kafka产生的数据通过Flume存到HDFS中
试验目标:
把kafka的生产者发出的数据流经由Flume放到HDFS来存储。
试验环境:
java:1.8
kafka:2.11
flume:1.6
hadoop:2.8.5
试验流程:
1.进入zookeeper的bin目录,启动zookeeper
$ zkServer.sh start
2.配置Flume的conf文件
在flume下conf文件夹创建 flume.cof文件
agent.sources = kafkaSource
agent.channels = memoryChannel
agent.sinks = hdfsSink agent.sources.kafkaSource.channels = memoryChannel
agent.sources.kafkaSource.type=org.apache.flume.source.kafka.KafkaSource
agent.sources.kafkaSource.zookeeperConnect=127.0.0.1:
agent.sources.kafkaSource.topic=flume-data agent.sources.kafkaSource.kafka.consumer.timeout.ms=
agent.channels.memoryChannel.type=memory
agent.channels.memoryChannel.capacity=
agent.channels.memoryChannel.transactionCapacity= agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel = memoryChannel
agent.sinks.hdfsSink.hdfs.path=hdfs://master:9000/usr/feiy/flume-data
agent.sinks.hdfsSink.hdfs.writeFormat=Text
agent.sinks.hdfsSink.hdfs.fileType=DataStream
3.启动hadoop分布式集群
$ start-all.sh
4.启动kafka服务,并创建一个topic,让flume来消费。
启动kafka:
$ bin/kafka-server-start.sh -daemon ./config/server.properties &
创建topic,主题名:flume-data
$ bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic flume-data
4.启动flume,等待kafka传输消息
进入flume安装目录下的conf目录,执行命令
$ bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent -Dflume.root.logger=INFO,console

5.向主kafka里面输入数据
$ bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic flume-data

此时,你输入的数据就会通过flume发送到HDFS里面
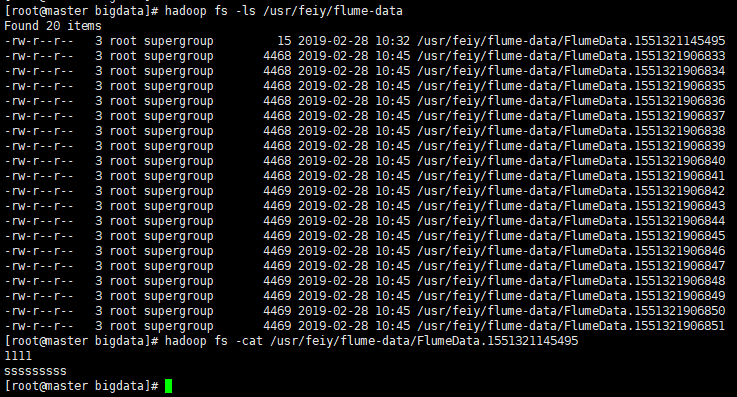
6.查看HDFS里面的文件
$ hadoop fs -ls /usr/feiy/flume-data
$ hadoop fs -cat /usr/feiy/flume-data/FlumeData.1551321145495
代码试验:
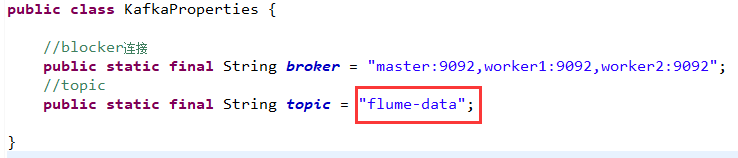
如果是用kafka代码,获取接口的数据,然后向flume里传送,只需要将kafka中的代码中的topic名字设置成服务器上的主题名即可:flume-data
参考:https://blog.csdn.net/feinifi/article/details/73929015
kafka产生的数据通过Flume存到HDFS中的更多相关文章
- spark读取 kafka nginx网站日志消息 并写入HDFS中(转)
原文链接:spark读取 kafka nginx网站日志消息 并写入HDFS中 spark 版本为1.0 kafka 版本为0.8 首先来看看kafka的架构图 详细了解请参考官方 我这边有三台机器用 ...
- ffmpeg从AVFrame取出yuv数据到保存到char*中
ffmpeg从AVFrame取出yuv数据到保存到char*中 很多人一直不知道怎么利用ffmpeg从AVFrame取出yuv数据到保存到char*中,下面代码将yuv420p和yuv422p的数 ...
- 调用存储过程取到数据通过NPOI存到Excel中
//调用 public ActionResult GenerateExcel() { DataTable headerTable = new DataTable(); ...
- Java输入一行数据并转存到数组中
直接看下面的代码吧!主要是split和foreach的使用 import java.io.*; import java.util.*; public class Main{ public static ...
- python 数据如何保存到excel中--xlwt
第一步:下载xlwt 首先要下载xlwt,(前提是你已经安装好了Python) 下载地址: https://pypi.python.org/pypi/xlwt/ 下载第二个 第二步:安装xl ...
- 带你看懂大数据采集引擎之Flume&采集目录中的日志
一.Flume的介绍: Flume由Cloudera公司开发,是一种提供高可用.高可靠.分布式海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据:同时,flum ...
- flume 增量上传日志文件到HDFS中
1.采集日志文件时一个很常见的现象 采集需求:比如业务系统使用log4j生成日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs中. 1.1.根据需求,首先定义一下3大要素: 采集源 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- HDFS中的读写数据流
1.文件的读取 在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解. 图 1 客户端从HDFS中读取数据 1)客户 ...
随机推荐
- 基于C#利用ffmpeg提取视频帧
利用ffmepg提取视频帧实际上是利用C#调用ffmepg命令行进行处理对应的视频,然后输出出视频帧 GetPicFromVideo("); static public string Get ...
- vmware NAT 网络出现问题的解决方法
nat 网络的配制: 用nat网络相对来说,以后网段出现改变,都不会有大的影响,方便以后做实验. 用dhclient 来获取IP dhclent -r 是用来关闭获取IP的. 自动获取IP,也可以改成 ...
- <<操作,&0xff以及|的巧妙运用(以POJ3523---The Morning after Halloween(UVa 1601)为例)
<<表示左移,如a<<1表示将a的二进制左移一位,加一个0,&0xff表示取最后8个字节,如a&0xff表示取a表示的二进制中最后8个数字组成一个新的二进制数, ...
- Python学习之---Python中的内置函数(方法)(更新中。。。)
add(item) #将item添加到s中,如果item已经在s中,则无任何效果 break #退出循环,不会再运行循环中余下的代码 bool() #将参数转换为布尔型 by ...
- 【Disruptor】之Ringbuffer
一.Ringbuffer的概念 =>是一个环形数据队列的数据结构 =>嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer. =& ...
- gunicorn工作原理
gunicorn工作原理 Gunicorn“绿色独角兽”是一个被广泛使用的高性能的Python WSGI UNIX HTTP服务器,移植自Ruby的独角兽(Unicorn )项目,使用pre-fork ...
- H3C路由器映射端口到外网
登录路由器web管理端 选择高级设置->虚拟服务器->新增虚拟服务器
- MySQL Replication--修改主键为NULL导致的异常
测试环境:MySQL 5.5.14/MySQL 5.6.36 测试脚本: create table tb001(id int primary key,c1 int); alter table tb00 ...
- linux 控制结构
一.if 注: 格式1.格式2:一个条件一个命令: 格式3:一个条件两个命令: 格式4:两个条件三个命令,注意条件的写法. 例1: #!/bin/sh#ifTest#to show the metho ...
- day 54 JS 之 jquery
jQuery入门 2017-07-10 jQuery快速入门. jQuery介绍 jQuery是一个轻量级的.兼容多浏览器的JavaScript库. jQuery使用户能够更方便地处理HTML Doc ...