【C++学习笔记】强大的算法——spfa
- spfa的定义
PFA算法的全称是:Shortest Path Faster Algorithm,用于求单源最短路,由西南交通大学段凡丁于1994年发表。当给定的图存在负边时,Dijkstra算法就无能为力了,然而bellman_ford算法的复杂度又太高。在这种情况下spfa算法就有了用武之地。
- spfa实现
为了简单起见,我们首先约定有向图G中不存在负权回路(如果有就不会存在最短路了),在执行spfa时如果一个节点入队次数超过 n 次(n为节点总数),那么图中就存在负环。我们用数组 dis[ ] 来储存最短路的当前最优值,用邻接表(推荐)或邻接矩阵来储存图。
- 首先设立一个先进先出的队列 q 来保存待优化的节点,再优化时依次取出队首的节点U,并利用节点U当前的最短路径最优值(dis[u] )对离开U所指向的节点V施行 松弛操作 。如果V的最短路径估计值有所调整(),且V不在当前的队列 q 中,那么就将 V 入队。不断重复上述操作直到队列为空。
- 关于松弛操作: 松弛操作的原理是定理: “三角形两边之和大于第三边” ,在信息学中我们叫它三角不等式。所谓对结点 i , j进行松弛,就是判定是否dis[ j ] > dis[ i ] + w[ i , j ],如果该式成立则将 dis[ j ] 减小到 dis[ i ] + w[ i , j ],否则不动。
利用下图来演示一下spfa算法的过程:
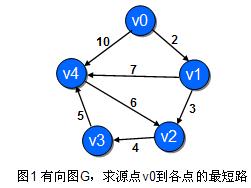
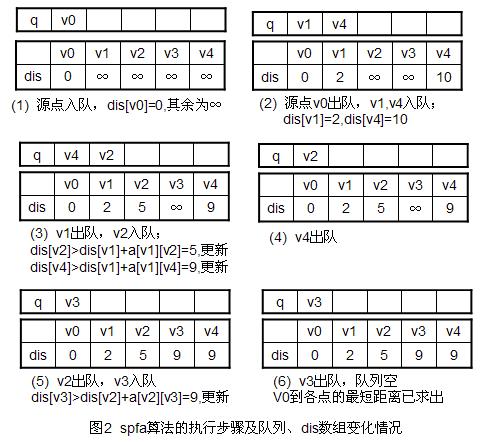
- spfa和bfs的区别:
SPFA 在形式上和广度(宽度)优先搜索非常类似,不同的是bfs中一个点出了队列就不可能重新进入队列,但是SPFA中一个点可能在出队列之后再次被放入队列,也就是一个点改进过其它的点之后,过了一段时间可能本身被改进(重新入队),于是再次用来改进其它的点,这样反复迭代下去。
- 具体代码实现
其中 vis[ i ] 判断点 i 是否已经入队,a[ i ][ n ] 表示从 i 到 n 的权值
void spfa ( int s ) { //求s到其它各点的最短路
for ( int i = ; i <= n; i ++ ) {
dis[i] = ; //初始化
}
dis[ s ] = ; vis[s] = ; q[ ] = s; //以 S 为起点
int i, v, head = , tail = ;
while ( head < tail ) { //判断队列非空
head ++;
v = q[ head ];
vis[ v ] = ; //释放队首元素,因为该节点可能下次用来松弛
for ( int i = ; i <= n; i ++ ) {
if ( a[ v ][ i ] > && dis[ i ] > dis[ v ] + a[ v ][ i ] ) {
dis[ i ] = dis[ v ] + a[ v ] [ i ]; //符合条件,修改最短路
if ( vis[ i ] == ) { //如果扩展节点不在队列中,入队!
tail ++;
q[ tail ] = i;
vis[ i ] = ;
}
}
}
}
}
- spfa的优化
- dfs
在以上的 spfa算法 中,当图中存在负环时,算法的复杂度将会退化成 O(m * n)。因此我们试着用 bfs 来改进一下。核心思路是 每当更新一个节点 u 时,从该节点开始递归进行下一次迭代。相比于原来的算法,使用 bfs 有一个天然的优势,在环上走了一圈后如果回到已经遍历过的节点,则说明图中存在负环(比原先的方法快了不止一点)。用二维数组 a[ ][ ] 和 v[ ][ ] 来存图,其中 a[ i ][ 0 ] 储存从节点 i 出发共有几条边, a[ i ][ n ] 储存从节点 i 出发的第 n 条边的终点,v[ n ][ m ] 储存边从 n 到 m 的权值。(由此可见好的数据结构可以为我们省下大量的时间)
void spfa_dfs ( int st ) { //寻找以 节点st 为原点的最短路
for ( int i = ; i <= b[st][]; i ++ ) { //遍历节点所连接的边
if ( dis[ a[st][i] ] > dis[st] + v[st][ a[st][i] ] ) {
dis[ a[st][i] ] = dis[s] + v[st][ a[st][i] ]; //标准的spfa
spfa ( b[st][i] ); //从入队的节点开始下一次迭代
}
}
} /* 用数组 dis[ ] 来储存结果*/
- 前向星优化
前向星型表示法(star)的思想和邻接表表示法的的思想有一定的相似之处,对于每个节点它也是记录从该节点出发的所有的边,但它没有采用单向链表而是用一个一维数组表示。也就是说,在该数组中首先存放从结点1出发的所有弧,然后接着存放从节点2出发的所有孤,依此类推,最后存放从结点n出发的所有孤。对每条弧,要依次存放其起点、终点、权的数值等有关信息。这实际上相当于对所有弧给出了一个顺序和编号,只是从同一结点出发的弧的顺序可以任意排列。此外,为了能够快速检索从每个节点出发的所有弧,我们一般还用一个数组记录每个结点出发的弧的起始地址(即弧的编号)。在这种表示法中,可以快速检索从每个结点出发的所有弧,这种星形表示法称为前向星形(forward star)表示法,也是一种常见的存图方法。
具体代码实现
int first[]; /* 关于 前向星 详见我的另一篇随笔 */
struct edge {
int point, next, len;
};
edge e[] void add(int i, int u, int v, int w){
e[i].point = v;
e[i].next = first[u];
e[i].len = w;
first[u] = i;
} int main(){
int n, m;
cin >> n >> m;
for ( int i = ; i <= m; i ++ ) {
int u, v, w;
cin >> u >> v >> w;
add ( i, u, v, w );
}
for ( int i = ; i <= n; i ++ ) {
cout << "from " << i << endl;
for ( int j = first[i]; j ; j = e[j].next ) //这就是遍历边了
cout << "to " << e[j].point << " length= " << e[j].len << endl;
}
}
贴个友链~ https://www.cnblogs.com/dreagonm/
【C++学习笔记】强大的算法——spfa的更多相关文章
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
- 【学习笔记】 Adaboost算法
前言 之前的学习中也有好几次尝试过学习该算法,但是都无功而返,不仅仅是因为该算法各大博主.大牛的描述都比较晦涩难懂,同时我自己学习过程中也心浮气躁,不能专心. 现如今决定一口气肝到底,这样我明天就可以 ...
- 挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html DBSCAN(Density-Based Spatial Clu ...
- 普通平衡树学习笔记之Splay算法
前言 今天不容易有一天的自由学习时间,当然要用来"学习".在此记录一下今天学到的最基础的平衡树. 定义 平衡树是二叉搜索树和堆合并构成的数据结构,它是一 棵空树或它的左右两个子树的 ...
- 【算法学习笔记】Meissel-Lehmer 算法 (亚线性时间找出素数个数)
「Meissel-Lehmer 算法」是一种能在亚线性时间复杂度内求出 \(1\sim n\) 内质数个数的一种算法. 在看素数相关论文时发现了这个算法,论文链接:Here. 算法的细节来自 OI w ...
- python学习笔记(MD5算法)
博主最近进度停滞了 对web开发理解欠缺好多内容 今天整理下MD5算法,这个涉及到mysql数据库存储用户表密码字段的时候 一般是带有加密的 # -*- coding: utf-8 -*- impor ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- Web安全学习笔记之DES算法实例详解
转自http://www.hankcs.com/security/des-algorithm-illustrated.html 译自J. Orlin Grabbe的名作<DES Algorith ...
随机推荐
- 牛客假日团队赛1 I.接机
链接: https://ac.nowcoder.com/acm/contest/918/I 题意: 一场别开生面的牛吃草大会就要在Farmer John的农场举办了! 世界各地的奶牛将会到达当地的机场 ...
- Hadoop TaskScheduler源码分析
TaskScheduler是MapReduce中的任务调度器.在MapReduce中,JobTracker接收JobClient提交的Job,将它们按InputFormat的划分以及其他相关配置,生成 ...
- MapReduce的输入格式
1. InputFormat接口 InputFormat接口包含了两个抽象方法:getSplits()和creatRecordReader().InputFormat决定了Hadoop如何对文件进行分 ...
- java Smaphore 控制并发线程数
概念: Semaphore(信号量)是用来控制同事访问特定资源的线程数量,它通过协调各个线程,已保证合理的使用公共资源. 应用场景: Semaphore 可以用于做流量控制,特别是共用资源有限的应用场 ...
- 19.CentOS7下PostgreSQL安装过程
CentOS7下PostgreSQL安装过程 装包 sudo yum install postgresql-server postgresql-contrib 说明: 这种方式直接明了,其他方法也可以 ...
- mui的ajax例子3
mui.get() 前端页面: <!DOCTYPE html><html><head> <meta charset="utf-8"> ...
- 零基础逆向工程27_Win32_01_宽字符_MessageBox_win32调试输出
1 多字节字符 ASCII码表:0 ~ 2^7-1 扩展ASCII码表:2^7 ~ 2^8-1 什么是GB2312:1980年,两个字节存储一个汉字:不通用,别国会有乱码. UCICODE:只有一个字 ...
- RING3到RING0
当我在说跳转时,说的什么? CPU有很多指令,不是所有的指令都能够随时用,比如 ltr指令就不是随便什么时候能用,在保护模式下,如果你不安规则来执行指令,CPU就会抛出异常,比如你在INTEL手册上就 ...
- leetcode 355 Design Twitte
题目连接 https://leetcode.com/problems/design-twitter Design Twitte Description Design a simplified vers ...
- maven+jenkins发布环境
安装java省略,下面是环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_65/ export PATH=$JAVA_HOME/bin:$PATH export CLA ...