随机森林学习-sklearn
随机森林的Python实现 (RandomForestClassifier)

# -*- coding: utf- -*-
"""
RandomForestClassifier
skleran 的随机森林回归模型,应用流程。
.源数据随机的切分:%作为训练数据 %最为测试数据
.训练数据中的因变量(分类变量)处理成数字形式
.设定参数,训练/fit
.对测试数据,预测/predict结果y_pre
.对预测数据y列,y_pre列,生成混淆矩阵,显示分类/预测效果
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names) #合并 自变量 和 因变量
df['is_train'] = np.random.uniform(, , len(df)) <= . #相当于随机抽取了75%作为训练数据
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names) #将数字类别转为文字类别
df.head() train, test = df[df['is_train']==True], df[df['is_train']==False] #拆分训练集和测试集 features = df.columns[:] # 前4个指标 为自变量
clf = RandomForestClassifier(n_jobs=) # n_jobs=2是线程数
y, _ = pd.factorize(train['species']) # 将文字类别 转为数字类别。一种序列化方法。第一参数是序列化后结果,第二个时参考
clf.fit(train[features], y) #训练过程 preds = iris.target_names[clf.predict(test[features])] # 获取测试数据预测结果
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds']) #生成混淆矩阵
#有意思的输出
clf.feature_importances_ # 输出 自变量的总要程度
clf.predict_proba(test[features]) #输出每个测试样本对应几种数据类型的概率值
150个数据,112做训练 38个最测试.
df数据示例- 测试数据,输出结果-
测试数据,输出结果-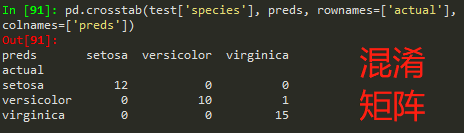
参考:[Machine Learning & Algorithm] 随机森林(Random Forest)
=============================================================================================================
知识点:
对 ‘RandomForestClassifier’ 原文 的 翻译
知识点:
#将数字类别转为文字类别
pd.Categorical.from_codes([0,1,2,1,0,0,1,-1], ['小猫','中猫','大猫'])
#Out[76]:
#[小猫, 中猫, 大猫, 中猫, 小猫, 小猫, 中猫, NaN]
#Categories (3, object): [小猫, 中猫, 大猫]
知识点:
# pd.factorize 用法
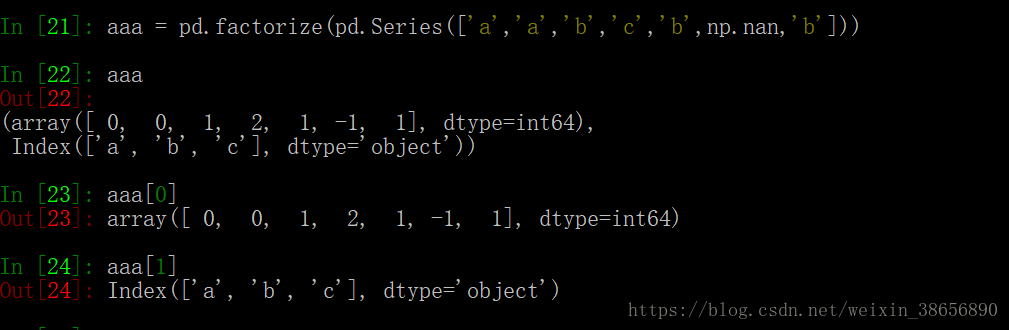
从例子中可以看到 pd.factorize() 返回的是一个tuple ,包含连个元素,第二个是源数据中所有数据的类别,当然取出了nan ,第一个是源数据在类别中对应的序号组成的array 看到这里可以发现 和pd.Categorical() 真的是非常像了。
知识点:
Pandas:透视表(pivotTab)和交叉表(crossTab)
知识点:
numpy.random.seed(1) #设定随机种子且仅在下一次随机时有效.
介绍Python-random模块的链接:
==================================================================================================================================================
随机森林学习-sklearn的更多相关文章
- 随机森林学习-2-sklearn
# -*- coding: utf-8 -*- """ RandomForestClassifier skleran的9个模型在3份数据上的使用. 1. 知识点: skl ...
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- 100天搞定机器学习|Day33-34 随机森林
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 04-10 Bagging和随机森林
目录 Bagging算法和随机森林 一.Bagging算法和随机森林学习目标 二.Bagging算法原理回顾 三.Bagging算法流程 3.1 输入 3.2 输出 3.3 流程 四.随机森林详解 4 ...
- 【笔记】随机森林和Extra-Trees
随机森林和Extra-Trees 随机森林 先前说了bagging的方法,其中使用的算法都是决策树算法,对于这样的模型,因为具有很多棵树,而且具备了随机性,那么就可以称为随机森林 在sklearn中封 ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- (数据科学学习手札26)随机森林分类器原理详解&Python与R实现
一.简介 作为集成学习中非常著名的方法,随机森林被誉为“代表集成学习技术水平的方法”,由于其简单.容易实现.计算开销小,使得它在现实任务中得到广泛使用,因为其来源于决策树和bagging,决策树我在前 ...
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
随机推荐
- 【bzoj2038】小Z的袜子
莫队算法是一种针对询问进行分块的离线算法,如果已知区间 [ l , r ] 内的答案,并且可以在较快的时间内统计出区间 [ l-1, r ],[ l , r+1 ] 的答案,即可使用莫队算法. 莫队复 ...
- Ubuntu下安装tftp
用户可以在主机系统联网的情况下,在终端输入下面命令进行安装: vmuser@Linux-host: ~$ sudo apt-get install tftpd-hpa tftp-hpa 配置 TFTP ...
- make_blobs
一.make_blobs简介 scikit中的make_blobs方法常被用来生成聚类算法的测试数据,直观地说,make_blobs会根据用户指定的特征数量.中心点数量.范围等来生成几类数据,这些数据 ...
- 详细解读Jquery各Ajax函数:$.get(),$.post(),$.ajax(),$.getJSON()【转】【补】
一,$.get(url,[data],[callback]) 说明:url为请求地址,data为请求数据的列表(是可选的,也可以将要传的参数写在url里面),callback为请求成功后的回调函数,该 ...
- KDevelop使用经验
KDevelop中不显示行号: 1.上方菜单栏"编辑器"->查看->Show Line Numbers 2.设置->配置编辑器->Appearance-&g ...
- java元注解 @Retention注解使用
@Retention定义了该Annotation被保留的时间长短: 1.某些Annotation仅出现在源代码中,而被编译器丢弃: 2.另一些却被编译在class文件中,注解保留在class文件中,在 ...
- Vue Admin - 基于 Vue & Bulma 后台管理面板
Vue Admin 是一个基于 Vue 2.0 & Bulma 0.3 的后台管理面板(管理系统),相当于是 Vue 版本的 Bootstrap 管理系统,提供了一组通用的后台界面 UI 和组 ...
- QSS-qt样式表
QSS即Qt StyleSheet(Qt样式表)的简称,是一种用来自定义控件外观的强大机制,QSS可以让我们的程序界面更加漂亮 每条QSS样式都由两部分组成:1. 选择器,该部分指定要美化的控件 2 ...
- Linux之更改Nginx映射默认根目录
更改nginx映射默认根目录: 1.打开默认配置文件:sudo vi /etc/nginx/sites-available/default 2.修改配置:root /var/www/html/xx ...
- “微信小程序商城构建全栈应用”开发小记
注意事项: 1.application\api\extra下的wx.php记得填写小程序的app_id.app_secret: 2.API测试小工具需要APPID: