka操作的更多相关文章
- CDH集群集成kafka
搭建要求: 1.CDH环境已经搭建成功,在CDH上搭建kafka.要求用CDH上zookeeper管理kafka而不用kafka自带的zookeeper 2.kafka_2.11-0.8.2.1.tg ...
- 基于CDH 5.9.1 搭建 Hive on Spark 及相关配置和调优
Hive默认使用的计算框架是MapReduce,在我们使用Hive的时候通过写SQL语句,Hive会自动将SQL语句转化成MapReduce作业去执行,但是MapReduce的执行速度远差与Spark ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- Structured Streaming + Kafka Integration Guide 结构化流+Kafka集成指南 (Kafka broker version 0.10.0 or higher)
用于Kafka 0.10的结构化流集成从Kafka读取数据并将数据写入到Kafka. 1. Linking 对于使用SBT/Maven项目定义的Scala/Java应用程序,用以下工件artifact ...
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 使用IntelliJ IDEA 13搭建Android集成开发环境(图文教程)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/ ...
- 使用Android Studio搭建Android集成开发环境(图文教程)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/ ...
- 用MSBuild和Jenkins搭建持续集成环境(2)
http://www.infoq.com/cn/articles/MSBuild-2 作者 Mustafa Saeed Haji Ali ,译者 李剑 发布于 2012年10月23日 | 注意: ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
随机推荐
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- noip2013day1-货车运输
题目描述 \(A\)国有\(n\)座城市,编号从 \(1\)到\(n\),城市之间有 \(m\) 条双向道路.每一条道路对车辆都有重量限制,简称限重.现在有 \(q\) 辆货车在运输货物, 司机们想知 ...
- Nginx与PHP如何协同工作
要说Nginx与PHP如何协同工作,首先得说CGI和FastCGI两个协议. CGI是Web Server与后台语言交互的协议,有了这个协议,开发者可以使用任何语言处理Web Server发来的请求, ...
- python中判断字典中是否存在某个键
python3 中采用 in 方法 #判断字典中某个键是否存在 arr = {"int":"整数","float":"浮点&quo ...
- centos 6.x 编译安装 pgsql 9.6
文章结构如下: 一. 环境配置 1. 配置防火墙 查看IPTABLES 当前状态与关闭过程 chkconfig --list|grep iptables 关闭iptables service ipta ...
- 经典Spring入门基础教程详解
经典Spring入门基础教程详解 https://pan.baidu.com/s/1c016cI#list/path=%2Fsharelink2319398594-201713320584085%2F ...
- 关于导航自定义视图距离边界问题,点击状态栏TableView不能回滚到顶部问题
一: 默认Navigation的自定义customView,设置为 Left or Right BarButtonItem 的时候会 与屏幕边界有个15像素的距离. 导致自定义视图的上的子视图响应区域 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-7 内存性能优化
内存优化是最重要也是最有效的OpenCL性能优化技术.大量的应用程序是内存限制而不是计算限制.所以,掌握内存优化的方法是OpenCL优化的基础.在这章中,将会回顾OpenCL的内存模型,然后是最优的实 ...
- liunx weblogic服务启停脚本
#!/bin/bash #sh xx.sh start xx项目 例如:sh autoWeblogic.sh start bius #经测试发现weblogic 启动大概需要完全启动成功35秒左右 停 ...
- git 合并某个分支指定的文件
$ git checkout <another-branch> <path-to-file> [<one-more-file> ...] $ git status ...