大数据自学3-Windows客户端DbVisualizer/SQuirreL配置连接hive
前面已经学习了将数据从Sql Server导入到Hive DB,并在Hue的Web界面可以查询,接下来是配置客户端工具直接连Hive数据库,常用的有DbVisualizer、SQuirreL SQL Client、DataGrip,只试用了前面两种,花了1天多时间最终实现了用这两款工具连Hive,还是挺有成就感的。
先把环境说明下,有些问题跟环境版本是非常依赖的。
Hadoop/Hive:使用的是CDH 5.15版
DbVisualizer:v 9.58
SQuirreL SQL Client:v 3.7
最先看到是这位大神的文章,”Hive学习之路 (五)DbVisualizer配置连接hive“,配置完后确无法连接,提示Required field 'client_protocol' is unset!,

查了一下,出现这个是因为jdbc的版本与服务器端Hive的jdbc版本不一致造成的,服务器端用的是CDH 5.15,我找到原始的CDH安装包,在cm-5.15.1\share\cmf\common_jars\路径下找到对应版本的文件,主要的几个文件如下:
hadoop-common-2.6.0-cdh5.14.0
hive-common-1.1.0-cdh5.14.0
hive-exec-1.1.0-cdh5.14.0
hive-metastore-1.1.0-cdh5.14.0
hive-jdbc-1.1.0-cdh5.14.0
hive-service-1.1.0-cdh5.14.0
hive-shims-1.1.0-cdh5.14.0
hive-shims-common-1.1.0-cdh5.14.0
这些文件都不能缺少,否则会报ClassNotFoundException等错误
将这些jar替换之前的版本文件后再次连接时,又报错了,提示Illegal Hadoop Version:unknown (expected A. B. * format)

这个要参照这个链接 https://github.com/timveil/hive-jdbc-uber-jar 来解决,原生的取Hadoop版本的方法VersionInfo有某些情况下会取不到,因此这位大神将这个方法改写了,真是牛人啊,真好奇为什么不直接将这段代码提交到开源库呢。
回归正题,按其上面的方法生成了一个hive-jdbc-uber-2.6.5.0-292文件,将此文件复制到jdbc 的路径下,在Driver Manager里重新引用这个jar,发现还是提示之前的错误“Required field 'client_protocol' is unset!”,这个错误已经很明确就是jdbc版本的问题,看了下从github下载下来的工程,发现了pom.xml中有以下段。尝试将hive有关的全部注释,再次打包生成hive-jdbc-uber-2.6.5.0-292文件,这次终于成功了。

DBVisualier中的设定画面
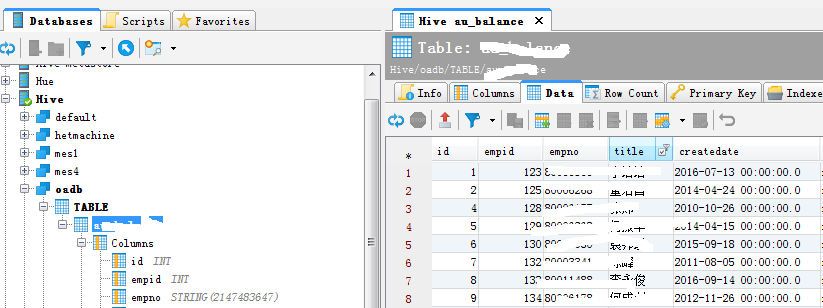
连接成功后查询某表的数据
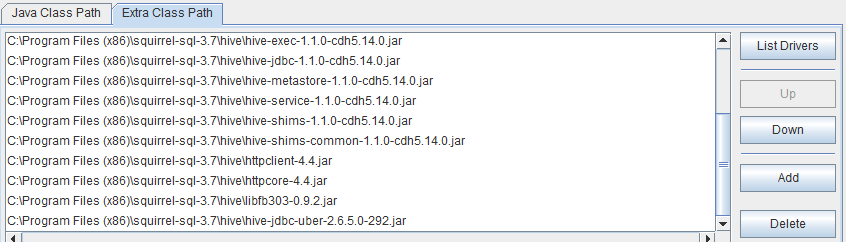
用SQuirreL SQL Client的基本步骤可以参照https://www.cnblogs.com/tgzhu/p/5760698.html,同样的现象,如果hadoop/hive的jar版本不一致或遗漏,也会报上面一样的错误,因此也是按上面的方法同样处理,不同的地方是,生成hive-jdbc-uber-2.6.5.0-292文件时,无需将hive的相关引用注释,我猜当有多个jdbc hive版本时,SQuirreL SQL Client里特殊的机制能找到正确的jdbc版本,但DbVisualizer不能。
另外SQuirreL 配置时要记得步骤,当报Illegal Hadoop Version时,在jdbc Driver配置里要引入hive-jdbc-uber-2.6.5.0-292,同时将hadoop-common-2.6.0-cdh5.14.0的引用去除,保存后可以就可以了。
如果Hive配置了Kerberos安全机制,使用这两个客户端连接起来会麻烦很多,参照https://community.hortonworks.com/content/kbentry/73458/connecting-dbvisualizer-and-datagrip-to-hive-with.html。
大数据自学3-Windows客户端DbVisualizer/SQuirreL配置连接hive的更多相关文章
- 大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建
大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建 大数据应用之Windows平台Hbase客户端Eclipse环境搭建-Java版 作者:张子良 版权所有,转载请注明出处 引子 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 通过数据库客户端界面工具DBeaver连接Hive
前言 本文讲解如何通过数据库客户端界面工具DBeaver连接hive,并解决驱动下载不下来的问题. 1.为什么使用客户端界面工具 为什么使用客户端界面工具而不用命令行使用hive 通过界面工具查看分析 ...
- 大数据自学4-Hue集成环境中各模组说明
前面已经学习了如何将数据从关系型数据库导入到Hive/HDFS,并且在Windows客户端查询导入的数据,接下来继续学习CDH,知识点: 1.Hue环境中DB Query如何使用,DB Query这个 ...
- 大数据自学2-Hue集成环境中使用Sqoop组件从Sql Server导数据到Hive/HDFS
安装完CDH后,发现里面的东东实在是太多了,对于一个初学大数据的来说就犹如刘姥姥进了大观园,很新奇,这些东东每个单拿出来都够喝一壶的. 接来来就是一步一步地学习了,先大致学习了每个模组大致做什么用的, ...
- centos6.5环境搭建openvp服务器及windows客户端搭建及配置详解
1.环境搭建 说明: vpn client 192.168.8.16/24 openvpn server: eth0: 192.168.8.41 eth1: 172.16.1.10 app serve ...
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- 在 windows 下搭建 IDEA + Spark 连接 Hive 的环境
为了开发测试方便,想直接在 IDEA 里运行 Spark 程序,可以连接 Hive,需不是打好包后,放到集群上去运行.主要配置工作如下: 1. 把集群环境中的 hive-core.xml, hdfs- ...
随机推荐
- 快学Scala 2
控制结构和函数 1.在Scala中,几乎所有构造出来的语法结构都有值.这个特性是为了使得程序更加精简,也更易读. (1)if表达式有值 (2)块也有值——是它最后一个表达式的值 (3)Scala的fo ...
- BBS项目
一.需求分析 1.首页(显示文章) 文章详情 点赞,点踩 文章评论(子评论,评论的展示) 登录功能(图片验证码) 注册功能(基于form验证,ajax) 个人站点(不同人不同样式,文章过滤) 后台管理 ...
- [django]django权限简单实验
djagno https://www.jianshu.com/p/01126437e8a4 开始我一直没明白内置的view_car 怎么实现view 只读库的. 后来发现这个api需要在views.p ...
- IOT-SpringBoot-angular启动
1 D:\workspace_iot\iot-hub\src\main\angular cmd 启动 npm start 2 eclipse中启动springboot 3 local ...
- Elasticsearch6.13 升级6.24 单节点停机升级
Elasticsearch6.x 升级6.y 是支持滚动升级的,目前我们测试环境只有一个节点只能停机升级了 准备工作 禁用分片分配 curl -X PUT "localhost:9200/_ ...
- Let Encrypt延期(转自虞大胆的叽叽喳喳)
前几天发现我的 letsencrypt 通配符证书快过期了,想为这两张证书续期(renew). 首先运行命令查看我的所有证书: $ certbot-auto certificates 其中证书名 si ...
- js图的数据结构处理---迪杰斯特拉算法
/*//1.确定数据结构, mapf[i][j] 为点i到点j的距离 [ Infinity 2 5 Infinity Infinity Infinity Infinity 2 6 Infinity I ...
- nginx 日志详解及自定义日志配置
nginx的log日志分为access log 和 error log 其中access log 记录了哪些用户,哪些页面以及用户浏览器.ip和其他的访问信息 error log 则是记录服务器错误日 ...
- 漏洞复现:Struts2 远程代码执行漏洞(S2-033)
docker pull medicean/vulapps:s_struts2_s2-033 docker run -d -p 80:8080 medicean/vulapps:s_struts2_s2 ...
- 用C#创建一个窗体,在构造函数里面写代码和在from_load事件里面写代码有什么不同?
没太大区别.一区别就是代码加载时间先后的问题.构造函数先加载,load事件中后加载.