Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析
1、实验结论
- 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上;
- 分区越多、表上的lob column越多,对数据字典表的访问次数越多;
- 对数据字典表访问次数的大概值(暂不考虑对其它数据字典表的访问)是可量算的。
2、实验目的
在04-不同分区粒度+全局空间索引查询效率对比一文中,我们看到了某种趋势:在四千万条要素量级下,分区粒度越细,全局空间索引查询效率越低。虽然看到了这种现象,但当时尚不能解释深层次的原因。本文的目的,既是探索研究出现这一现象的原因。
3、实验方法
分别以按县分区、按省分区两种方式来组织2531个区县、共46982394条要素。在两个分区表上均创建全局空间索引。按县分区表共有2531个分区,按省分区表共有43个分区。
开启10046事件,跟踪SDO_FILTER操作。10046事件将trace数据库所有的SQL请求,包括递归与与非递归的SQL请求,得到trc文件。然后按如下3步来分析:
- 逐行对比两个trc文件;
- 使用tkprof工具分析trc文件,按prsela,exeela,fchela(解析时间、执行时间、获取时间)排序SQL;
- 根据绑定变量的值分析递归查询查询了数据字典的哪些内容。
4、实验结果
4.1 逐行对比trc文件
两个trc文件内容基本一致。差别在于对于相同的SQL,其执行次数、elapsed、返回记录数、等待事件等存在差异。
4.2 使用tkprof分析trc文件
因为本文主要分析的是不同分区粒度下,空间查询性能的差异,因此在使用tkprof分析trc文件时,将从elapsed入手分析。而elapsed又包括parse、execute、fetch三种数据库调用类型,所以将指定sort = prsela,exeela,fchela。使用tkprof生成格式化文本的命令如下:
Tkprof db12c...trc country.txt sys=yes aggregate=yes sort=prsela,exeela,fchela
下文将以在按县分区空间查询中耗时较多的一系列SQL为参照,比较相同SQL在按省分区空间查询中的耗时。
Seg$
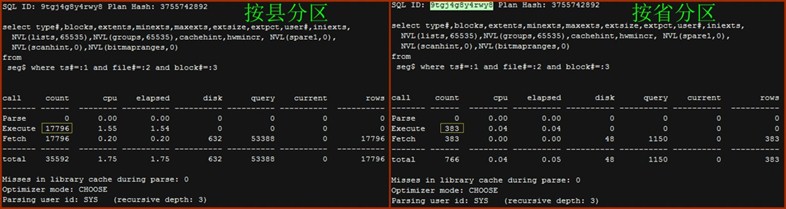
按县分区对SQL ID为9tgj4g8y4rwy8的SQL执行了17796次,总耗时1.75s;而按省分区对相同SQL的执行次数仅为383次,总耗时为0.05s。SQL查询的对象是seg$,seg$是数据字典表,每条记录表示一个ORACLE Segment。为什么会有差异呢?在3.3会说明。
- Lobfrag$
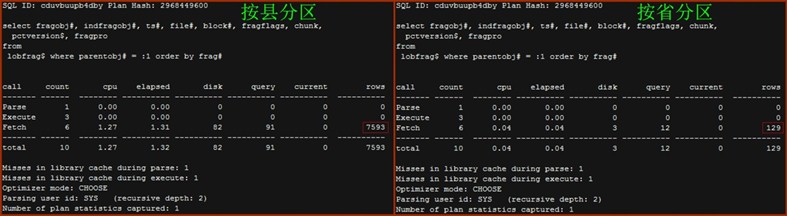
按县分区对SQL ID为cduvbuupb4dby的SQL返回了7593条记录,总耗时1.32s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.04s。SQL查询的对象是lobfrag$,lobfrag$是数据字典表,每条记录表示一个lob fragment。如果仔细观察,会发现7593是2531(分区个数)的3倍,而129是43的3倍。是巧合还是有必须的联系?在3.3会说明。
- Obj$
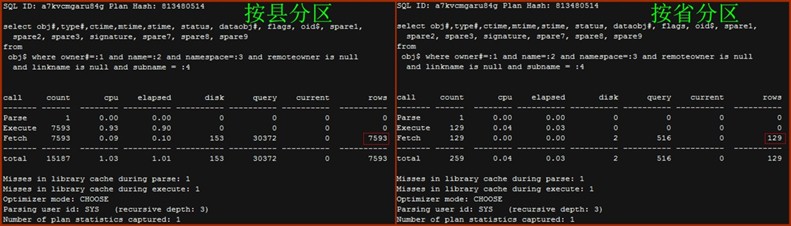
按县分区对SQL ID为a7kvcmgaru84g的SQL返回了7593条记录,总耗时1.01s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.03s。SQL查询的对象是obj$,obj$是数据字典表,每条记录表示一个object。
- Indpart$
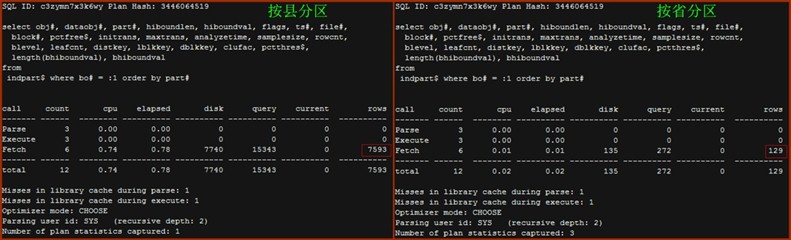
按县分区对SQL ID为a7kvcmgaru84g的SQL返回了7593条记录,总耗时0.78s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.02s。SQL查询的对象是indpart$,indpart$是数据字典表,每条记录表示一个index parttition。
- Obj$(2)

按县分区对SQL ID为87gaftwrm2h68的SQL返回了7697条记录,总耗时0.45s;而按省分区对相同SQL的返回记录仅为210条,总耗时为0.02s。SQL查询的对象也是obj$。
- Tabpart$
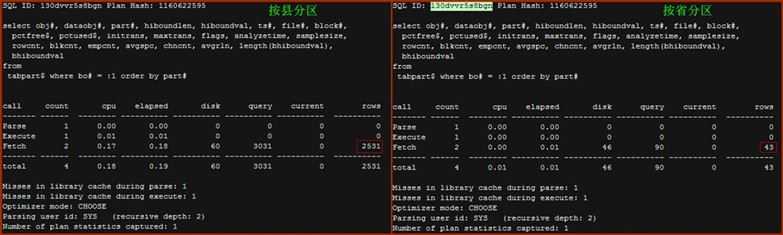
按县分区对SQL ID为87gaftwrm2h68的SQL返回了2531条记录,总耗时0.19s;而按省分区对相同SQL的返回记录仅为43条,总耗时为0.01s。SQL查询的对象是tabpart$, tabpart$是数据字典表,每条记录表示一个table parttition。
- SDO_FILTER
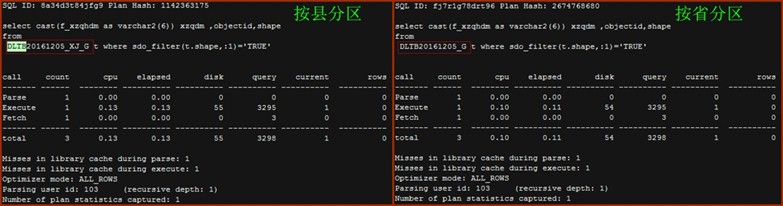
在本例中,按县分区和按省分区,在全局空间索引下,SDO_FILTER的效率相当。注意,该例查询范围内没有返回要素。
- 其它
其它还有一些递归SQL,其查询对象包括hist_head$、histgrm$等数据字典表。因为对这些对象的查询与分区个数相关度不大,因此不着重分析。
4.3 分析数据字典的访问内容
对seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$字典表的访问次数似乎都表现出了与分区个数的正相关性。那到底存不存在正相关性呢?
通过编写Shell脚本,将3.2(1)-(8)SQL语句中的绑定变量值提取出来,然后与相应的数据字典表进行JOIN操作,发现:
- Seg$
查询内容包括所有的lob partition 、index partition、table partition 以及sys和mdsys用户下的字典表、元数据表、少量其它表。本例中的两个图层都包含3个lob column,分别是sdo_geometry.sdo_elem_info、sdo_geometry.sdo_ordinate、se_anno_cad_data,而每个lob column上会存在一个lobindex。以按县分区图层为例,table partition有2531个,lob partition有2531*3个,index partition 有2531*3。
- Lobfrag$
查询内容包括所有的lob partition。以按县分区图层为例,lob partition有2531*3个。
- Obj$
查询内容包括所有的lob partition。以按县分区图层为例,lob partition有2531*3个。
- Indpart$
查询内容包括所有index partiton。以按县分区图层为例,lob partition有2531*3个。
- Obj$(2)
查询内容包括所有的lob partition、以及sys和mdsys用户下的字典表、少量其它表。在本例中,访问sys用户下61张表,mdsys用户下23张表。
- Tabpart$
查询内容包括所有table partiton。以按县分区图层为例,table partiton有2531个。
5、实验结论
- 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上;
- 分区越多、表上的lob column越多,对数据字典表的访问次数越多;
- 对数据字典表访问次数的大概值(暂不考虑对其它数据字典表的访问)是可量算的。假设分区数以X表示,lob column个数以Y表示,不同字典表的访问次数见下表:
|
数据字典表 |
访问次数 |
|
Seg$ |
(1+2Y)*X |
|
Lobfrag$ |
XY |
|
Obj$ |
XY |
|
Indpart$ |
XY |
|
Obj$(2) |
XY |
|
Tabpart$ |
X |
若已经获知对各数据字典表的平均访问时间,甚至可以估算查询耗时。在每例中seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$,各数据字典表的平均访问时间约为100us、240us、50us、150us、180us、120us。因此可估算时间为:
Elapsed all= 100*(1+2Y)*X + 240*Y*X + 50*X*Y + 150*Y*X + 180*Y*X + 120*X =X(820Y+220)
Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析的更多相关文章
- linux下使用crontab实现定时PHP计划任务失败的原因分析
这篇文章主要介绍了linux下使用crontab实现定时PHP计划任务失败的原因分析,需要的朋友可以参考下 很多人在linux下使用crontab实现PHP执行定时任务却未能成功,不能生成缓存.本 ...
- 下拉刷新和UITableView的section headerView冲突的原因分析与解决方案
UITableView:下拉刷新和上拉加载更多 [转载请注明出处] 本文将说明具有多个section的UITableView在使用下拉刷新机制时会遇到的问题及其解决方案. 工程地址在帖子最下方,只需要 ...
- Oracle Spatial分区应用研究之七:同等分区粒度下全局索引优于分区索引的原因分析
1.实验结论 同等分区粒度下,使用分区空间索引进行空间查询,比使用全局空间索引进行查询,对数据字典表的访问次数更多.假设分区数为X,则大概多3X次访问.具体说明见6实验结论. 2.实验目的 在之前的测 ...
- Oracle Spatial分区应用研究之四:不同分区粒度+全局空间索引效率对比
1.实验目的 在实验之前先回答这样一个问题——对同一份数据使用不同的分区粒度,但均创建全局空间索引,问:它们的全局空间索引一致吗? 怎样算是一致的呢?R-TREE的树结构一致算一致吗?空间索引条目数及 ...
- Oracle Spatial GIS相关研究
1.Oracle Spatial 概念相关 Oracle Spatial 是Oracle 数据库强大的核心特性,包含了用于存储矢量数据类型.栅格数据类型和持续拓扑数据类型的原生数据类型.Oracle ...
- Oracle Spatial分区应用研究之八:不同分区粒度在1.5亿要素量级下的查询性能
以土地调查地类图斑层作为测试数据,共计约1.5亿条要素.随机生成90次各比例尺的查询范围,在ORACLE 11gr2数据库中进行空间查询,记录查询耗时.最后计算平均值和第90百分位数,结果如下图所示: ...
- Oracle Spatial分区应用研究之五:不同分区粒度+本地空间索引效率对比
1.实验目的 若使用本地空间索引,不同分区粒度将产生不同索引组织,其索引分区个数.大小.R-TREE树结构均不相同.那么,在什么分区粒度下的本地空间索引效率较高呢? 2实验数据 实验数据为全国2531 ...
- Oracle Spatial分区应用研究之二:按县分区与按省分区对比测试报告
1.实验目的 在上一轮的实验中,oracle 11g r2版本下,在87县市实验数据的基础上,比较了分表与分区的效率,得出了分区+全局索引效率较高的结论(见上一篇博客).不过我们尚未比较过不同的分区粒 ...
- Oracle Spatial分区应用研究之三:县市省不同分区粒度的效率比较
在<Oracle Spatial分区应用研究之一:分区与分表查询性能对比>中已经说明:按县分区+全局空间索引效率要优于按县分区+本地空间索引,因此在该实验报告中,将不再考虑按县分区+本地空 ...
随机推荐
- Spark常规性能调优
1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行 ...
- js 复选框回显
<div class="control-group"> <label class="control-label">客户状态:</l ...
- What is react-native link?
What is react-native link? or Should you just use react-native link when linking any dependency or s ...
- spring:过滤器和拦截器
过滤器:网络通信模型的会话层控制: 拦截器:事务处理的aop注入(生命周期监控). 对于Servlet Filter,官方文档中说的很好, 并且给出了常见的应用场景. A filter is an o ...
- 【C/C++】static关键字
首先static的最主要功能是隐藏,其次因为static变量存放在静态存储区,所以它具备持久性和默认值0. static性质 隐藏 当同时编译多个文件时,未加static前缀的全局变量和函数都具有全局 ...
- 再谈System.BadImageFormatException
今天,当我们继续学习.NET异常处理系列时,我们将查看System.BadImageFormatException.System.BadImageFormatException与GIF或JPG无关,而 ...
- Bzoj 4517: [Sdoi2016]排列计数(排列组合)
4517: [Sdoi2016]排列计数 Time Limit: 60 Sec Memory Limit: 128 MB Description 求有多少种长度为 n 的序列 A,满足以下条件: 1 ...
- 垃圾邮件分类实战(SVM)
1. 数据集说明 trec06c是一个公开的垃圾邮件语料库,由国际文本检索会议提供,分为英文数据集(trec06p)和中文数据集(trec06c),其中所含的邮件均来源于真实邮件保留了邮件的原有格式和 ...
- trutle库的使用基础
turtle库的使用: 概括: turtle绘图体系:1969年诞生,主要用于程序设计入门 Python语言的标准库之一 入门级的图形绘制函数库 原理: turtle的原(wan)理(fa) (tur ...
- virsh使用总结
做下面操作前先安装这些工具: yum install virt-install libvirt-admin libvirt-client libvirt-daemon libvirt主要的配 ...