Storm概念学习系列之storm核心组件
不多说,直接上干货!
Storm核心组件
了解 Storm 的核心组件对于理解 Storm 原理非常重要,下面介绍 Storm 的整体,然后介绍 Storm 的核心。 Storm 集群由一个主节点和多个工作节点组成。主节点运行一个名为“Nimbus”的守护进程,工作节点都运行一个名为“Supervisor”的守护进程,两者的协调工作由 ZooKeeper 来完成, ZooKeeper 用于管理集群中的不同组件。
每一个工作节点上运行的 Supervisor 监听分配给它那台机器的工作,根据需要启动 / 关闭工作进程,每一个工作进程执行一个 Topology 的一个子集;一个运行的 Topology 由运行在很多机器上的很多工作进程 Worker 组成。那么 Storm 的核心就是主节点(Nimbus)、工作节点(Supervisor)、协调器(ZooKeeper)、工作进程( Worker)、任务线程(Task)。
1、主节点 Nimbus
主节点通常运行一个后台程序——Nimbus,用于响应分布在集群中的节点,分配任务和监测故障,这类似于 Hadoop 中的 JobTracker。
Nimbus 进程是快速失败( fail-fast)和无状态的,所有的状态要么在 ZooKeeper 中,要么在本地磁盘上。可以使用 kill -9 来杀死 Nimbus 进程,然后重启即可继续工作。
2、工作节点 Supervisor
工作节点同样会运行一个后台程序——Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是Topology中一个子集的实现。而Nimbus 和 Supervisor 之间的协调则通过 ZooKeeper 系统。
同 样,Supervisor进程也是快速失败(fail-fast)和无状态的, 所有的状态要么在ZooKeeper中,要么在本地磁盘上,用kill -9来杀死Supervisor进程,然后重启就可以继续工作。
3、协调服务组件 ZooKeeper
ZooKeeper 是完成 Nimbus 和 Supervisor 之间协调的服务。 Storm使用ZooKeeper 协调集群,由于ZooKeeper 并不用于消息传递,所以Storm给ZooKeeper 带来的压力相当低。在大多数情况下,单个节点的 ZooKeeper 集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模的 ZooKeeper 集群。 Nimbus、 Supervisor 与 ZooKeeper 的关系如图 1 所示。
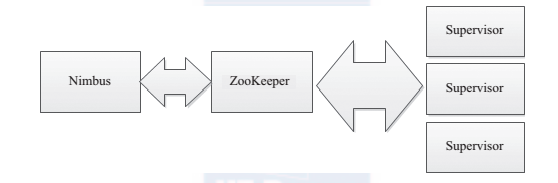
图 1 Nimbus、 Supervisor 与 ZooKeeper 关系图
4、其他核心组件
Storm 的组件不止上面的,还有一些组件也是 Storm 的核心,缺一不可。下面简单介绍Worker 和 Task。
1)具体处理事务进程 Worker:运行具体处理组件逻辑的进程。
2)具体处理线程 Task : Worker 中的每一个 Spout/Bolt 线程称为一个 Task。在 Storm 0.8之后, Task 不再与物理线程对应,同一个 Spout/Bolt 的 Task 可能会共享一个物理线程,该线程称为 Executor。
Storm概念学习系列之storm核心组件的更多相关文章
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之storm的定时任务
不多说,直接上干货! 至于为什么,有storm的定时任务.这个很简单.但是,这个在工作中非常重要! 假设有如下的业务场景 这个spoult源源不断地发送数据,boilt呢会进行处理.然后呢,处理后的结 ...
- Storm概念学习系列之storm的可靠性
这个概念,对于理解storm很有必要. 1.worker进程死掉 worker是真实存在的.可以jps查看. 正是因为有了storm的可靠性,所以storm会重新启动一个新的worker进程. 2.s ...
- Storm概念学习系列之storm简介
不多说,直接上干货! storm简介 Storm 是 Twitter 开源的.分布式的.容错的实时计算系统,遵循 Eclipse Public License1.0. Storm 通过简单的 API ...
- Storm概念学习系列之storm的功能和三大应用
不多说,直接上干货! storm的功能 Storm 有许多应用领域:实时分析.在线机器学习.持续计算.分布式 RPC(远过程调用协议,一种通过网络从远程计算机程序上请求服务). ETL(Extract ...
- Storm概念学习系列之storm的特性
不多说,直接上干货! storm的特性 Storm 是一个开源的分布式实时计算系统,可以简单.可靠地处理大量的数据流. Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快 ...
- Storm概念学习系列之Storm与Hadoop的角色和组件比较
不多说,直接上干货! Storm与Hadoop的角色和组件比较 Storm 集群和 Hadoop 集群表面上看很类似.但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行 ...
- Storm概念学习系列之storm的设计思想
不多说,直接上干货! storm的设计思想 在 Storm 中也有对流(Stream)的抽象,流是一个不间断的.无界的连续 Tuple(Storm在建模事件流时,把流中的事件抽象为 Tuple 即元组 ...
随机推荐
- art-template-loader:template
ylbtech-art-template-loader: 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 6.返回顶部 作者:ylbtech出处:ht ...
- Velocity的layout功能
一.从VelocityViewServlet到VelocityLayoutServlet 使用Velocity开发web应用时,需要在web.xml中配置一个Velocity提供的VelocityVi ...
- JS取得绝对路径
在项目中,我们经常要得到项目的绝对路径,方便我们上传下载文件,JS为我们提供了方法,虽说要迂回一下.代码如下: function getRealPath(){ //获取当前网址,如: h ...
- SQL 时间及字符串操作
都是一些很基础很常用的,在这里记录一下 获取年月日: year(时间) ---获取年,2014 month(时间) ----获取月,5 day(时间) -----获取天,6 如果月份或日期不足两位数, ...
- jquery.html5uploader.js 上传控件
插件地址:http://blog.csdn.net/never_say_goodbye/article/details/8598521 先上个效果图: 相比来说,效果还是很不错的 使用MVC3做服务器 ...
- RStudio 断点调试 进入for循环语句调试
参考: http://www.rstudio.com/ide/docs/debugging/overview 1.进入调试模式 全选代码,点击source即可进入调试模式. 2.进入for 调试 在F ...
- 修改TABLE中的Column的属性
删除主键名 这个主键名并不是列名,而是主键约束的名字,如果当时设置主键约束时没有制定约束的名字 设置主键的语句:ALTER TABLE P add constraint pk PRIMARY KEY ...
- Spring深入学习
涨知识系列 Environment environment = context.getEnvironment(); 在Spring中所有被加载到spring中的配置文件都会出现在这个环境变量中, 其中 ...
- 图像标注工具labelImg使用方法
最近在做打标签的工作,为了与大家参考学习,总结了在windows的环境下,基于anaconda的图像标注工具labellmg的一种使用方法! 1 搭建anaconda 以前写过怎么搭建anaconda ...
- SAS笔记(5) FLAG和计数器
考虑这样一种场景:我们有一份患者入院检查的数据,我们知道一个患者有可能会多次去医院做检查,每次检查的结果可能为阳性,也可能为阴性.我们现在关注的是某一个患者在若干次检查中是否出现了阳性结果,在R中我们 ...