使用filebeat收集日志传输到redis的各种效果展示
0 环境
Linux主机,cengtos7系统
安装有openresty软件,用来访问生成日志信息 1.15.8版本
安装有filebeat软件,用来收集openresty的日志 7.3版本
安装有redis软件,用来接收filebeat发送过来的日志,5.0.5版本
fields_under_root的值默认是false
1. filebeat.yml配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/openresty/nginx/logs/host.access.log
fields:
log_source: messages
fields_under_root: true
output.redis:
hosts: ["192.168.0.142:6379"]
key: nginx_log
password: foobar2000
db: 0
如下参数的效果
fields:
log_source: messages
fields_under_root: true
使用fields表示在filebeat收集的日志中多增加一个字段log_source,其值是messages,用来在logstash的output输出到elasticsearch中判断日志的来源,从而建立相应的索引
若fields_under_root设置为true,表示上面新增的字段是顶级参数,在redis中查看的话效果如下:
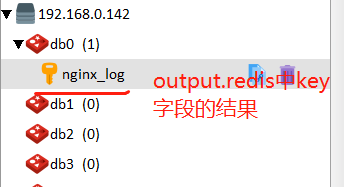
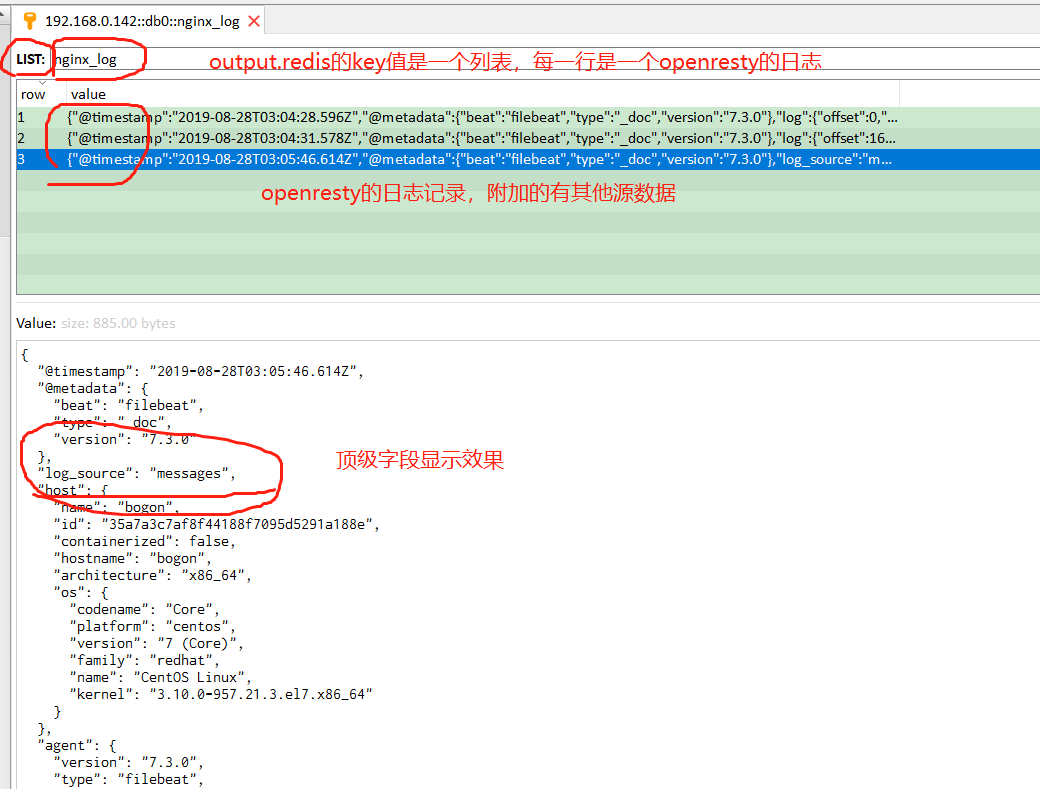
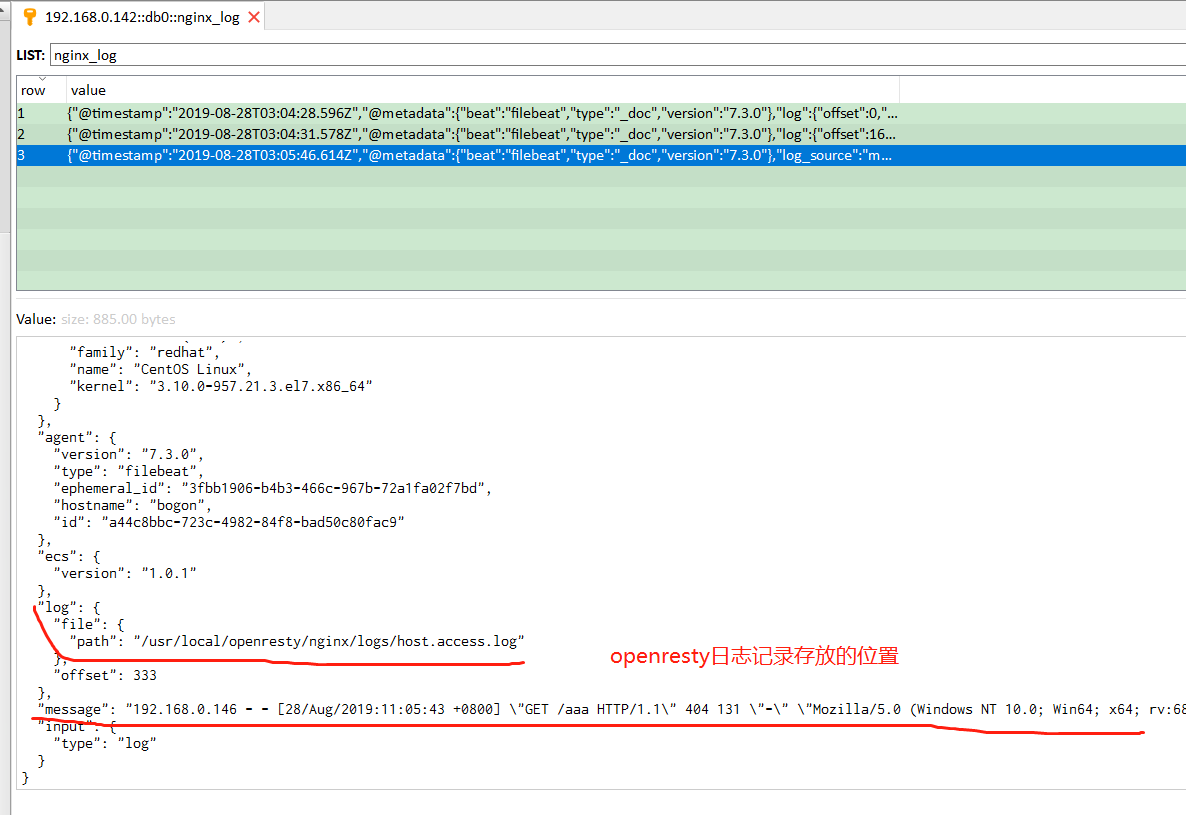
顶级字段在output输出到elasticsearch中的使用如下:
output {
# 根据redis键 messages_secure 对应的列表值中,每一行数据的其中一个参数来判断日志来源
if [log_source] == 'messages' { # 注意判断条件的写法
elasticsearch {
hosts => ["http://192.168.80.104:9200"]
index => "filebeat-message-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "elastic123"
}
}
}
若fields_under_root设置为false,表示上面新增的字段是则是fields的二级字段,在redis中查看的话效果如下:

fields二级字段在output输出到elasticsearch中的使用如下:
output {
# 根据redis键 messages_secure 对应的列表值中,每一行数据的其中一个参数来判断日志来源
if [fields][log_source] == 'messages' { # 注意判断条件的写法
elasticsearch {
hosts => ["http://192.168.80.104:9200"]
index => "filebeat-message-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "elastic123"
}
}
}
2. 若是多个应用的日志都输出到redis中,只需要在filebeat.inputs:下面再新增- type: log段就行,如下所示:
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/openresty/nginx/logs/host.access.log # 假设应用1的日志路径
fields:
log_source: messages # logstash判断日志来源
### 新增的###
- type: log
enabled: true
paths:
- /usr/local/openresty/nginx/logs/error.log # 假设应用2的日志路径
fields:
log_source: secure
### 新增的###
output.redis:
hosts: ["192.168.80.107:6379"]
key: messages_secure
password: foobar2000
db: 0
在redis中显示的效果是都会输出到key值对应的列表中,根据key值是没法进行区分的,只能根据key值列表中每一行数据中的log_source来判断该行是哪一个应用的日志
3. 不同的应用日志使用不同的rediskey值
使用output.redis中的keys值,官方例子
output.redis:
hosts: ["localhost"]
key: "default_list"
keys:
- key: "error_list" # send to info_list if `message` field contains INFO
when.contains:
message: "error"
- key: "debug_list" # send to debug_list if `message` field contains DEBUG
when.contains:
message: "DEBUG"
- key: "%{[fields.list]}"
mappings:
http: "frontend_list"
nginx: "frontend_list"
mysql: "backend_list"
大致意思是说,默认的key值是default_list,keys的值是动态分配创建的,当redis接收到的日志中message字段的值包含有INFO字段,则创建key为info_list,当包含有DEBUG字段,则创建key为debug_list。
问题的解决方法是在每个应用的输出日志中新增一个能够区分这个日志的值,然后再在keys中设置,这样一来就能够把不同应用的日志输出到不同的redis的key中
mappings这个还没看懂啥意思,删除mappings这几行也可以
redis中的效果显示:根据官方例子实际修改了一下参数

顺带拓展一下这个内容,logstash7.3从redis中拉取日志时也需要设置这个key值
filebeat这边是动态生成的key值,那logstash中要如何设置这个?
解决办法:
logstash设置的话时需要在目录/etc/logstash/conf.d下面创建以.conf结尾的文件
可以创建多个这样的conf文件,每个文件中从redis取值的设置key值都不同,具体来说就是根据filebeat动态生成的key值设置,然后再输出到相应的elasticsearch中创建不同的索引
拓展一下:假设使用的是nginx,部署多个项目,监控每个项目的access访问文件
ngixn中access日志格式log_format只能配置在http段,若是修改这个的话那所有的项目访问日志还是在同一个redis的key中,
那要如何才能在监控nginx下多个项目的access访问日志下使用redis的不同key值?
暂时还没想好咋解决这个问题
使用filebeat收集日志传输到redis的各种效果展示的更多相关文章
- filebeat收集日志传输到Redis集群,logstash从Redis集群中拉取数据
前提:已配置好Redis集群,并设置的有统一的访问密码 架构是filebeat-->redis集群-->logstash->elasticsearch,需要修改filebeat的输出 ...
- 使用filebeat收集不同用应用的日志传输到redis,并加以区分
附加技巧 步骤流程: 使用filebeat收集一台主机上两个不同应用的日志,传递给redis,然后logstash从redis中拉去数据传递给elasticsearch 1.filebeat.yml文 ...
- filebeat收集日志到elsticsearch中并使用ingest node的pipeline处理
filebeat收集日志到elsticsearch中 一.需求 二.实现 1.filebeat.yml 配置文件的编写 2.创建自定义的索引模板 3.加密连接到es用户的密码 1.创建keystore ...
- 第十一章·Filebeat-使用Filebeat收集日志
Filebeat介绍及部署 Filebeat介绍 Filebeat附带预构建的模块,这些模块包含收集.解析.充实和可视化各种日志文件格式数据所需的配置,每个Filebeat模块由一个或多个文件集组成, ...
- ELK日志方案--使用Filebeat收集日志并输出到Kafka
1,Filebeat简介 Filebeat是一个使用Go语言实现的轻量型日志采集器.在微服务体系中他与微服务部署在一起收集微服务产生的日志并推送到ELK. 在我们的架构设计中Kafka负责微服务和EL ...
- elk-日志方案--使用Filebeat收集日志并输出到Kafka
1,Filebeat简介 Filebeat是一个使用Go语言实现的轻量型日志采集器.在微服务体系中他与微服务部署在一起收集微服务产生的日志并推送到ELK. 在我们的架构设计中Kafka负责微服务和 ...
- .Nginx安装filebeat收集日志:
1.安装filebeat: [root@nginx ~]# vim /usr/local/filebeat/filebeat.yml [root@nginx ~]# tar xf filebeat-6 ...
- ELK之在windows安装filebeat收集日志
登录官方网站下载filebeat的windows客户端 https://www.elastic.co/downloads/beats 下载压缩包,无需解压 修改配置文件filebeat.yml 其余设 ...
- ELK学习实验016:filebeat收集tomcat日志
filebeat收集tomcat日志 1 安装tomcat [root@node4 ~]# yum -y install tomcat tomcat-webapps tomcat-admin-weba ...
随机推荐
- [LOJ3124][CTS2019|CTSC2019]氪金手游:树形DP+概率DP+容斥原理
分析 首先容易得出这样一个事实,在若干物品中最先被选出的是编号为\(i\)的物品的概率为\(\frac{W_i}{\sum_{j=1}^{cnt}W_j}\). 假设树是一棵外向树,即父亲比儿子先选( ...
- ...扩展运算符+rest参数+call/apply/bind
之前在set,map里面有提过扩展运算符的概念,但是今天偶然遇到一个问题,类似于扩展运算符的经典用法,突然发现对其了解不是很深,所以再来整理一下扩展运算符的相关知识. 重点:扩展运算符内部调用的是数据 ...
- git多人参与的项目 -> 分支代码如何合并到主干
个人理解:合并分支时候就是当前分支,与别的分支先合并一遍,然后解决分支中存在的所有冲突,之后将本地分支代码提交到git远程仓库,之后切换主干分支 ,将主干分支与分支内容合并,解决冲突, 在提交主干分支 ...
- RocketMQ消息发送流程和高可用设计
(源码阅读先看主线 再看支线 先点到为止 后面再详细分解) 高可用的设计就是:当producer发送消息到broker上,broker却宕机,那下一次发送如何避免发送到这个broker上,就是采用La ...
- 【攻克RabbitMQ】常见问题
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/zlt995768025/article/ ...
- 数组 Kotlin(5)
数组 数组在 Kotlin 中使用 Array 类来表示,它定义了 get 和 set 函数(按照运算符重载约定这会转变为 [] ) 和 size 属性,以及一些其他有用的成员函数:基本类型 clas ...
- Oracle_Windows server ORA-01031: insufficient privileges
PS C:\Users\admin> sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on 星期二 9月 3 10:21: ...
- JavaEE-实验二 Java集合框架实验
该博客仅专为我的小伙伴提供参考而附加,没空加上代码具体解析,望各位谅解 1. 使用类String类的分割split 将字符串 “Solutions to selected exercises ca ...
- 安装MySQL Enterprise Monitor
MySQL Enterprise Monitor是专门为MySQL数据库而设计的一款企业级监控,能非常好地与MySQL各方面特性相结合,包括:MySQL的关键性能指标.主机.磁 盘.备份.新特性相关以 ...
- linux配置多个ip
linux配置多个ip /sbin/ifconfig eth0:1 172.19.121.180 broadcast 172.19.121.255 netmask 255.255.255.0 up ...