SQL入门之查询入门
select语法一般结构:
SELECT [ALL|DISTINCT] <目标列表达式> [别名] [, <目标列表达式> [别名]]...
FROM <表名或视图名> [别名] [,<表名或视图名> [别名]]...
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2>[ASC|DESC]
可知select语句是由几个组件或者说子句构成。有一些子句不可缺少(select子句),但有一些可以不用使用。
| 子句名称 | 使用目的 |
| select | 确定结果集中应该包含哪些列 |
| from | 指明所要提取数据的表, 以及这些表是如何连接的 |
| where | 过滤不需要的数据 |
| group by | 用于对具有相同列值的行进行分组 |
| having | 过滤掉不需要的组(必须同group by子句一起用) |
| order by | 按一个或多个列,对最后结果集中的行进行排序 |
0.select子句
作为select语句第一个部分,select是最后被执行的,因为需要知道结果集中所有可能包含的列。
select * from department;
这里*代表通配符,意思是从department表中选择所有的列,相当于将department中所有属性都写出来,如果要只显示需要的属性列,直接写出即可。当然也可以对select子句进行一下修饰。
- 字符,比如数字或字符串
- 表达式,如dept_id * 3
- 调用内建函数,如upper(name)
- 用户自定义的函数
通过查询,返回的是每个列的默认属性名,也可以自定义名,即取别名,可以属性名后直接加别名,也可以属性名 as 别名。
默认情况select语句是不去除重复行的,若不需要则在其后加distinct,如果显示所有的则用all(默认)。但是一定要注意:使用distinct,数据库会对查询结果进行排序,这对于较大的结果集是很浪费时间的,降低效率,因此不要随意使用。
1.frome子句
from子句定义了查询中所用的表,以及连接这些表的方式。
2.where子句
where子句用于在结果集中过滤掉不需要的行。
where后面跟的是条件表达式,满足条件的元组将会被选出。如:
select emp_id, fname, lname, start_date, title
from employee
where title = 'Head Teller';
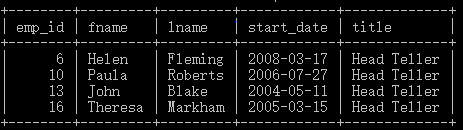
可以看出,仅仅title为Head Teller的元组被列了出来。
条件表达式是多种多样的,这里仅仅用了,相等的条件,其他表达式以后解释。
3.group by和having子句
group by子句用于根据列值对数据进行分组。having子句与group by子句配合使用,选取满足条件的元组。
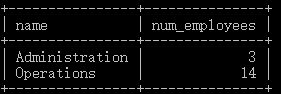
select d.name, count(e.emp_id) num_employees
from department d inner join employee e on d.dept_id = e.dept_id
group by d.name
having count(e.emp_id) > 2;
4.order by子句
order by子句用于对结果集中的原始列数据或是根据列数据计算的表达式结果进行排序。
如一般情况下的查询
select open_emp_id, product_cd
from account;

可见结果没有次序,如果使用order by子句
select open_emp_id, product_cd
from account
order by open_emp_id;

从结果上看,结果按照open_emp_id升序排列(默认),如果想要降序排列,则在后面跟desc。也可以按照多个属性升序或降序排列。
SQL入门之查询入门的更多相关文章
- SQL查询入门(下篇)
SQL查询入门(下篇) 文章转自:http://www.cnblogs.com/CareySon/archive/2011/05/18/2049727.html 引言 在前两篇文章中,对于单表查询 ...
- SQL Server审计功能入门:更改跟踪(Change Tracking)
原文:SQL Server审计功能入门:更改跟踪(Change Tracking) 介绍 更改跟踪是一种轻量型解决方案,它为应用程序提供了一种有效的更改跟踪机制.常规的,自定义变更跟踪和读取跟踪数据, ...
- SQL Server审计功能入门:CDC(Change Data Capture)
原文:SQL Server审计功能入门:CDC(Change Data Capture) 介绍 SQL Server 2008引入了CDC(Change Data Capture),它能记录: 1. ...
- SQL Server AlwaysON从入门到进阶(1)——何为AlwaysON?
本文属于SQL Server AlwaysON从入门到进阶系列文章 本文原文出自Stairway to AlwaysOn系列文章.根据工作需要在学习过程中顺带翻译以供参考.系列文章包含: SQL Se ...
- sql注入(从入门到进阶)
随着B/S模式应用开发的发展,使用这种模式编写应用程序的程序员也越来越多.但是由于这个行业的入门门槛不高,程序员的水平及经验也参差不齐,相当大一部分程序员在编写代码的时候,没有对用户输入数据的合法性进 ...
- MongoDB 入门之查询(find)
MongoDB 入门之查询(find) 1. find 简介 (1)find的第一个参数决定了要返回哪些文档. 空的查询文档会匹配集合的全部内容.默认就是{}.结果将批量返回集合c中的所有文档. db ...
- SQL Server审计功能入门:SQL Server审核 (SQL Server Audit)
原文:SQL Server审计功能入门:SQL Server审核 (SQL Server Audit) 介绍 Audit是SQL Server 2008之后才有的功能,它能告诉你"谁什么时候 ...
- SQL Server AlwaysON从入门到进阶(3)——基础架构
本文属于SQL Server AlwaysON从入门到进阶系列文章 前言: 本文将更加深入地讲解WSFC所需的核心组件.由于AlwaysOn和FCI都需要基于WSFC之上,因此我们首先要了解在Wind ...
- SQL Server AlwaysON从入门到进阶(2)——存储
本文属于SQL Server AlwaysON从入门到进阶系列文章 前言: 本节讲解关于SQL Server 存储方面的内容,相对于其他小节而言这节比较短.本节会提供一些关于使用群集或者非群集系统过程 ...
随机推荐
- 20155239 2016-2017-2 《Java程序设计》第10周学习总(2017-04-22 16:26
教材学习 1.基本概念划分 OIS的七层协议: 应用层.表示层.会话层.运输层.网络层.数据链路层.物理层. OIS的五层协议: 应用层.运输层.网络层.数据链路层.物理层. 由下往上介绍如下: 2. ...
- Odoo中创建模块语句
使用odoo的odoo-bin命令创建模块,比较方便. 进入终端界面(windows中可以是cmd中,linux中可以是$命令提示符下),以下在Windows中为例: python odoo-bin ...
- SPOJ11469 SUBSET
题面 Farmer John's owns N cows (2 <= N <= 20), where cow i produces M(i) units of milk each day ...
- iOS 上架的坑
有3D-touch机型的坑 昨天在上线的时候遇到了一个坑,最后导致的结果是找了好几个小时,直接到半夜才能上线. 入正题: 坑是:项目运行在456上没什么问题,但是在6S以上的机型就有点击事件不响应的情 ...
- VirtualBox复制CentOS后提示Device eth0 does not seem to be present的解决方法
使用VirtualBox复制一份CentOS后重新设置了网卡地址,导致启动网络服务出现下图错误 解决方案 执行命令,查看/etc/udev/rules.d/70-persistent-net.rule ...
- Qt-QML-电子罗盘
使用QML中的Canvas实现电子罗盘绘制,效果图如下 一个简单的电子罗盘,红色N极.其中中间飞机表示当前的指向, 还是比较简单的,直接上代码吧 /* 作者:张建伟 时间:2018年4月27日 简述: ...
- Jenkins+git+Nginx
1.Jenkins 一.tomcat安装 1.下载JDK和Tomcat //通过wget下载 wget http://mirrors.tuna.tsinghua.edu.cn/apache/tomca ...
- RetinaNet 迁移学习到自标数据集
Keras-RetinaNet 在自标数据集 alidq 上训练 detection model RetinaNet 模型部署与环境配置 参考README 数据预处理 数据统计信息: 类别:gun1, ...
- Dilworth定理
来自网络的解释: 定理内容及其证明过程数学不好看不懂. 通俗解释: 把一个数列划分成最少的最长不升子序列的数目就等于这个数列的最长上升子序列的长度(LIS) EXAMPLE 1 HDU 1257 ...
- New York Comic Con 2013 - 2013年纽约动漫展
New York Comic Con - 2013年纽约动漫展 New York Comic Con is the largest pop culture event on the East Coas ...