机器学习Hands On Lab
fetch_data
fetch_mldata默认路径是在scikit_learn_data路径下,mnist的mat文件其实直接放置到scikit_lean/mldata下面即可通过fetch_mldata中获取;当然路径信息其实是fetch_home函数中定义的;
洗牌训练数据
为了避免数据的有序对于训练的影响,有的时候需要对于数据进行随机排列;比如对于7万个手写数字的样本,前60000个做训练集,这6万个需要通过np.random.permutation(60000)来进行随机重排,也成为洗牌(shuffle)。但是这种洗牌主要用于样本本身不具备顺序性;但是对于一些样本之间具有关联系,比如具有时间排序联系(股票,天气)则尽量避免洗牌操作,因为训练的本身就是具有训练时序性。
唉,在做手写体测试的时候,每次执行从洗牌到训练到验证(sdg_clf.predict([some_digit]))的时候发现经常执行结果不一样,有的时候能够识别some_digit为5,有的则识别不出来。
scores和predict的差别
注意模型的scores和predict的差别,前者其实是对于样本可能是某个值的一种可能值;后者则是直接根据X预测y,在分类算法里面,predict返回的就是分类类别,里面本质上是计算某个用例在各个分类中的概率,选择概率最大的那个;
用decision_function来代替predict,前者返回的内容scores;scores现在我的理解是对于二元/多元计分,通常是根据分值最大的那个分类作为predict的返回值(所以predict在内部实现是是先调用decision_function,然后再自行判断类别),所谓分值的阈值也是判断是否的分割线;那么对于多分类的处理是怎样的呢?
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
其中分值(scoring)的种类如下表所示:
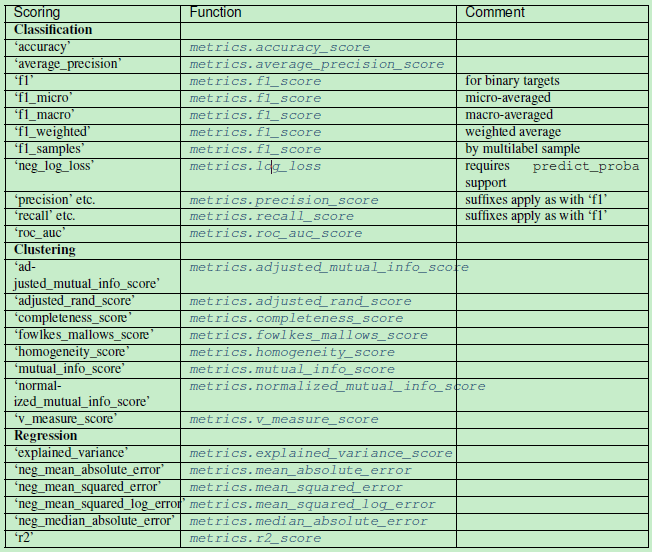
参考:
http://scikit-learn.org/stable/modules/model_evaluation.html
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
这个random_state是做什么的?一个算法只要指定了random_state,就可以保证每次产生的随机数都是一致的,可以保证多次运行产生的模型一致;很多时候是测试阶段为了获取稳定测试效果会如此处理;在生产环境很多场景是需要随记的;主要还是看应用场景,是否需要random_state。
机器学习Hands On Lab的更多相关文章
- 机器学习中jupyter lab的安装方法以及使用的命令
安装JupyterLab使用pip安装: pip install jupyterlab# 必须将用户级目录添加 到环境变量才能启动pip install --userbinPATHjupyter la ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- paper 118:计算机视觉、模式识别、机器学习常用牛人主页链接
牛人主页(主页有很多论文代码) Serge Belongie at UC San Diego Antonio Torralba at MIT Alexei Ffros at CMU Ce Liu at ...
- 机器学习&数据挖掘笔记_13(用htk完成简单的孤立词识别)
最近在看图模型中著名的HMM算法,对应的一些理论公式也能看懂个大概,就是不太明白怎样在一个具体的机器学习问题(比如分类,回归)中使用HMM,特别是一些有关状态变量.观察变量和实际问题中变量的对应关系, ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- OAF 供应商门户添加功能标签后获取当前供应商VendorId的方法
一种是参考管理页面 /oracle/apps/pos/supplier/webui/SuppDtPG 在目标页面的AM中添加VO实例,oracle.apps.pos.supplier.server.S ...
- Linux文件与目录管理(一)
一.Linux文件与目录管理 1.Linux的目录结构是树状结构,最顶级的目录是根目录/(用"/"表示) 2.Linux目录结构图: /bin:bin是Binary的缩写,这个目录 ...
- spring-mvc---Controller参数绑定的类型
Controller参数绑定的类型 Controller的绑定参数类型6种.没有参数(系统默认类型):简单类型(Intager,Double)等:pojo类(对象):数组:集合:HashMap等. 我 ...
- qt +ChartDirector 绘制图表
自从开发由c#转入Qt后一直寻找一款Qt下的图形控件库,最后ChartDirector控件映入眼球.ChartDirector控件使用方便,快捷,灵活,功能强大,交互性强.在web服务器以及嵌入式应用 ...
- Winform中用comboBox来选择显示Dataset中表格数据
这是一次偷懒的尝试,因为每次都必须打开代码,调试才能看见数据,发现问题.也是借鉴了调试中查看dataset数据的模式,查看不同表格.经历一番研究,总算实现了想要的效果了,故作此一笔记.与人共享. 界面 ...
- scrapy-redis介绍(一)
scrapy是python里面一个非常完善的爬虫框架,实现了非常多的功能,比如内存检测,对象引用查看,命令行,shell终端,还有各种中间件和扩展等,相信开发过scrapy的朋友都会觉得这个框架非常的 ...
- Spring Data JPA 复杂/多条件组合分页查询
推荐视频: http://www.icoolxue.com/album/show/358 public Map<String, Object> getWeeklyBySearch(fina ...
- vue和微信小程序的区别、比较
链接:https://segmentfault.com/a/1190000015684864 一.生命周期 先贴两张图: vue生命周期 小程序生命周期 相比之下,小程序的钩子函数要简单得多. vue ...
- java poi 写入大量数据到excel中
最近在利用poi往excel中写入大量数据时,发现excel2003最多只支持65535条,大量数据时容易造成oom,上网查了一下api,发现目前对于2003,每个sheet最多支持65535条,若数 ...
- android编译环境安装
Android 编译环境安装 安装 Java 6 安装 Java 6 安装依赖包 (Ubuntu 12.04) $ sudo apt-get install git gnupg flex bison ...