NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好。
论文:ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
ELECTRA全称为Efficiently Learning an Encoder that Classifies Token Replacements Accurately 。论文中提出了一个新的任务—replaced token detection,简单来说该任务就是预测预训练语言模型生成的句子中哪些token是原本句子中的,哪些是由语言模型生成的。
模型的整个结构如下:

整个训练模式有点类似于GAN,模型由一个生成器和一个判别器组成的,这个判别器就是我们最终使用的预训练模型,生成器可以采用任何形式的生成模型,在这里作用采用了MLM语言模型(bert之类的)来作为生成器,具体流程如下:
1)首先对一个距离mask一些词,将这个mask后的句子作为生成器的输入。
2)生成器将这些mask的词预测成vocab中的token,如上面将painting mask后输入到生成器中,然后生成器重构输入,将mask预测成car。
3)将生成器的输出作为判别器的输入,判别器去预测这个句子中的每个token是真实的token,还是由生成器生成的虚假的token,注意:如果生成器生成的词和真实词一致,则当作真实的token,例如上面讲the mask后生成器仍预测为the,则the在判别器中也是真实值,标签为正。
模型的整个流程确定了,剩下的就是该怎么训练了,在这里训练方式和GAN并不相同,在GAN中会将判别器的结果作为训练生成器的损失,但由于NLP中句子是离散的,因此无法通过梯度下降的方式来将判别器的结果反向传播来训练生成器,因此在这里作者将MLM损失作为生成器的损失,而将replaced token detection的损失作为判别器的损失,具体损失函数如下:
生成器的损失:
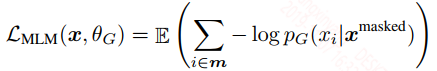
生成器的损失就是MLM语言模型中预测mask词的损失。
判别器的损失:
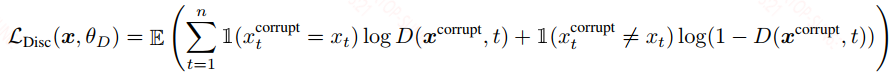
判别器的损失就是token detection的损失,每个token都有两个可能性——真实和虚假,因此每个token是一个二分类,然后在这里作者考虑了所有的token。
最终整个模型的损失为:
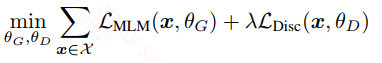
$\lambda$ 是一个权重系数,作者认为生成器的任务比较难,因此损失比较大,但是判别器任务相对简单,因此损失会比较小,因此将判别器的权重设大一点,作者训练时使用了50。以上就是整个训练过程。
权值共享
作者在训练的时候采用了一些策略,在这里作者共享生成器和判别器的权值,作者对比了不共享,共享embdding层,共享所有层(共享所有层时需要保证生成器和判别器的架构一样),作者得出不共享时性能为83.6,共享embedding层为84.3,共享所有层为84.4,因为共享所有层提升不明显,且还需要保证生成器和判别器结构一致,因此作者只共享了embedding层。
更小的生成器
作者在这里对比了不同尺寸生成器的性能,结果发现当生成器大小为判别器的1/4-1/2时,模型性能最好,具体如下图:

不同的训练模式
作者对比了不同的训练模式,除当前这种模式之外,又给出了两种新的模式:
1)采用GAN的方式,用reinforce算法将生成器的最小化MLM损失改成了最大化replaced token detection 损失。
2)采用2-stage的方式,首先训练生成器,然后用生成器的参数初始化判别器,在这里要保证生成器和判别器结构相同。作者也说了如果从0开始训练判别器,效果很差。
具体对比结果如下:
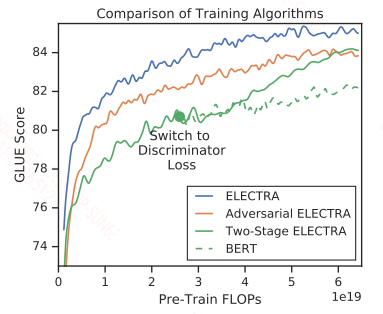
小模型性能对比:

在这里作者给出了一个14M的小模型ELECTRA-small,效果超过了distillbert,gpt,同等大小的bert-small。这个模型在V100单卡上训练即可。
大模型性能对比:

在同等大小的大模型上,性能也和当前最佳roberta性能相当,但是训练计算量只有roberta的1/4。
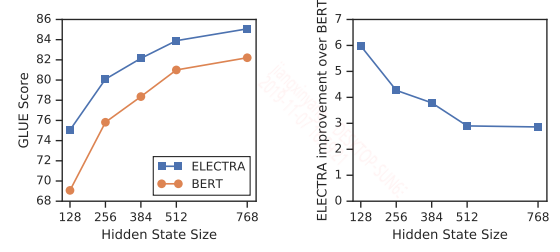
另外作者还分析了计算效率,作者认为判别器中的全词预测能充分的利用计算效率,而只预测15%的mask的token是很浪费计算资源的,因此全词预测可以加快模型的收敛速度。另外同等大小下,ELECTRA的性能优于bert,且模型越小,优势越明显,如下图所示:
NLP中的预训练语言模型(五)—— ELECTRA的更多相关文章
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
- NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键, ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
随机推荐
- 标签中href="javascript:;"表示什么意思?
1.标签的 href 属性用于指定超链接目标的 URL,href 属性的值可以是任何有效文档的相对或绝对 URL,包括片段标识符和 JavaScript 代码段. 2.javascript: 是一个伪 ...
- 【tyvj1858】xlkxc(拉格朗日插值)
传送门 题意: 求\(\sum_{i=0}^n\sum_{j=1}^{a+id}\sum_{k=1}^{j}k^K,n,a,d\leq 10^9,K\leq 100\). 思路: 最右边这个和式为一个 ...
- redis数据存入乱码问题解决方法
第一步:配置RedisTemplate @Configuration public class RedisConfigurtion { @Autowired private RedisTemplate ...
- 201271050130-滕江南-《面向对象程序设计(java)》第十二周学习总结
201271050130-滕江南-<面向对象程序设计(java)>第十二周学习总结 项 目 内 容 这个作业属于哪个课程 https://www.cnblogs.co ...
- RAID几种方式
RAID(Redundant Array of Independent Disk 独立冗余磁盘阵列)技术是加州大学伯克利分校1987年提出,最初是为了组合小的廉价磁盘来代替大的昂贵磁盘,同时希望磁盘失 ...
- 日常笔记6C++标准模板库(STL)用法介绍实例
一.vector常见用法详解 vector翻译为向量,但是这里翻译成变长数组的叫法更好理解. 如果typename是一个STL容器,定义的时候要记得在>>符号之间加上空格,因为在C++11 ...
- 使用system V实现读者写者问题
#include <stdio.h> #include <sys/sem.h> #include <sys/ipc.h> #include <string.h ...
- OpenCV Error: Unknown error code -10 (Raw image encoder error: Empty JPEG image (DNL not supported)) in throwOnEror 错误
出现上面这样的错误可以肯定是传了空指针导致的, 刚开始出现这样的问题, 并且是概率性的, 网上找了一遍都没找到解决方案, 然后自己一行一行代码注释, 发现还是会出现这样的问题, 当时就懵逼了, 我从打 ...
- xml、bean、json互转工具,可直接CV就用
1.jar包 <dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifactI ...
- Anaconda入门教程【快速掌握】
Anaconda 使用指南 概述 很多学习python的初学者甚至学了有一段时间的人接触到anaconda或者其他虚拟环境工具时觉得无从下手, 其主要原因就是不明白这些工具究竟有什么用, 是用来做什么 ...