spark中的多目录输出及压缩
最近接到一个需求,需要对spark的结果分目录输出,百度之后找到了解决方案,大多都是spark 按照key分目录输出,
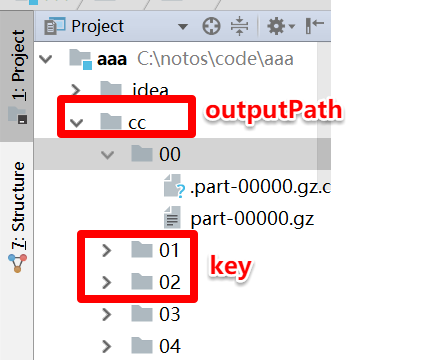
class RDDMultipleTextOutputFormat[K, V]() extends MultipleTextOutputFormat[K, V]() {
//private val output:TextOutputFormat[String, String] = null
override def generateFileNameForKeyValue(key: K, value: V, name: String) : String = {
val dt = Utils.getDt(value.toString.split("\t",-1)(2))
s"$dt/$name"
}
}
lines.saveAsHadoopFile(
outPath,
classOf[NullWritable], //这里定义的是NullWritable,那么pairRdd 就应该是RDD[NullWritable,String]类型的
classOf[String],
classOf[RDDMultipleTextOutputFormat[_, _]],classOf[GzipCodec])
spark中的多目录输出及压缩的更多相关文章
- 给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
1 import java.text.SimpleDateFormat; 2 import org.apache.hadoop.fs.*; 3 4 public class E_RecursiveRe ...
- spark map函数中使用println无法输出
问题 // 每个点为hardData中的一个Array val hardData = spark.read.textFile(args(0)).rdd .map(_.split(" &quo ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- 在 Spark 中使用 IPython Notebook
本文是从 IPython Notebook 转化而来,效果没有本来那么好. 主要为体验 IPython Notebook.至于题目,改成<在 IPython Notebook 中使用 Spark ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- 鸟哥的linux私房菜 - 第5/6/7/9章(在线求助 man page、Linux档案权限与目录配置、Linux档案与目录管理、压缩与打包)
第五章.在线求助 man page X window与文本模式的切换 Ctrl+Alt+F1~F6:文字接口登入tty1~tty6终端机: Ctrl+Alt+F7:图形接口桌面. 注销当前用户:exi ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- ASP.NET MVC 4 (十一) Bundles和显示模式--asp.net mvc中 @Scripts.Render("~/bundles/jquery")是什么意思? 在布局文件中使用Scripts.Render()输出脚本包,Styles.Render()输出风格包:
ASP.NET MVC 4 (十一) Bundles和显示模式 ASP.NET MVC 4 引入的js打包压缩功能.打包压缩jquery目录下的文件,在布局文件中使用Scripts.Render()输 ...
- JAVA 实现将多目录多层级文件打成ZIP包后保留层级目录下载 ZIP压缩 下载
将文件夹保留目录打包为 ZIP 压缩包并下载 上周做了一个需求,要求将数据库保存的 html 界面取出后将服务器下的css和js文件一起打包压缩为ZIP文件,返回给前台:在数据库中保存的是html标签 ...
随机推荐
- 【VS2019】Web项目发布时提示无法连接FTP服务器
使用 Visual Studio 2019 时出现的问题 环境:win10 ltsc 场景 发布Web项目到FTP时 失败,并提示 _无法打开网站"ftp://...".未安装与 ...
- RESTful规范总结
思维导图xmind文件:https://files-cdn.cnblogs.com/files/benjieming/RESTful%E8%A7%84%E8%8C%83.zip
- 开发--Deepin系统安装
开发|Deepin系统安装 在18小时前,我刚刚萌生了一个将我的笔记本换成linux系统.在18小时后的现在,在我各种试错之后,笔记本已经开始跑起linux了.在科技的时代,只要是想法,都可以试一试. ...
- 为啥git会这么差!!!!
删除分支 git push origin --delete Chapater6 可以删除远程分支Chapater6 git branch -d Chapater8 可以删除本地分支(在主分支中) ...
- CTF-代码审计(3)..实验吧——你真的会PHP吗
连接:http://ctf5.shiyanbar.com/web/PHP/index.php 根据题目应该就是代码审计得题,进去就是 日常工具扫一下,御剑和dirsearch.py 无果 抓包,发现返 ...
- There is already an open DataReader associated with this Command which must be closed first
通常出现在嵌套查询数据库(比如在一个qry的遍历时,又进行了数据库查询) 通过在连接字符串中允许MARS可以轻松解决这个问题. 将MultipleActiveResultSets = true添加到连 ...
- Mysql高性能优化规范
数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割 所有数据库对象名称禁止使用mysql保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来) 数据库对象的命名要能做到见名识意 ...
- Redis内存模型(1):内存统计及划分
1. 内存统计 查看命令:info memory 示例: 部分含义: used_memory: Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存. used_memory_rss: R ...
- Mysql数据库之备份还原(mysqldump,LVM快照,select备份,xtrabackup)
备份类型: 热备份:读写不受影响 温备份:仅可执行读备份 冷备份:离线备份,读写均不能执行,关机备份 物理备份和逻辑备份 物理备份:复制数据文件,速度快. 逻辑备份:将数据导出之文本文件中,必要时候, ...
- 十八、Python面向对象之魔术方法
1.类的比较 class A(object): def __init__(self,value): self.value = value def __eq__(self,other): return ...