Hbase与Oracle比较(列式数据库与行式数据库)
1 主要区别
- Hbase适合大量插入同时又有读的情况
- Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间。
Hbase本质上只有一种操作,就是插入,其更新操作是插入一个带有新的时间戳的行,而删除是插入一个带有插入标记的行。
其主要操作是收集内存中一批数据,然后批量的写入硬盘,所以其写入的速度主要取决于硬盘传输的速度。
Oracle则不同,因为他经常要随机读写,这样硬盘磁头需要不断的寻找数据所在,所以瓶颈在于硬盘寻道时间。
- Hbase很适合寻找按照时间排序top n的场景
- 索引不同造成行为的差异。
- Oracle 既可以做OLTP又可以做OLAP,但在某种极端的情况下(负荷十分之大),就不适合了。
2 Hbase的局限:
- 只能做简单的Key value查询,复杂的sql统计做不到。
- 只能在row key上做快速查询。
3 传统数据库的行式存储
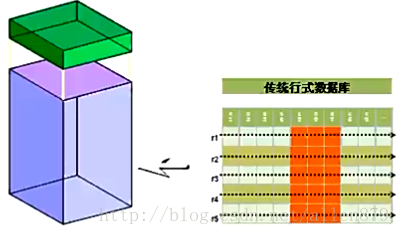
在数据分析的场景里面,我们经常是以某个列作为查询条件,返回的结果经常也只是某些列,不是全部的列。
行式数据库在这种情况下的I/O性能会很差,
以Oracle为例,Oracle会有一个很大的数据文件,
- 在这个数据文件中,划分了很多block,然后在每个block中放入行,
- 行是一行一行放进去,挤在一起,然后把block塞满,当然也会预留一些空间,用于将来update。
这种结构的缺点是:
当我们读某个列的时候,比如我们只需要读红色标记的列的时候,不能只读这部分数据,我必须把整个block读取到内存中,然后再把这些列的数据取出来,
换句话说,我为了读表中某些列的数据,我必须把整个列的行读完,才可以读到这些列。
如果这些列的数据很少,比如1T的数据中只占了100M, 为了读100M数据却要读取1TB的数据到内存中去,则显然是不划算。
3.1 B+索引
Oracle中采用的数据访问技术主要是B数索引:
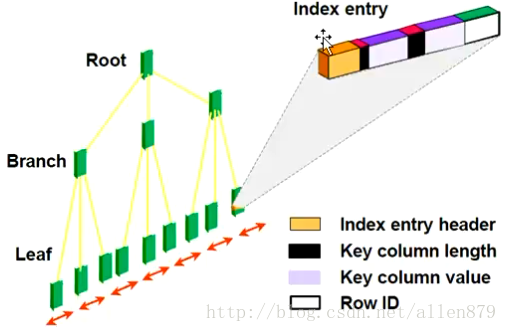
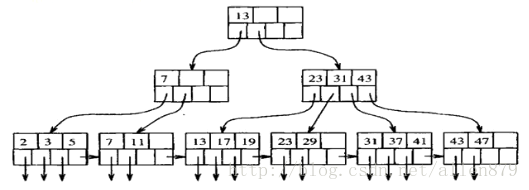
从树的跟节点出发,可以找到叶子节点,其记录了key值对应的那行的位置。
对B树的操作:
B树插入——分裂节点
B数删除——合并节点
4 列式存储
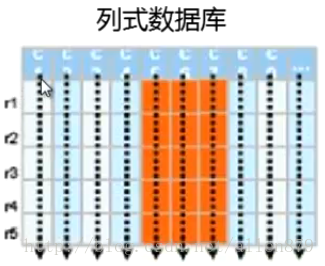
- 同一个列的数据会挤在一起,比如挤在block里,当我需要读某个列的时候,只需要把相关的文件或块读到内存中去,整个列就会被读出来,这样I/O会少很多。
- 同一个列的数据的格式比较类似,这样可以做大幅度的压缩。这样节省了存储空间,也节省了I/O,因为数据被压缩了,这样读的数据量随之也少了。
行式数据库适合OLTP,反倒列式数据库不适合OLTP。
4.1 BigTable的LSM(Log Struct Merge)索引
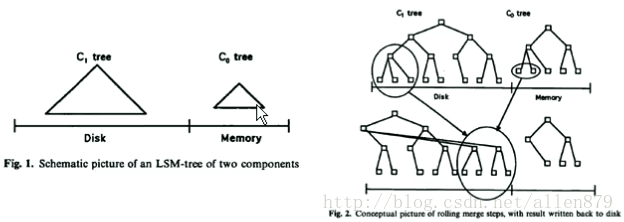
在Hbase中日志即数据,数据就是日志,他们是一体化的。
为什么这么说了,因为Hbase的更新时插入一行,删除也是插入一行,然后打上删除标记,则不就是日志吗?
在Hbase中,有Memory Store,还有Store File,其实每个Memory Store和每个Store File就是对每个列族附加上一个B+树(有点像Oracle的索引组织表,数据和索引是一体化的), 也就是图的下面是列族,上面是B+树,当进行数据的查询时,首先会在内存中memory store的B+树中查找,如果找不到,再到Store File中去找。
如果找的行的数据分散在好几个列族中,那怎么把行的数据找全呢?那就需要找好几个B+树,这样效率就比较低了。所以尽量让每次insert的一行的列族都是稀疏的,只在某一个列族上有值,其他列族没有值,
Hbase与Oracle比较(列式数据库与行式数据库)的更多相关文章
- Oracle中将列查询结果多行逗号拼接成一个大字段
在11G以下版本中oracle有自带的函数wm_concat可以实现,如: select wm_concat(id) from table where col='1' 但是在12C版本中此函数无法使用 ...
- 【HBase】与关系型数据库区别、行式/列式存储
[HBase]与关系型数据库区别 1.本质区别 mysql:关系型数据库,行式存储,ACID,SQL,只能存储结构化数据 事务的原子性(Atomicity):是指一个事务要么全部执行,要么不执行,也就 ...
- Hbase和Oracle的对比
转自:http://www.cnblogs.com/chay1227/archive/2013/03/17/2964020.html 转自:http://blog.csdn.net/allen879/ ...
- Hbase与Oracle的比较
http://blog.csdn.net/lucky_greenegg/article/details/47070565 转自:http://www.cnblogs.com/chay1227/arch ...
- 列式存储 V.S. 行式存储
列式数据库 http://zh.wikipedia.org/wiki/%E5%88%97%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93 列式存储与行式存储 http://my ...
- oracle 12c 列式存储 ( In Memory 理论)
随着Oracle 12c推出了in memory组件,使得Oracle数据库具有了双模式数据存放方式,从而能够实现对混合类型应用的支持:传统的以行形式保存的数据满足OLTP应用:列形式保存的数据满足以 ...
- 基于Oracle的SQL优化(社区万众期待 数据库优化扛鼎巨著)
基于Oracle的SQL优化(社区万众期待数据库优化扛鼎巨著) 崔华 编 ISBN 978-7-121-21758-6 2014年1月出版 定价:128.00元 856页 16开 编辑推荐 本土O ...
- 【Oracle】PL/SQL 显式游标、隐式游标、动态游标
在PL/SQL块中执行SELECT.INSERT.DELETE和UPDATE语句时,Oracle会在内存中为其分配上下文区(Context Area),即缓冲区.游标是指向该区的一个指针,或是命名一个 ...
- Hadoop IO基于文件的数据结构详解【列式和行式数据结构的存储策略】
Charles所有关于hadoop的文章参考自hadoop权威指南第四版预览版 大家可以去safari免费阅读其英文预览版.本人也上传了PDF版本在我的资源中可以免费下载,不需要C币,点击这里下载. ...
随机推荐
- Block 循环引用(上)
iOS的内存管理机制 Objective-C在iOS中不支持GC(垃圾回收)机制,而是采用的引用计数的方式管理内存. 引用计数:在引用计数中,每一个对象负责维护对象所有引用的计数值.当一个新的引用指向 ...
- MCMC算法深入理解
MCMC(Markov Chain Monte Carlo),即马尔科夫链蒙特卡洛方法,是以马尔科夫平稳状态作为理论基础,蒙特卡洛方法作为手段的概率序列生成技术. MCMC理论基础 如果转移矩阵为P的 ...
- locust 的使用
Contents Locust这一款开源性能测试工具.然而,当前在网络上针对Locust的教程极少,不管是中文还是英文,基本都是介绍安装方法和简单的测试案例演示,但对于较复杂测试场景的案例演示却基本没 ...
- Saiku + Kylin 多维分析平台探索
背景 为了应对各种数据需求,通常,我们的做法是这样的: 对于临时性的数据需求:写HQL到Hive里去查一遍,然后将结果转为excel发送给需求人员. 对于周期性的.长期性的数据需求:编写脚本,结合Hi ...
- Linux基础命令---显示树形进程pstree
pstree pstree显示正在运行的进程的树形结构,树以PID为根:如果省略了pid则以init为根.如果指定了用户名,则显示根植于该用户拥有的进程的所有进程树.如果pstree被调用为pstre ...
- Linux服务器---配置nfs
配置nfs NFS服务的主要配置文件为/etc/exports./etc/exports文件内容格式: <输出目录> 客户端(选项:访问权限,用户映射,其他) 1.输出目录 输出目录是指N ...
- javanio1----传统io
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- Django框架---- 自定义分页组件
分页的实现与使用 class Pagination(object): """ 自定义分页 """ def __init__(self,cur ...
- 怎样从外网访问内网Oracle数据库?
本地安装了一个Oracle数据库,只能在局域网内访问到,怎样从外网也能访问到本地的Oracle数据库呢?本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Oracle数据库 默认安装的Or ...
- SRTP参数及数据包处理过程(转)
源: SRTP参数及数据包处理过程