Python学习---网页爬虫[下载图片]
爬虫学习--下载图片
1.主要用到了urllib和re库
2.利用urllib.urlopen()函数获得页面源代码
3.利用正则匹配图片类型,当然正则越准确,下载的越多
4.利用urllib.urlretrieve()下载图片,并且可以重新命名,利用%S
5.应该是运营商有所限制,所以未能下载全部的图片,不过还是OK的
URL分析:
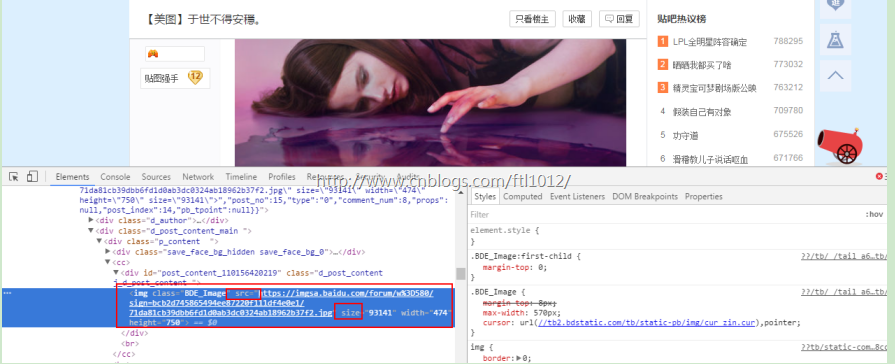
源码:
#coding=utf-8
import re
import urllib
def getHtml(url):
page=urllib.urlopen(url)
html=page.read();
return html
def getImage(html):
reg=r'src="(.*?\.jpg)" size'
imgre=re.compile(reg)
imgeList =re.findall(imgre,html)
x=0
for image in imgeList:
urllib.urlretrieve(image,'%s_hhh.jpg' % x)
x+=1
html=getHtml("https://tieba.baidu.com/p/5256641773")
getImage(html)
Python学习---网页爬虫[下载图片]的更多相关文章
- 【Python】python3实现网页爬虫下载图片
import re import urllib.request # ------ 获取网页源代码的方法 --- def getHtml(url): page = urllib.request.urlo ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- Python 简单网页爬虫学习
#coding=utf-8 # 参考文章: # 1. python实现简单爬虫功能 # http://www.cnblogs.com/fnng/p/3576154.html # 2. Python 2 ...
- python 爬虫--下载图片,下载音乐
#下载图片 imgUrl='http://www.pptbz.com/pptpic/UploadFiles_6909/201211/2012111719294197.jpg' r=requests.g ...
- Day3-scrapy爬虫下载图片自定义名称
学习Scrapy过程中发现用Scrapy下载图片时,总是以他们的URL的SHA1 hash值为文件名,如: 图片URL:http://www.example.com/image.jpg 它的SHA1 ...
- python实现网络爬虫下载天涯论坛帖子
最近发现天涯论坛是一个挺有意思的网站,有各种乱七八糟的帖子足以填补无聊时候的空虚感,但是相当不爽的一件事就是天涯的分页模式下想连贯的把楼主的内容看完实在是太心酸了,一个999页的帖子,百分之九十都是无 ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
随机推荐
- 解决问题的思维方式之Problem->Desgin->Solution(笔记)
Problem->Desgin->Solution: 1.对于每个需要实现的功能问题,我们都称之为Problem(问题). 2.解决问题的具体思考过程,寻求解决问题的方案,即为Desgin ...
- uvm_config_db在UVM验证环境中的应用
如何在有效的使用uvm_config_db来搭建uvm验证环境对于许多验证团队来说仍然是一个挑战.一些验证团队完全避免使用它,这样就不能够有效利用它带来的好处:另一些验证团队却过多的使用它,这让验证环 ...
- gradle本地、远程仓库配置--转
https://blog.csdn.net/x_iya/article/details/75040806 本地仓库配置配置环境变量GRADLE_USER_HOME,并指向你的一个本地目录,用来保存Gr ...
- Wahrscheinlichkeitstheorie und mathematische Statistik
Übliches Wort 正态分布:Die Normalverteilung 条件概率:Die Bedingte Wahrscheinlichkeit 排列:Die Permutation 组合:D ...
- CC2530zigbee技术-简介协议栈
前言 说实话,我喜欢自己的原创,虽然我写得可能简单了,但我觉得自己在写博客的路途上,一点一点地积累知识,我也借鉴别人的东西,特别是在写这篇文章时所使用的是markdownpad2写的,原来我根本就不知 ...
- 一句话讲清URI、URL、URN
关于URI,URL ,URN URN(Uniform Resource Name):统一资源名称 URL(Uniform Resource Locator):统一资源定位符 URI(Uniform R ...
- i.mx6 Android5.1.1 Zygote
0. 总结: 0.1 相关源码目录: framework/base/cmds/app_process/app_main.cppframeworks/base/core/jni/AndroidRunti ...
- vuex源码分析3.0.1(原创)
前言 chapter1 store构造函数 1.constructor 2.get state和set state 3.commit 4.dispatch 5.subscribe和subscribeA ...
- [javaSE] 进制转换(二进制十进制十六进制八进制)
十进制转二进制,除2运算 十进制6转二进制是 110 (注意从右往左写,使用算式从下往上写) 二进制转十进制,乘2过程 二进制110转十进制 0*2的0次方+1*2的1次方+1*2的2次方=6 对 ...
- Java8增强的Map集合
Map集合简介 Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组用于保存Map里的vlaue,key和value都可以是任何引用类型的数据. M ...