浅谈chainer框架
一 chainer基础
Chainer是一个专门为高效研究和开发深度学习算法而设计的开源框架。 这篇博文会通过一些例子简要地介绍一下Chainer,同时把它与其他一些框架做比较,比如Caffe、Theano、Torch和Tensorflow。
大多数现有的深度学习框架是在模型训练之前构建计算图。 这种方法是相当简单明了的,特别是对于结构固定且分层的神经网络(比如卷积神经网络)的实现。
然而,现在的复杂神经网络(比如循环神经网络或随机神经网络)带来了新的性能改进和新的应用。虽然现有的框架可以用于实现这些复杂神经网络,但是它们有时需要一些(不优雅的)编程技巧,这可能会降低代码的开发效率和可维护性。
而Chainer的方法是独一无二的:即在训练时“实时”构建计算图。
这种方法可以让用户在每次迭代时或者对每个样本根据条件更改计算图。同时也很容易使用标准调试器和分析器来调试和重构基于Chainer的代码,因为Chainer使用纯Python和NumPy提供了一个命令式的API。 这为复杂神经网络的实现提供了更大的灵活性,同时又加快了迭代速度,提高了快速实现最新深度学习算法的能力。
以下我会介绍Chainer是如何工作的,以及用户可以从中获得什么样的好处。
Chainer 是一个基于Python的独立的深度学习框架。
不同于其它基于Python接口的框架(比如Theano和TensorFlow),Chainer通过支持兼容Numpy的数组间运算的方式,提供了声明神经网络的命令式方法。Chainer 还包括一个名为CuPy的基于GPU的数值计算库。
>>> from chainer import Variable
>>> import numpy as np
Variable 类是把numpy.ndarray数组包装在内的计算模块(numpy.ndarray存放在.data中)。
>>> x = Variable(np.asarray([[0, 2],[1, -3]]).astype(np.float32))
>>> print(x.data)
[[ 0. 2.]
[ 1. -3.]]
用户可以直接在Variables上定义各种运算和函数(Function的实例)。
>>> y = x ** 2 – x + 1
>>> print(y.data)
[[ 1. 3.]
[ 1. 13.]]
因为这些新定义的Varriable类知道他们是由什么类生成的,所以Variable y跟它的父类有一样的加法运算(.creator)。
>>> print(y.creator)
<chainer.functions.math.basic_math.AddConstant at 0x7f939XXXXX>
利用这种机制,可以通过反向追踪从最终损失函数到输入的完整路径来实现反向计算。完整路径在执行正向计算的过程中存储,而不预先定义计算图。
在chainer.functions类中给出了许多数值运算和激活函数。 标准神经网络的运算在Chainer类中是通过Link类实现的,比如线性全连接层和卷积层。Link可以看做是与其相应层的学习参数的一个函数(例如权重和偏差参数)。你也可以创建一个包含许多其他Link的Link。这样的一个link容器被命名为Chain。这允许Chainer可以将神经网络建模成一个包含多个link和多个chain的层次结构。Chainer还支持最新的优化方法、序列化方法以及使用CuPy的由CUDA驱动的更快速计算。
>>> import chainer.functions as F
>>> import chainer.links as L
>>> from chainer import Chain, optimizers, serializers, cuda
>>> import cupy as cp
二 chainer的设计
训练一个神经网络一般需要三个步骤:(1)基于神经网络的定义来构建计算图;(2)输入训练数据并计算损失函数;(3)使用优化器迭代更新参数直到收敛。
通常,深度学习框架在步骤2之前先要完成步骤1。 我们称这种方法是“先定义再运行”。

对于复杂神经网络,这种“先定义再运行”的方法简单直接,但并不是最佳的,因为计算图必须在训练前确定。 例如,在实现循环神经网络时,用户不得不利用特殊技巧(比如Theano中的scan()函数),这就会使代码变的难以调试和维护。
与之不同的是,Chainer使用一种“边运行边定义”的独特方法,它将第一步和第二步合并到一个步骤中去。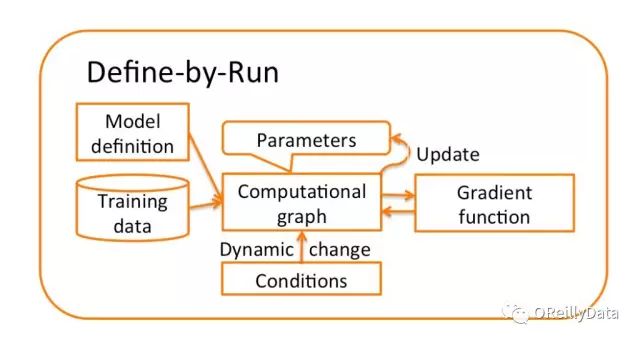
计算图不是在训练之前定义的,而是在训练过程中获得的。 因为正向计算直接对应于计算图并且也通过计算图进行反向传播,所以可以在每次迭代甚至对于每个样本的正向计算中对计算图做各种修改。
举一个简单的例子,让我们看看使用两层感知器进行MNIST数字分类会发生什么。

下面是Chainer中两层感知器的实现代码:
# 2-layer Multi-Layer Perceptron (MLP)
# 两层的多层感知器(MLP)
class MLP(Chain):
def __init__(self):
super(MLP, self).__init__()
l1=L.Linear(784, 100), # From 784-dimensional input to hidden unit with 100 nodes
# 从784维输入向量到100个节点的隐藏单元
l2=L.Linear(100, 10), # From hidden unit with 100 nodes to output unit with 10 nodes (10 classes)
# 从100个节点的隐藏单元到10个节点的输出单元(10个类)
# Forward computation
# 正向计算
def __call__(self, x):
h1 = F.tanh(self.l1(x)) # Forward from x to h1 through activation with tanh function
# 用tanh激活函数,从输入x正向算出h1
y = self.l2(h1) # Forward from h1to y
# 从h1正向计算出y
return y
在构造函数(__init__)中,我们分别定义了从输入单元到隐藏单元,和从隐藏单元到输出单元的两个线性变换。要注意的是,这时并没有定义这些变换之间的连接,这意味着计算图没有生成,更不用说固定它了。
跟“先定义后运行”方法不同的是,它们之间的连接关系会在后面的正向计算中通过定义层之间的激活函数(F.tanh)来定义。一旦对MNIST上的小批量训练数据集(784维)完成了正向计算,就可以通过从最终节点(损失函数的输出)回溯到输入来实时获得下面的计算图(注意这里使用SoftmaxCrossEntropy做为损失函数):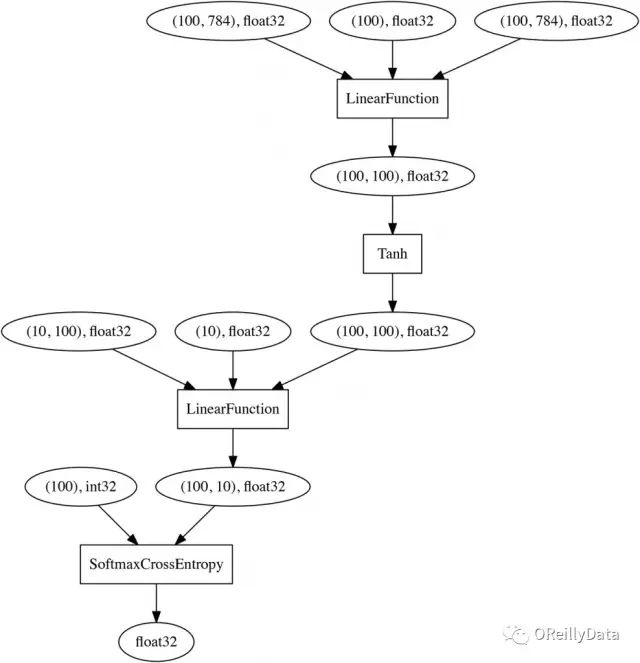 这里的关键点是神经网络是直接用Python来定义的而不是领域特定语言,因此用户可以在每次迭代(正向计算)中对神经网络进行更改。
这里的关键点是神经网络是直接用Python来定义的而不是领域特定语言,因此用户可以在每次迭代(正向计算)中对神经网络进行更改。
这种神经网络的命令性声明允许用户使用标准的Python语法进行网络分支计算,而不用研究任何领域特定语言(DSL)。这跟TensorFlow、 Theano使用的符号方法以及Caffe和CNTK依赖的文本DSL相比是一个优势。
此外,可以使用标准调试器和分析器来查找错误、重构代码以及调整超参数。 另一方面,尽管Torch和MXNet也允许用户使用神经网络的命令性建模,但是他们仍然使用“先定义后运行”的方法来构建计算图对象,因此调试时需要特别小心。
三 chainer安装
在Anaconda Prompt下运行下边的代码即可:
pip install chainer
参考:https://blog.csdn.net/zkh880loLh3h21AJTH/article/details/78100460
浅谈chainer框架的更多相关文章
- 手撸ORM浅谈ORM框架之基础篇
好奇害死猫 一直觉得ORM框架好用.功能强大集众多优点于一身,当然ORM并非完美无缺,任何事物优缺点并存!我曾一度认为以为使用了ORM框架根本不需要关注Sql语句如何执行的,更不用关心优化的问题!!! ...
- 手撸ORM浅谈ORM框架之Add篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- 手撸ORM浅谈ORM框架之Update篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- 手撸ORM浅谈ORM框架之Delete篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- 手撸ORM浅谈ORM框架之Query篇
快速传送 手撸ORM浅谈ORM框架之基础篇 手撸ORM浅谈ORM框架之Add篇 手撸ORM浅谈ORM框架之Update篇 手撸ORM浅谈ORM框架之Delete篇 手撸ORM浅谈ORM框架之Query ...
- 【SSH学习笔记】浅谈SSH框架
说在前面 本学期我们有一门课叫做Java EE,由陈老师所授,主要讲的就是Java EE 中的SSH框架. 由于陈老师授课风格以及自己的原因导致学了整整一学期不知道在讲什么,所以才有了自己重新学习总结 ...
- 浅谈angular框架
最近新接触了一个js框架angular,这个框架有着诸多特性,最为核心的是:MVVM.模块化.自动化双向数据绑定.语义化标签.依赖注入,以上这些全部都是属于angular特性,虽然说它的功能十分的强大 ...
- 浅谈可扩展性框架:MEF
之前在使用Prism框架时接触到了可扩展性框架MEF(Managed Extensibility Framework),体验到MEF带来的极大的便利性与可扩展性. 此篇将编写一个可组合的应用程序,帮助 ...
- 13.Object-C--浅谈Foundation框架常用的结构体
------- android培训.iOS培训.期待与您交流! ---------- 昨天学习了Foundation框架中常用的结构体,下面我简单的总结一下,如果错误麻烦请留言指正,谢谢! Found ...
随机推荐
- 洛谷【P1004】方格取数
浅谈\(DP\):https://www.cnblogs.com/AKMer/p/10437525.html 题目传送门:https://www.luogu.org/problemnew/show/P ...
- BZOJ1116:[POI2008]CLO
浅谈并查集:https://www.cnblogs.com/AKMer/p/10360090.html 题目传送门:https://lydsy.com/JudgeOnline/problem.php? ...
- facebook注册不了无法打开官网的解决办法
上周有一个朋友问到我一个问题,问怎么facebook注册不了,facebook官网也无法打开?这个问题不知道有没有人遇到过,以前这个问题也困扰了我挺长时间的,其实想想也挺简单的,由于facebook, ...
- hihoCoder#1062(最近公共祖先一)
时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Ho最近发现了一个神奇的网站!虽然还不够像58同城那样神奇,但这个网站仍然让小Ho乐在其中,但这是为什么呢? “为什么呢 ...
- POJ1020(小正方形铺大正方形)
Anniversary Cake Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 16579 Accepted: 5403 ...
- bytes,packet区别 字节数据包
“包”(Packet)是TCP/IP协议通信传输中的数据单位,一般也称“数据包”.字节(Byte): 字节是通过网络传输信息(或在硬盘或内存中存储信息)的单位. 字节是计算机信息技术用于计量存储容量和 ...
- myeclipse10启动service窗口报异常
1:找到与之对应的tomcat: 2:删掉“.metadata/.plugins/org.eclipse.core.runtime/.settings/ com.genuitec.eclipse.as ...
- 记录一次手机联系人整理(XML文件格式处理)
场景:1.IOS手机和Android手机联系人同步时有部分重复联系人. 2.很早以前的HTC手机导出的联系人中备注信息有大量乱码,且很多联系人生日被设置为1970-01-01,导致生日提醒软件产生骚扰 ...
- day17-jdbc 7.Statement介绍
SQL语句:DML.DQL.DCL.DDL.DML和DQL是用的最多的.DCL和DDL用的很少. 程序员一般是操作记录,创建一表很少. package cn.itcast.jdbc; import c ...
- iOS 判断设备是否越狱了
#import "PrisonBreakCheck.h" @implementation PrisonBreakCheck /** * 判断iPhone是否越狱了 */ +(BOO ...