MySQL分组查询每组最新的一条数据(通俗易懂)
开发中经常会遇到,分组查询最新数据的问题,比如下面这张表(查询每个地址最新的一条记录):

sql如下:
-- ----------------------------
-- Table structure for test
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`create_time` timestamp(0) NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES (1, '张三1', '北京', '2019-09-10 11:22:23');
INSERT INTO `test` VALUES (2, '张三2', '北京', '2019-09-10 12:22:23');
INSERT INTO `test` VALUES (3, '张三3', '北京', '2019-09-05 12:22:23');
INSERT INTO `test` VALUES (4, '张三4', '北京', '2019-09-06 12:22:23');
INSERT INTO `test` VALUES (5, '李四1', '上海', '2019-09-06 12:22:23');
INSERT INTO `test` VALUES (6, '李四2', '上海', '2019-09-07 12:22:23');
INSERT INTO `test` VALUES (7, '李四3', '上海', '2019-09-11 12:22:23');
INSERT INTO `test` VALUES (8, '李四4', '上海', '2019-09-12 12:22:23');
INSERT INTO `test` VALUES (9, '王二1', '广州', '2019-09-03 12:22:23');
INSERT INTO `test` VALUES (10, '王二2', '广州', '2019-09-04 12:22:23');
INSERT INTO `test` VALUES (11, '王二3', '广州', '2019-09-05 12:22:23');
平常我们会进行按照时间倒叙排列然后进行分组,获取每个地址的最新记录,sql如下:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC) a GROUP BY address
但是查询结果却不是我们想要的:

执行时间按倒叙排列结果为:
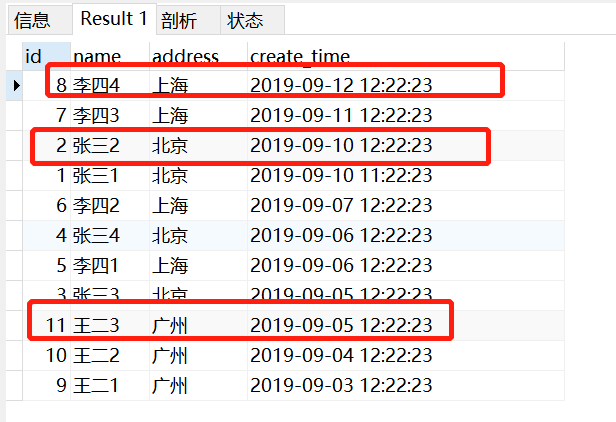
所以真正想要得到的结果是id为2/8/11的记录,上面的查询得到的却是1/5/9,这是为什么呢?
因为在mysql5.7的时候,子查询的排序已经变为无效了,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序的原因。
那么我们应该怎么查呢,有两种方式:
第一种:
SELECT * FROM(SELECT * FROM test ORDER BY create_time DESC LIMIT 10000) a GROUP BY address
结果为:
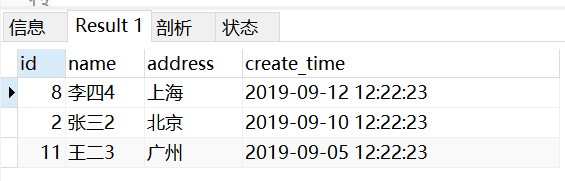
对子查询的排序进行limit限制,此时子查询就不光是排序,所以此时排序会生效,但是限制条数却只能尽可能的设置大些
第二种:
SELECT t.* FROM (SELECT address,max(create_time) as create_time FROM test GROUP BY address) a LEFT JOIN test t ON t.address=a.address and t.create_time=a.create_time
通过MAX函数获取最新的时间和地址(因为需要按照地址分组),然后作为一张表和原来的数据进行联查,
条件就是地址和时间要和获取的最大时间和地址相等,此时结果为:

这两种方式的查询效率差不太多,第二种比第一种查询稍微快一点,可能是由于第二种方式的子查询只有两个字段(时间,被分组字段)的缘故吧!
感兴趣的可以照一张字段多的数据量大的表查询一下比较比较。
PS:第二种方式中最新的记录,不能同时地点和时间都相同,如果出现这种情况,第二种方式会查出把这两条记录都查出来,而第一条不会。
所以根据业务和数据情况来选择其中一种方式,毕竟效率差不太多。
MySQL分组查询每组最新的一条数据(通俗易懂)的更多相关文章
- mysql分组查询获取组内某字段最大的记录
id sid cid 1 1 12 1 23 2 1 以sid分组,最后取cid最大的那一条,以上要取第2.3条 1 方法一: select * from (select * from table o ...
- MySQL分组查询获取每个学生前n条分数记录(分组查询前n条记录)
CREATE TABLE `t_test` ( `id` ) NOT NULL AUTO_INCREMENT, `stuid` ) NOT NULL, `score` ) DEFAULT NULL, ...
- mysql 分组查询
mysql 分组查询 获取id最大的一条 (1)分组查询获取最大id SELECT MAX(id) as maxId FROM `d_table` GROUP BY `parent_id` ; (2) ...
- Oracle和MySQL分组查询GROUP BY
Oracle和MySQL分组查询GROUP BY 真题1.Oracle和MySQL中的分组(GROUP BY)有什么区别? 答案:Oracle对于GROUP BY是严格的,所有要SELECT出来的字段 ...
- sql 分组取每组的前n条或每组的n%(百分之n)的数据
sql 分组取每组的前n条或每组的n%(百分之n)的数据 sql keyword: SELECT * ,ROW_NUMBER() OVER(partition by b.UserID order by ...
- 转: 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
- Mysql 保留最新的10条数据
Mysql每天执行计划,保留最新的10条数据,其余的删除 1.Mysql 保留最新的10条数据 sql语句: DELETE tb FROM tbname AS tb,( SELECT id FROM ...
- sql 查询某个条件多条数据中最新的一条数据或最老的一条数据
sql 查询某个条件下多条数据中最新的一条数据或最老的一条数据 test_user表结构如下: 需求:查询李四.王五.李二创建的最初时间或者最新时间 1:查询最初的创建时间: SELECT * FRO ...
- 从Mysql某一表中随机读取n条数据的SQL查询语句
若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1)).例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机 ...
随机推荐
- Python3基础 None 使用is来判断
Python : 3.7.3 OS : Ubuntu 18.04.2 LTS IDE : pycharm-community-2019.1.3 ...
- 自动生成LR脚本且运行
背景:作为一个测试,特别是性能测试,尤其在活动的测试,时间紧,有很多要测的,我们的LR11因为浏览器兼容问题全录制不了脚本了,用浏览器加代理或手机加代理录制,我感觉好麻烦 ,所以就想如果能用脚本把所有 ...
- K8S使用入门-创建第一个容器
前面两个教程我们已经使用kubekit将K8S搭建起来了.但是,没有将实际使用中需要在K8S上部署我们的容器创建起来的教程,都是耍流氓.所以,经过几番折腾,我回来给自己洗白了.之前一直卡在创建第一个容 ...
- hive 字符串截取
语法 :substr(字段,starindex,len) 下标从 1 开始 测试 ,) from siebel_cx_order limit ; -- -- -- -- -- -- -- -- -- ...
- sizeof(类名字)
析构函数,跟构造函数这些成员函数,是跟sizeof无关的,因为我们的sizeof是针对实例,而普通成员函数,是针对类体的,一个类的成员函数,多个实例也共用相同的函数指针,所以自然不能归为实例的大小. ...
- 记一次修复yum被破坏
现象 # yum There was a problem importing one of the Python modules required to run yum. The error lead ...
- [转帖]如何查看windows某个目录下所有文件/文件夹的大小?
如何查看windows某个目录下所有文件/文件夹的大小? https://www.cnblogs.com/gered/p/10208281.html 挺好的工具 linux 上面 我就是使用 du - ...
- Label&Button
Button中的bg参数设置按钮背景颜色,fg参数设置字体颜色 pack中的fill参数告诉Packer让QUIT按钮占据剩余的水平空间,而expand参数则引导它填充整个水平可视空间,将按钮拉伸到左 ...
- 【Go】开发中遇到的坑——持续更新
关于CGo多语言编译 问题出现在将openCV封装到go语言的时候.在编译时需要设置 CGO_ENABLED=1 GOOS=linux GOARCH=amd64 go build -o xxx mai ...
- Stack实现
栈的三种操作算法很简单 STACK-EMPTY(S) 1 if S.top == 0 2 return TRUE 3 else return FALSE PUSH(S, x) 1 S.top = ...