爬取w3c课程—Urllib库使用
爬虫原理
浏览器获取网页内容的步骤:浏览器提交请求、下载网页代码、解析成页面,爬虫要做的就是:
- 模拟浏览器发送请求:通过HTTP库向目标站点发起请求Request,请求可以包含额外的header等信息,等待服务器响应
- 获取响应内容:如果服务器正常响应,会得到一个响应Response,响应的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等
- 解析响应内容:获取响应内容后,解析各种数据,如:解析html数据:正则表达式,第三方解析库,解析json数据:json模块,解析二进制数据:进一步处理或以wb的方式写入文件
- 保存数据:保存为文本,数据库,或者保存特定格式的文件
简单例子:利用Urllib库爬取w3c网站教程
1、urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应:例如,对百度的一个w3c发送一个GET请求,并返回响应:
# coding:utf-8
import urllib.request my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址
page = urllib.request.urlopen(my_url)
html = page.read().decode('utf-8')
print(html)
把发送一个GET请求到指定的页面,返回HTTP的响应写成一个函数:
def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html
将返回如下内容,这与在浏览器查看源码看到的是一样的,接下来可以根据返回的内容进行解析:

2、利用正则表达式的分组提取课程名称、课程简介、课程链接,导入python里面的re库
reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配,
到现在代码如下:
# coding:utf-8
import urllib.request
import re my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址 def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配 print("一共有课程数:" + str(len(tutorial_list)))#打印出有多少课程 for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
运行,打印结果:

3、保存数据,保存数据到excel里面,用到excel第三方库xlwt,也可以只用openpyxl,库的使用可以参照官网:http://www.python-excel.org/
本次需要新建一个Excel,把课程名称、课程简介、课程链接写到Excel里面,课程链接用xlwt.Formula设置超链接,Excel第一行设置为宋体,加粗,写一些课程内容外的东西
import xlwt
excel_path=r'tutorial.xlsx'#excel的路径
book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 创建一个Workbook对象,这就相当于创建了一个Excel文件
sheet = book.add_sheet('课程',cell_overwrite_ok=True)# 添加表
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#创建字体
font.name = '宋体'#指定字体名字
font.bold = True#字体加粗
style.font = font#将该font设定为style的字体
sheet.write(0, 0, '序号',style)#用之前的style格式写第一行,行、列从0开始计算
sheet.write(0, 1, '课程',style)
sheet.write(0, 2, '简介',style)
sheet.write(0, 3, '课程链接',style)
写课程内容到Excel
for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
sheet.write(i+1, 0, i+1)
sheet.write(i+1, 1, tutorial_list[i][1])
sheet.write(i+1, 2, tutorial_list[i][2])
sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把链接写进去,并用xlwt.Formula设置超链接 book.save(excel_path)#保存到excel
Excel内容:
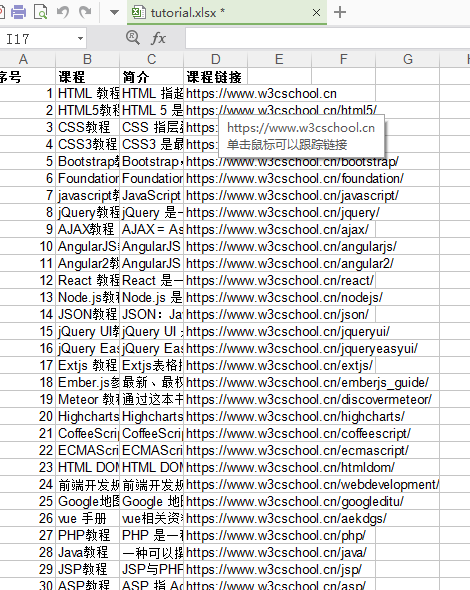
全部代码如下:
# coding:utf-8
import urllib.request
import re
import xlwt
excel_path=r'tutorial.xlsx'#excel的路径
my_url='https://www.w3cschool.cn/tutorial'#要获取课程的网址
book = xlwt.Workbook(encoding='utf-8', style_compression=0)# 创建一个Workbook对象,这就相当于创建了一个Excel文件
sheet = book.add_sheet('课程',cell_overwrite_ok=True)# 添加表
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#创建字体
font.name = '宋体'#指定字体名字
font.bold = True#字体加粗
style.font = font#将该font设定为style的字体
sheet.write(0, 0, '序号',style)#用之前的style格式写第一行,行、列从0开始计算
sheet.write(0, 1, '课程',style)
sheet.write(0, 2, '简介',style)
sheet.write(0, 3, '课程链接',style) def get_html(url):#访问url
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html reg = r'<a href="([\s\S]*?)" title=[\s\S]*?<h4>(.+)</h4>\n<p>([\s\S]*?)</p>'#运用正则表达式,分组提取数据
reg_tutorial = re.compile(reg)#编译一下正则表达式,运行更快
tutorial_list = reg_tutorial.findall(get_html(my_url))#进行匹配 print("一共有课程数:" + str(len(tutorial_list)))#打印出有多少课程 for i in range(len(tutorial_list)):#把课程名称、课程简介、课程链接写到excel,python里面excel从0开始计算
print (tutorial_list[i])
sheet.write(i+1, 0, i+1)
sheet.write(i+1, 1, tutorial_list[i][1])
sheet.write(i+1, 2, tutorial_list[i][2])
sheet.write(i+1, 3, xlwt.Formula("HYPERLINK(" +'"'+"https:" + tutorial_list[i][0]+'"'+')'))#把链接写进去,并用xlwt.Formula设置超链接 book.save(excel_path)#保存到excel
爬取w3c课程—Urllib库使用的更多相关文章
- python爬取course课程的信息
目录 1.大模块页面 2.每个大模块中小模块的简单信息 3.每个小课程的详细信息 4.爬取所有评论 @ 这几天爬取了course动态网页的课程信息,有关数据分析,机器学习,还有概率论和数理统计课程 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬虫从入门到放弃(三)之 Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码..... 目录结构 items.py import scrapy class DoubanCrawlerItem(scrapy.Item): # 电影名称 movieName = ...
- 爬虫常用的 urllib 库知识点
urllib 库 urllib 库是 Python 中一个最基本的网络请求库.它可以模仿浏览器的行为向指定的服务器发送请求,同时可以保存服务器返回的数据. urlopen() 在 Python3 的 ...
- python之爬虫(三) Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- Python爬虫--Urllib库
Urllib库 Urllib是python内置的HTTP请求库,包括以下模块:urllib.request (请求模块).urllib.error( 异常处理模块).urllib.parse (url ...
- urllib库的基本使用
urllib库的使用 官方文档地址:https://docs.python.org/3/library/urllib.html 什么是urllib Urllib是python内置的HTTP请求库包括以 ...
- 爬虫之Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
随机推荐
- python - socketserver 模块应用
server端: import socketserver import subprocess import json import struct class MyTCPHandler(socketse ...
- Java获取资源路径——(八)
获取文件资源有两种方式: 第一种是: 获取Java项目根目录开始制定文件夹下指定文件,不用类加载器(目录开始要加/) // 获取工程路径 System.out.println(System.getP ...
- Linux内存管理6---伙伴算法与slab
1.前言 本文所述关于内存管理的系列文章主要是对陈莉君老师所讲述的内存管理知识讲座的整理. 本讲座主要分三个主题展开对内存管理进行讲解:内存管理的硬件基础.虚拟地址空间的管理.物理地址空间的管理. 本 ...
- jvm系列三、java GC算法 垃圾收集器
原文链接:http://www.cnblogs.com/ityouknow/p/5614961.html 概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 ...
- windows系统实现mysql数据库数据库主从复制
环境: master mysql服务器 192.168.8.201 slave mysql服务器 192.168.8.89 目标: 实现主从复制 1.将MySQL5.5安装文件分别拷贝到两台机器的c盘 ...
- saltStack的event接口通过mysql数据库接收SaltStack批量管理日志
event是一个本地的ZeroMQ PUB Interface,event是一个开放的系统,用于发送信息通知salt或其他的操作系统.每个event都有一个标签.事件标签允许快速制定过滤事件.除了标签 ...
- Web Services基础学习(W3C)
1.Web services 使用 XML 来编解码数据,并使用 SOAP 来传输数据 2.基础的 Web Services 平台是 XML + HTTP. Web services 平台的元素: S ...
- 转载:编译安装Nginx(1.4)《深入理解Nginx》(陶辉)
原文:https://book.2cto.com/201304/19617.html 安装Nginx最简单的方式是,进入nginx-1.0.14目录后执行以下3行命令:./configuremakem ...
- Linux VMware tools安装步骤
Linux VMware tools安装步骤: 1.安装环境介绍 #虚拟机版本:VMware-workstation-full-10 #linux分发版本:CentOS-6.4-i386-LiveCD ...
- linux之nginx
一.知识点回顾 临时:关闭当前正在运行的 /etc/init.d/iptables stop 永久:关闭开机自启动 chkonfig iptables off ll /var/log/secure # ...