Hadoop2.x 集群搭建
Hadoop2.x 集群搭建
一些重复的细节参考Hadoop1.X集群完全分布式模式环境部署
1 HADOOP 集群搭建
1.1 集群简介
HADOOP 集群具体来说包含两个集群:HDFS 集群和YARN集群,两者逻辑上分离,但物理上常在一起.
HDFS集群:负责海量数据的存储,集群中的角色主要有NameNode/DataNodeYARN集群:负责海量数据运算时的资源调度,集群中的角色主要有ResourceManager/NodeManager
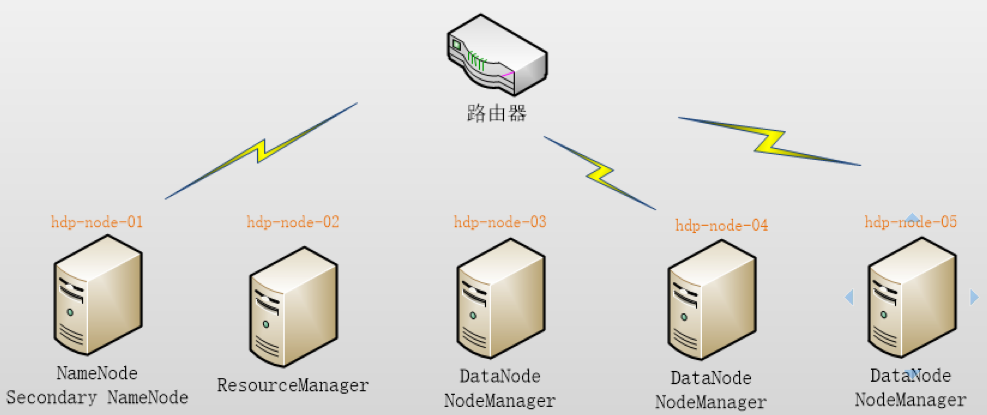
本集群搭建案例,以 5 节点为例进行搭建,角色分配如下:
| 结点 | 角色 | IP |
|---|---|---|
| node1 | NameNode SecondaryNameNode | 192.168.33.200 |
| node2 | ResourceManager | 192.168.33.201 |
| node3 | DataNode NodeManager | 192.168.33.202 |
| node4 | DataNode NodeManager | 192.168.33.203 |
| node5 | DataNode NodeManager | 192.168.33.204 |
部署图如下:
1.2 服务器准备
本案例使用虚拟机服务器来搭建 HADOOP 集群,所用软件及版本:
★ paraller Desktop 12
★ Centos 6.5 64bit
1.3 网络环境准备
- 采用 NAT 方式联网
- 网关地址:192.168.33.1
- 5个服务器节点 IP 地址:
- 192.168.33.200,
- 192.168.33.201,
- 192.168.33.202,
- 192.168.33.203,
- 192.168.33.204
- 子网掩码:255.255.255.0
1.4 服务器系统设置
- 添加 HADOOP 用户
- 为 HADOOP 用户分配 sudoer 权限
- 设置主机名
- node1
- node2
- node3
- node4
- node5
- 配置内网域名映射:
- 192.168.33.200--------node1
- 192.168.33.201--------node2
- 192.168.33.202--------node3
- 192.168.33.203--------node4
- 192.168.33.204--------node5
- 配置 ssh 免密登陆
- 配置防火墙
1.5 环境安装
- 上传 jdk 安装包
- 规划安装目录 /home/hadoop/apps/jdk_1.7.65
- 解压安装包
- 配置环境变量 /etc/profile
1.6 HADOOP 安装部署
- 上传 HADOOP 安装包
- 规划安装目录 /home/hadoop/apps/hadoop-2.6.1
- 解压安装包
- 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
/home/hd2/tmp目录要先建好
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.7.0_65
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hd2/tmp</value>
</property>
<property>
<name>hadoop.logfile.size</name>
<value>10000000</value>
<description>The max size of each log file</description>
</property>
<property>
<name>hadoop.logfile.count</name>
<value>10</value>
<description>The max number of log files</description>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hd2/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hd2/data/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>node1:50090</value>
</property>
ca
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi salves
node1
node2
node3
node4
node5
1.7 启动集群
初始化 HDFS
bin/hadoop namenode -format
启动 HDFS
sbin/start-dfs.sh
启动 YARN
sbin/start-yarn.sh
1.8 验证集群
浏览器访问http://192.168.33.200:50070


1.9 用worldcount程序测试集群
1.建立一个测试的目录
[hd2@node1 hadoop-2.4.1]$ hadoop fs -mkdir input
2.检验input文件夹是否创建成功
[hd2@node1 hadoop-2.4.1]$ hadoop fs -ls
Found 1 items
drwxr-xr-x - root supergroup 0 2014-08-18 09:02 input
3.建立测试文件
[hd2@node1 hadoop-2.4.1]$ vi test.txt
hello hadoop
hello World
Hello Java
Hey man
i am a programmer
4.将测试文件放到测试目录中
[hd2@node1 hadoop-2.4.1]$ hadoop fs -put test.txt input/
5.检验test.txt文件是否已经导入
[hd2@node1 hadoop-2.4.1]$ hadoop fs -ls input/
Found 1 items
-rw-r--r-- 1 root supergroup 62 2014-08-18 09:03 input/test.txt
6.执行wordcount程序
[hd2@node1 hadoop-2.4.1]$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount input/ output/
执行过程
17/04/19 21:07:19 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.33.200:8032
17/04/19 21:07:19 INFO input.FileInputFormat: Total input paths to process : 2
17/04/19 21:07:20 INFO mapreduce.JobSubmitter: number of splits:2
17/04/19 21:07:20 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1492605823444_0003
17/04/19 21:07:20 INFO impl.YarnClientImpl: Submitted application application_1492605823444_0003
17/04/19 21:07:20 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1492605823444_0003/
17/04/19 21:07:20 INFO mapreduce.Job: Running job: job_1492605823444_0003
17/04/19 21:07:26 INFO mapreduce.Job: Job job_1492605823444_0003 running in uber mode : false
17/04/19 21:07:26 INFO mapreduce.Job: map 0% reduce 0%
17/04/19 21:07:33 INFO mapreduce.Job: map 100% reduce 0%
17/04/19 21:07:40 INFO mapreduce.Job: map 100% reduce 100%
17/04/19 21:07:42 INFO mapreduce.Job: Job job_1492605823444_0003 completed successfully
17/04/19 21:07:42 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=68
FILE: Number of bytes written=279333
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=246
HDFS: Number of bytes written=25
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=1
Rack-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8579
Total time spent by all reduces in occupied slots (ms)=5101
Total time spent by all map tasks (ms)=8579
Total time spent by all reduce tasks (ms)=5101
Total vcore-seconds taken by all map tasks=8579
Total vcore-seconds taken by all reduce tasks=5101
Total megabyte-seconds taken by all map tasks=8784896
Total megabyte-seconds taken by all reduce tasks=5223424
Map-Reduce Framework
Map input records=2
Map output records=6
Map output bytes=62
Map output materialized bytes=74
Input split bytes=208
Combine input records=6
Combine output records=5
Reduce input groups=3
Reduce shuffle bytes=74
Reduce input records=5
Reduce output records=3
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=430
CPU time spent (ms)=1550
Physical memory (bytes) snapshot=339206144
Virtual memory (bytes) snapshot=1087791104
Total committed heap usage (bytes)=242552832
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=38
File Output Format Counters
Bytes Written=25
执行结果
[hd2@node1 hadoop-2.4.1]$ hadoop fs -ls /user/hd2/out/
Found 2 items
-rw-r--r-- 3 hd2 supergroup 0 2017-04-19 21:07 /user/hd2/out/_SUCCESS
-rw-r--r-- 3 hd2 supergroup 25 2017-04-19 21:07 /user/hd2/out/part-r-00000
[hd2@node1 hadoop-2.4.1]$ hadoop fs -cat /user/hd2/out/part-r-00000
hadoop 2
hello 3
world 1
Hadoop2.x 集群搭建的更多相关文章
- Hadoop2.20集群搭建
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等. 注意:apache提供的hadoop-2.2.0的安装包是在32位操作系统编译的,因为hadoop依赖一些C+ ...
- hadoop2.2集群搭建问题只能启动一个datanode问题
按照教程http://cn.soulmachine.me/blog/20140205/搭建总是出现如下问题: 2014-04-13 23:53:45,450 INFO org.apache.hadoo ...
- 大数据学习——hadoop2.x集群搭建
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- Hadoop2学习记录(1) |HA完全分布式集群搭建
准备 系统:CentOS 6或者RedHat 6(这里用的是64位操作) 软件:JDK 1.7.hadoop-2.3.0.native64位包(可以再csdn上下载,这里不提供了) 部署规划 192. ...
- centos下hadoop2.6.0集群搭建详细过程
一 .centos集群环境配置 1.创建一个namenode节点,5个datanode节点 主机名 IP namenodezsw 192.168.129.158 datanode1zsw 192.16 ...
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- hadoop2.2.0的ha分布式集群搭建
hadoop2.2.0 ha集群搭建 使用的文件如下: jdk-6u45-linux-x64.bin hadoop-2.2.0.x86_64.tar zookeeper-3.4.5. ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- hadoop2.6.0集群搭建
p.MsoNormal { margin: 0pt; margin-bottom: .0001pt; text-align: justify; font-family: Calibri; font-s ...
随机推荐
- [Beta阶段]第十一次Scrum Meeting
Scrum Meeting博客目录 [Beta阶段]第十一次Scrum Meeting 基本信息 名称 时间 地点 时长 第十一次Scrum Meeting 19/05/20 大运村寝室6楼 15mi ...
- nodejs异常处理过程/获取nodejs异常类型/写一个eggjs异常处理中间件
前言 今天想写一下eggjs的自定义异常处理中间件,在写的时候遇到了问题,这个错误我捕获不到类型?? 处理过程,不喜欢看过程的朋友请直接看解决方法和总结 看一下是什么: 抛出的异常是检验失败异常Val ...
- C# Microsoft.Office.Interop.Owc11 导出excel文件
C# Microsoft.Office.Interop.Owc11 导出excel文件 1.新建项SupremeWindowsForms窗体应用项目(项目平台设置称X86) 注意:因为大多数第三方写的 ...
- Cross-channel Communication Networks
Cross-channel Communication Networks 2019-12-13 14:17:18 Paper: https://papers.nips.cc/paper/8411-cr ...
- clickhouse 19.14.m.n简单测试
ClickHouse is a column-oriented database management system (DBMS) for online analytical processing o ...
- HTML5中的Web Worker技术
为了让后台程序更好的执行,在HTML5中设计了Web Worker技术.Web Worker的产生主要是考虑到在HTML4中JavaScript Web程序都是以单线程的方式执行的,一旦前面的脚本花费 ...
- UICachedDeviceRGBColor CGImage]: unrecognized selector sent to instance 0xxxxxxxxxxx'
UICachedDeviceRGBColor CGImage]: unrecognized selector sent to instance 0xxxxxxxxxxx' 报错原因是 本来应该写空间的 ...
- linux centos编译安装php7.3
php7.2的编译安装参考:https://www.cnblogs.com/rxbook/p/9106513.html 已有的之前编译的旧版本php: mv /usr/local/php /usr/l ...
- WebGL学习笔记(九):阴影
3D中实现实时阴影技术中比较常见的方式是阴影映射(Shadow Mapping),我们这里也以这种技术来实现实时阴影. 阴影映射背后的思路非常简单:我们先以光的位置为视角进行渲染,我们能看到的东西都将 ...
- Multi-Channel Buffers
This describes a 4 channels buffer of 16 bit samples.Data organisation :Sample 1, front left speaker ...