Auto Encoder用于异常检测
对基于深度神经网络的Auto Encoder用于异常检测的一些思考
from:https://my.oschina.net/u/1778239/blog/1861724
一、前言
现实中,大部分数据都是无标签的,人和动物多数情况下都是通过无监督学习获取概念,故而无监督学习拥有广阔的业务场景。举几个场景:网络流量是正常流量还是攻击流量、视频中的人的行为是否正常、运维中服务器状态是否异常等等。有监督学习的做法是给样本标出label,那么标label的过程肯定是基于某一些规则(图片除外),既然有了规则,何必要机器学习?基于规则写程序就得了,到底是先有鸡,还是先有蛋?如果计算机可以自己在数据中发现规律,就解决了这个争论。那么基于深度神经网络的auto encoder,可以解决一部分问题。
二、Auto Encoder介绍
Auto Encoder实际上是一个信息压缩的过程,把高维数据压缩至低维度,先来看一下PCA。(以下图片来自于台大李宏毅教授的ppt)
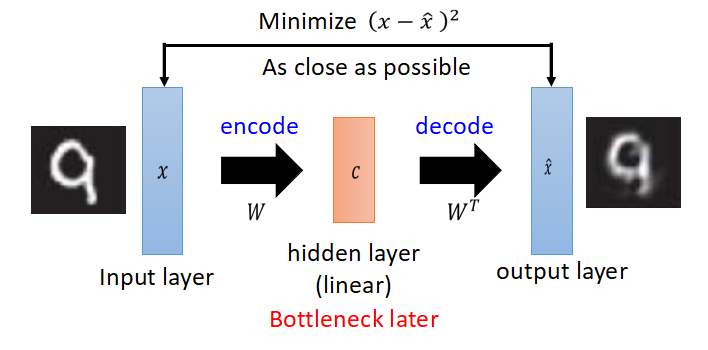
PCA的解释:原向量x乘以矩阵W得到中间编码c,再乘以W的转置,得到x head,得到的x head希望与原x越接近越好,有一点要注意,从x到c的变换过程是线性的。
Deep Auto Encoder和PCA类似,只是网络层数更深,变换是非线性的(因为可以加入一些非线性的激活函数),Deep Auto Encoder变成成了如下的样子:
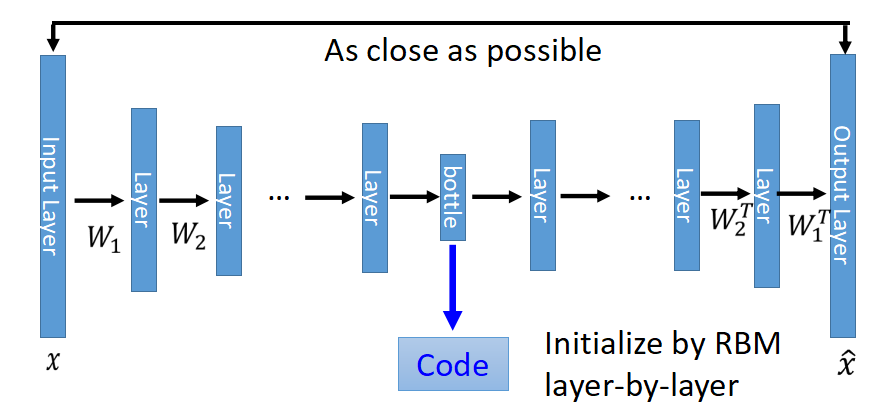
中间有个很窄的hidden layer的输出就是压缩之后的code,当然以bottle layer对称的W不必要互为转置,也不要求一定要用RBM初始化参数,直接train,效果也很好。
下面来看一下,对于MNIST手写数字数据集用像素点、PCA、Deep Auto Encoder三种方式分别做tSNE的展现图
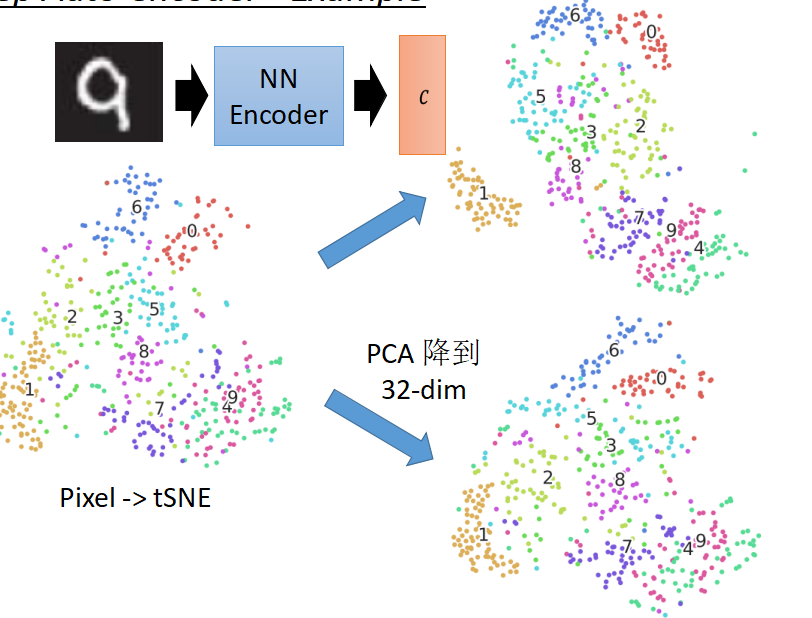
右上角为deep auto encoder之后做tSNE,所有的数字都分的很开,效果比较好。
总结一下,PCA和Deep auto encoder所做的事都类似,就是把原数据压缩到一个低维向量,让后再反解回来,反解回来的值希望与原来的值越接近越好。
三、Auto Encoder用于异常检测
对于自动编码器用于异常检测,可以参考《Variational Autoencoder based Anomaly Detection using Reconstruction Probability》这篇论文 ,论文地址:http://dm.snu.ac.kr/static/docs/TR/SNUDM-TR-2015-03.pdf ,论文标题大概可以这样翻译:基于变分自动编码器重建概率的异常检测。
文中不是直接从变分自动编码器切入,而是先介绍自动编码器,论文言简意赅,我们先来看看论文中对Auto Encoder的训练过程的描述

说明:
1、编码器fφ,decoder gθ
2、损失函数说明:这里用二范数来表示了,二范数实际上是欧几里得距离,也就是均方误差,也就是希望解码出来的值和原值月接近越好。
下面来看,如果将Auto Encoder用于异常检测,还是先看公式

说明:
1、先用正常的数据集训练一个Auto Encoder
2、用训练出的Auto Encoder计算异常数据的重建误差,重建误差大于某个阀值α,则为异常,否则则正常。
文中有这样一段描述:
Autoencoder based anomaly detection
is a deviation based anomaly detection method using semi-supervised
learning. It uses the reconstruction error as the anomaly score. Data
points with high reconstruction are considered to be anomalies.Only
data with normal instances are used to train the autoencoder
这段描述指出了两点:
1、半监督,用正常的数据训练一个Auto Encoder
2、重建误差高的数据为异常数据
普通Deep Auto Encoder有个缺陷,通俗的话来讲就是模型看过的类似的数据它知道,模型没看过的数据,几乎不可能能知道,那变分编码器,就可能解决了一部分问题,通过用分布相似来解释这个问题,请看下面的公式:

整个训练的过程用通俗的话说明一下,首先从标准正态分布中随机L个数据和原x经过hφ函数后得到隐含变量z,注意这里是为每一个样本x都随机L个数据来生成z,loss函数告诉我们两件事情,
第一件,希望z的分布和给定了x的条件下z的分布越接近越好,第二件,希望给定了z的条件下反解回来的x和原分布越接近越好。本质上而言,VAE是给原x加上了随机噪声,同时希望可以反解回原来的值,
中间隐含变量就非常神奇了,可以是高斯分布,也可以是伯努利分布,用概率分布来编码,在自动生成中有妙用。
那么VAE是如何用于异常检测的呢?请继续往下看。

上面的训练过程,可以这样解释,给定x的条件下获取z的分布的平均值和方差,就得到了一个基于x的分布,从该分布中得到L个隐含变量z,通过z反解回x,得到重建概率,
重建概率小于某个阀值为异常,否则则为正常。
四、一些思考
论文中只给出了可以这样做以及这样做的效果,但是论文中没有解释为什么这样做。
其实这个问题比较好类比,训练数据都是正常的,就好比一个人生活的圈子里只有猫,突然来了一条狗,他就肯定不认识了,只知道和猫不同,那么通过数学中的线性回归来类推一下,根据一批正常点拟合了一条直线,有一个游离于这个群体的点,自然离这条直线很远。同样的可以用数据边界来解释,神经网络见过了大量的正常数据,便学习到了数据的边界,游离于边界外的数据,自然也可以摘出来。
但是同样有一个问题,既然原始样本集里已经有正常数据和异常数据了,通过有监督训练一个分类模型就够了。但是真实的场景里,我们是不知道怎么标注数据的,如果说可以标注,肯定是基于人工指定的规则,既然有了规则,就基于规则写if
else(这里是针对数据维度比较小的场景)了,何必要机器来学习,但是规则制定的是否正确还两说,比方说金融领域常见的风险评估,某个用户是否可以放贷给他,已知该用户的各种信息,例如:年龄、性别、职业、收入、信用卡账单等等,这里只是举一个小例子。
以上的疑问,总结起来就两点
1、如何标注数据,到底是先有鸡还是先有蛋
2、基于定死的规则标注的数据是否正确可用
那么,能不能完全无监督的让机器学习出识别这些异常数据的规则,我觉得通过Auto
Encoder是可以做到的,首先,对于异常识别的场景,正常的样本数肯定占大多数,异常的只是少数,把整个样本集完全扔给Deep Auto
Encoder,让他去学习,同样可以找出异常数据。
我写了一个小例子来验证我的观点。
框架:DL4J
我们有经典的数据集,根据天气判断是否打球,这里是从weka的data中复制的,
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no利用DL4J构建一个多层全连接神经网络,代码如下
public class OneHotEncoder {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("sunny", 0);
map.put("overcast", 1);
map.put("rainy", 2);
map.put("hot", 3);
map.put("mild", 4);
map.put("cool", 5);
map.put("high", 6);
map.put("normal", 7);
map.put("TRUE", 8);
map.put("FALSE", 9);
map.put("yes", 0);
map.put("no", 1);
String data = new StringBuilder().append("sunny,hot,high,FALSE,no").append("\n")
.append("sunny,hot,high,TRUE,no").append("\n").append("overcast,hot,high,FALSE,yes").append("\n")
.append("rainy,mild,high,FALSE,yes").append("\n").append("rainy,cool,normal,FALSE,yes").append("\n")
.append("rainy,cool,normal,TRUE,no").append("\n").append("overcast,cool,normal,TRUE,yes").append("\n")
.append("sunny,mild,high,FALSE,no").append("\n").append("sunny,cool,normal,FALSE,yes").append("\n")
.append("rainy,mild,normal,FALSE,yes").append("\n").append("sunny,mild,normal,TRUE,yes").append("\n")
.append("overcast,mild,high,TRUE,yes").append("\n").append("overcast,hot,normal,FALSE,yes").append("\n")
.append("rainy,mild,high,TRUE,no").toString();
INDArray feature = Nd4j.zeros(new int[] { 9, 10 });
INDArray featureTest = Nd4j.zeros(new int[] { 5, 10 });
INDArray label = Nd4j.zeros(14, 2);
String[] rows = data.split("\n");
int index=0;
int indexTest=0;
for (int i = 0; i < rows.length; i++) {
String[] cols = rows[i].split(",");
if(cols[cols.length-1].equals("yes")){
for (int j = 0; j < cols.length - 1; j++) {
feature.putScalar(index, map.get(cols[j]), 1.0);
}
index++;
}else{
for (int j = 0; j < cols.length - 1; j++) {
featureTest.putScalar(indexTest, map.get(cols[j]), 1.0);
}
indexTest++;
}
label.putScalar(i, map.get(cols[cols.length - 1]), 1.0);
}
DataSet dataSet = new DataSet( Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature), Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature));
DataSet dataSetTest = new DataSet(featureTest, featureTest);
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().seed(123).activation(Activation.TANH)
.weightInit(WeightInit.XAVIER).updater(new Sgd(0.1)).l2(1e-4).list()
.layer(0, new DenseLayer.Builder().nIn(10).nOut(20).build())
.layer(1, new DenseLayer.Builder().nIn(20).nOut(2).build())
.layer(2, new DenseLayer.Builder().nIn(2).nOut(20).build())
.layer(3, new OutputLayer.Builder(LossFunctions.LossFunction.MSE).activation(Activation.IDENTITY)
.nIn(20).nOut(10).build())
.backprop(true).pretrain(false).build();
// run the model
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
model.setListeners(new ScoreIterationListener(1));
LayerWorkspaceMgr mgr = LayerWorkspaceMgr.noWorkspaces();
for (int i = 0; i < 10000; i++) {
model.fit(dataSet);
System.out.println(model.score(dataSetTest));
}
}
}
上面有一段特殊代码如下,这里是把正常样本的数量加大,造成正负样本的不均衡
DataSet dataSet = new DataSet( Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature), Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature));
训练之后的结果如下:
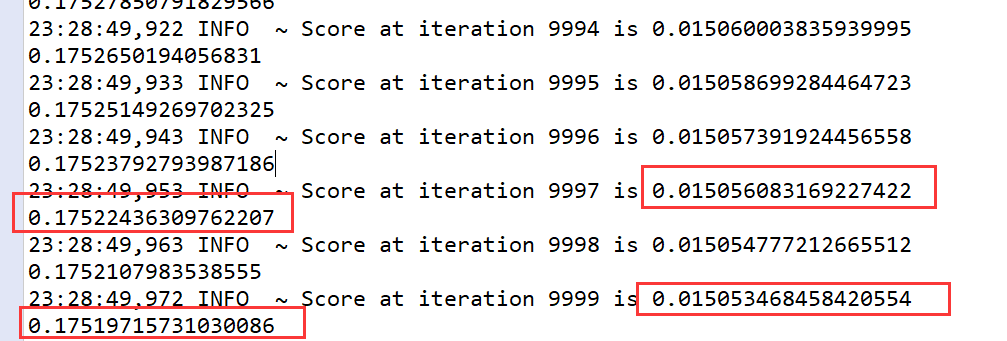
对于异常样本,Loss和整体的Loss有一个数量级的偏差,完全可以作为异常的检测,这里没有刻意的用正样本来训练,而是用正负样本一起训练,完全无监督,就达到了异常检测的效果,当然这适用于正负样本非常不均衡的场景。
为什么可以这样做,我想了一个不用数学公式推导的解释,将写在下次博客中。
最后,DL4J是一个非常优秀的Deeplearning框架,对于Java系的小伙伴想了解Deeplearning的,可以看看DL4J的例子。
Auto Encoder用于异常检测的更多相关文章
- 【R笔记】使用R语言进行异常检测
本文转载自cador<使用R语言进行异常检测> 本文结合R语言,展示了异常检测的案例,主要内容如下: (1)单变量的异常检测 (2)使用LOF(local outlier factor,局 ...
- 斯坦福机器学习视频笔记 Week9 异常检测和高斯混合模型 Anomaly Detection
异常检测,广泛用于欺诈检测(例如“此信用卡被盗?”). 给定大量的数据点,我们有时可能想要找出哪些与平均值有显着差异. 例如,在制造中,我们可能想要检测缺陷或异常. 我们展示了如何使用高斯分布来建模数 ...
- 基于变分自编码器(VAE)利用重建概率的异常检测
本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立 ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-1-论文学习
论文http://202.119.32.195/cache/10/03/cs.nju.edu.cn/da2d9bef3c4fd7d2d8c33947231d9708/tkdd11.pdf 1. INT ...
- 网络KPI异常检测之时序分解算法
时间序列数据伴随着我们的生活和工作.从牙牙学语时的“1, 2, 3, 4, 5, ……”到房价的走势变化,从金融领域的刷卡记录到运维领域的核心网性能指标.时间序列中的规律能加深我们对事物和场景的认识, ...
- 使用VAE、CNN encoder+孤立森林检测ssl加密异常流的初探——真是一个忧伤的故事!!!
ssl payload取1024字节,然后使用VAE检测异常的ssl流. 代码如下: from sklearn.model_selection import train_test_split from ...
- 使用GAN 进行异常检测——anoGAN,TODO,待用于安全分析实验
先说实验成功的代码: git clone https://github.com/tkwoo/anogan-keras.git mkdir weights python main.py --mode t ...
- 思科安全:加密流量威胁检测、加密流量威胁和恶意软件检测、识别无线干扰或威胁、Talos 情报源可加强对已知和新型威胁的防御、分布式安全异常检测
思科DNA竞品比较工具 您的网络能够驱动数字化转型吗? 根据IDC调查,45%的受调研公司计划在未来两年内做好网络数字化的准备.查看数字化网络带来的结果和商业价值. 下载报告 思科 HPE 华为 Ar ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
随机推荐
- 【BZOJ】3572: [Hnoi2014]世界树
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3572 算是细节题了吧.. 构出虚树,考虑z正反DP两次求出虚树中每个点最近的议事处是哪一个 ...
- C#:MVC打印PDF文件
在百度上找了许多PDF文件打印,但是符合我需求的打印方式还没看到,所以根据看了https://www.cnblogs.com/TiestoRay/p/3380717.html的范例后,研究了一下,做出 ...
- pymysql 数据库编程
1.引入模块 import pymysql 2.用于建立与数据库的连接 调用pymysql模块中的connect()方法 conn = pymysql.connect(host='localhost' ...
- mint19 源码安装python3.7
基于Ubuntu 18.04 自带了3.6,可惜 3.7秒出. 一个原则是: 自带的3.6不要动 防止用apt install python3-XXX时版本不对. 理由: 自带的2.7和3.6都是让 ...
- angular在组件中选择dom元素
想选择 在组件中选择自己template里的dom元素,要使用ElementRef. import { Component, EventEmitter, HostListener, OnIni ...
- 第 3 章 镜像 - 019 - 使用公共 Registry
保存和分发镜像的最直接方法就是使用 Docker Hub.https://hub.docker.com/ Docker Hub 是 Docker 公司维护的公共 Registry.用户可以将自己的镜像 ...
- Redis消息之发布与订阅
"发布/订阅"可以实现进程间的消息传递 发布的消息不会持久化,只能收到订阅后的消息,执行subscribe命令后客户端会进入"订阅"状态,处于此状态下的客户端不 ...
- win10 java环境变量
https://jingyan.baidu.com/article/fd8044fa2c22f15031137a2a.html
- java --> Long和long/Integer和int
java中非一切是对象,因为还有基本数据类型. 基本数据类型有对应的基本数据类型打包器,它们的基本数据类型打包器是对象. j2se 5.0引入装箱和拆箱,它们是基本数据类型和基本数据类型打包器的关系 ...
- linux常用命令及系统常见符号
常用命令 1.start x 进入界面 2.shutdown -h now 立刻关机 shutdown -r now 立刻重新启动 reboot 立刻重新启动 3.su root 切换成超级管理员 4 ...