HBase统计表行数(RowCount)的四种方法
背景:
对于其他数据存储系统来说,统计表的行数是再基本不过的操作了,一般实现都非常简单;但对于HBase这种key-value存储结构的列式数据库,统计 RowCount 的方法却有好几种不同的花样,并且执行效率差别巨大!下面来研究下吧~
测试集群:HBase1.2.0 - CDH5.13.0 四台服务器
注:以下4种方法效率依次提高
一、hbase-shell的count命令
这是最简单直接的操作,但是执行效率非常低,适用于百万级以下的小表RowCount统计!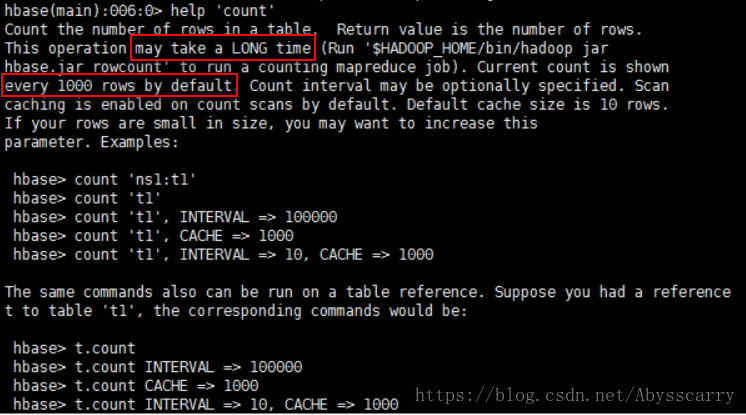
hbase> count 'ns1:t1'
hbase> count 't1'
hbase> count 't1', INTERVAL => 100000
hbase> count 't1', CACHE => 1000
hbase> count 't1', INTERVAL => 10, CACHE => 1000
此操作可能需要很长时间,来运行计数MapReduce作业。默认情况下每1000行显示当前计数,计数间隔可自行指定。
默认情况下在计数扫描上启用缓存,默认缓存大小为10行。
行数为 3000W 的表测试结果:
hbase(main):001:0> count 'sda_crm_calls20180102'
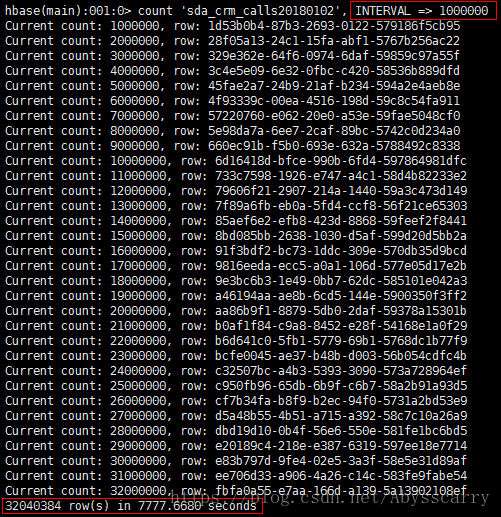
INTERVAL为1000000行时花了130分钟。
二、scan方式设置过滤器循环计数(JAVA实现)
这种方式是通过添加 FirstKeyOnlyFilter 过滤器的scan进行全表扫描,循环计数RowCount,速度较慢! 但快于第一种count方式!
基本代码如下:
public void rowCountByScanFilter(String tablename){
long rowCount = 0;
try {
//计时
StopWatch stopWatch = new StopWatch();
stopWatch.start();
TableName name=TableName.valueOf(tablename);
//connection为类静态变量
Table table = connection.getTable(name);
Scan scan = new Scan();
//FirstKeyOnlyFilter只会取得每行数据的第一个kv,提高count速度
scan.setFilter(new FirstKeyOnlyFilter());
ResultScanner rs = table.getScanner(scan);
for (Result result : rs) {
rowCount += result.size();
}
stopWatch.stop();
System.out.println("RowCount: " + rowCount);
System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());
} catch (Throwable e) {
e.printStackTrace();
}
}
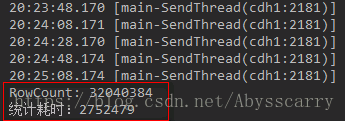
耗时45分钟!
三、利用hbase.RowCounter包执行MR任务
这种方式效率非常高!利用了hbase jar中自带的统计行数的工具类!
通过 $HBASE_HOME/bin/hbase 命令执行:
[root@cdh1 ~]# hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'sda_crm_calls20180102'

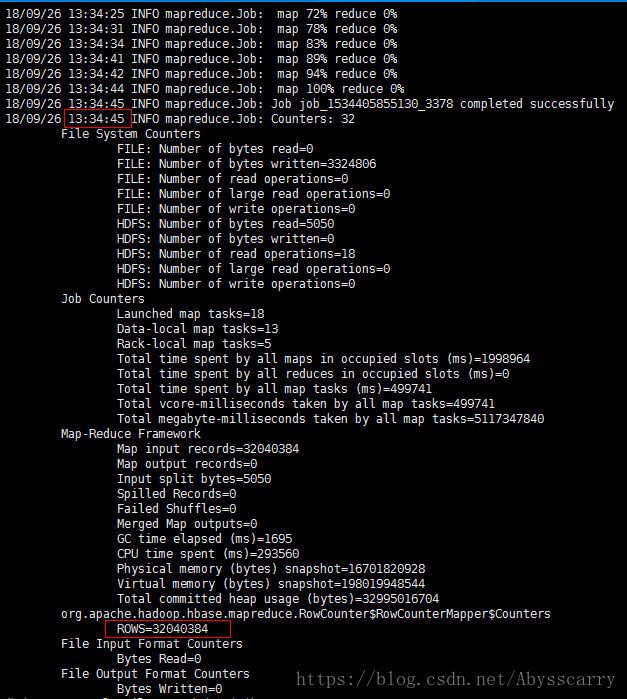
耗时1m40s,速度较上面两种有了质的飞跃!
四、利用HBase协处理器Coprocessor(JAVA实现)
这是我目前发现效率最高的RowCount统计方式,利用了HBase高级特性:协处理器!
我们往往使用过滤器来减少服务器端通过网络返回到客户端的数据量。但HBase中还有一些特性让用户甚至可以把一部分计算也移动到数据的存放端,那就是协处理器 (coprocessor)。
协处理器简介:
(节选自《HBase权威指南》)
使用客户端API,配合筛选机制,例如,使用过滤器或限制列族的范围,都可以控制被返回到客户端的数据量。如果可以更进一步优化会更好,例如,数据的处理流程直接放到服务器端执行,然后仅返回一个小的处理结果集。这类似于一个小型的MapReduce框架,该框架将工作分发到整个集群。
协处理器 允许用户在region服务器上运行自己的代码,更准确地说是允许用户执行region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不用关心操作具体在哪里执行,HBase的分布式框架会帮助用户把这些工作变得透明。
实现代码:
public void rowCountByCoprocessor(String tablename){
try {
//提前创建connection和conf
Admin admin = connection.getAdmin();
TableName name=TableName.valueOf(tablename);
//先disable表,添加协处理器后再enable表
admin.disableTable(name);
HTableDescriptor descriptor = admin.getTableDescriptor(name);
String coprocessorClass = "org.apache.hadoop.hbase.coprocessor.AggregateImplementation";
if (! descriptor.hasCoprocessor(coprocessorClass)) {
descriptor.addCoprocessor(coprocessorClass);
}
admin.modifyTable(name, descriptor);
admin.enableTable(name);
//计时
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Scan scan = new Scan();
AggregationClient aggregationClient = new AggregationClient(conf);
System.out.println("RowCount: " + aggregationClient.rowCount(name, new LongColumnInterpreter(), scan));
stopWatch.stop();
System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());
} catch (Throwable e) {
e.printStackTrace();
}
}
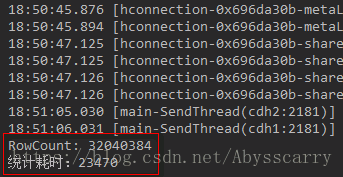
发现只花了 23秒 就统计完成!
为什么利用协处理器后速度会如此之快?
Table注册了Coprocessor之后,在执行AggregationClient的时候,会将RowCount分散到Table的每一个Region上,Region内RowCount的计算,是通过RPC执行调用接口,由Region对应的RegionServer执行InternalScanner进行的。
因此,性能的提升有两点原因:
1.分布式统计。将原来客户端按照Rowkey的范围单点进行扫描,然后统计的方式,换成了由所有Region所在RegionServer同时计算的过程。
2.使用了在RegionServer内部执行使用了InternalScanner。这是距离实际存储最近的Scanner接口,存取更加快捷。
HBase统计表行数(RowCount)的四种方法的更多相关文章
- Hbase 统计表行数的3种方式总结
有些时候需要我们去统计某一个Hbase表的行数,由于hbase本身不支持SQL语言,只能通过其他方式实现.可以通过一下几种方式实现hbase表的行数统计工作: 1.count命令 最直接的方式是在hb ...
- jmeter--参数化的四种方法
本文转自:http://www.cnblogs.com/imyalost/p/6229355.html 参数化是自动化测试脚本的一种常用技巧.简单来说,参数化的一般用法就是将脚本中的某些输入使用参数来 ...
- Python 文件行数读取的三种方法
Python三种文件行数读取的方法: #文件比较小 count = len(open(r"d:\lines_test.txt",'rU').readlines()) print c ...
- SQL server分页的四种方法
SQL server分页的四种方法 1.三重循环: 2.利用max(主键); 3.利用row_number关键字: 4.offset/fetch next关键字 方法一:三重循环思路 先取前20页, ...
- SQL server分页的四种方法(算很全面了)
这篇博客讲的是SQL server的分页方法,用的SQL server 2012版本.下面都用pageIndex表示页数,pageSize表示一页包含的记录.并且下面涉及到具体例子的,设定查询第2 ...
- 运行jar应用程序引用其他jar包的四种方法
转载地址:http://www.iteye.com/topic/332580 大家都知道一个java应用项目可以打包成一个jar,当然你必须指定一个拥有main函数的main class作为你这个ja ...
- C#播放声音的四种方法 +AxWindowsMediaPlayer的详细用法
C#播放声音的四种方法 第一种是利用DirectX 1.安装了DirectX SDK(有9个DLL文件).这里我们只用到MicroSoft.DirectX.dll和 Microsoft.Directx ...
- 【AS3】Flash与后台数据交换四种方法整理
随着Flash Player 9的普及,AS3编程也越来越多了,所以这次重新整理AS3下几种与后台数据交换方法.1.URLLoader(URLStream)2.FlashRemoting3.XMLSo ...
- (转载)eclipse插件安装的四种方法
eclipse插件安装的四种方法 Eclipse插件的安装方法 1.在eclipse的主目录(ECLIPSE_HOME, 比如在我的机器上安装的目录是:D:\eclipse)有一个plugins的目录 ...
随机推荐
- TP5 Request 请求对象【转】
app\index\controller\Index.php <?php namespace app\index\controller; use think\Request; class Ind ...
- mybatis中的分页插件
1.Mybatis的分页plugin实现原理 2.具体步骤 第一步.导入到pom.xml文件中依赖包 第二步.配置插件(必需) 在mybatisConfig.xml文件中配置以下代码 代码位置:在en ...
- 09-webpack--配置less
<!-- cnpm i less-loader less -D 要下载两个 在入口文件main.js文件中引入 import './css/index.less' webpack.config. ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- LeetCode 112. Path Sum路径总和 (C++)
题目: Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up ...
- JAVA基础概念(一)
一.JAVA标识符 标识符就是用于给 Java 程序中变量.类.方法等命名的符号.如图标黄部分: 使用标识符时,需要遵守几条规则: 1. 标识符可以由字母.数字.下划线(_).美元符($)组成,但不 ...
- Linux性能优化实战学习笔记:第三十五讲
一.上节回顾 前面内容,我们学习了 Linux 网络的基础原理以及性能观测方法.简单回顾一下,Linux网络基于 TCP/IP 模型,构建了其网络协议栈,把繁杂的网络功能划分为应用层.传输层.网络层. ...
- bower安装教程
进入node.js官网下载相应操作系统的安装文件http://www.nodejs.org/download/ ,windows环境下载msi文件即可 打开下载的文件,一直点击下一步,完成安装 安装完 ...
- BS项目启动任意EXE文件或者CS项目
1. 基于注册表启动exe程序 1. 桌面新建注册表执行文件:protocal.reg 2. 任意文本编辑器打开该文件 Windows Registry Editor Version 5.00 [HK ...
- Loj #2570. 「ZJOI2017」线段树
Loj #2570. 「ZJOI2017」线段树 题目描述 线段树是九条可怜很喜欢的一个数据结构,它拥有着简单的结构.优秀的复杂度与强大的功能,因此可怜曾经花了很长时间研究线段树的一些性质. 最近可怜 ...