天气数据爬取+pyechart可视化
数据爬取/处理
爬取深圳2021年全年的天气历史数据。
网址链接:https://lishi.tianqi.com/shenzhen/
代码:
import requests
from lxml import etree
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'
}
# title=html.xpath('/html/body/div[7]/div[1]/div[4]/div//text()')
#
# # (国际化功能中常常用到),\u4e00-\u9fa5是用来判断是不是中文的一个条件。
# title_list = [item for item in title if re.findall('[\u4e00-\u9fa5]', item)]
# # print(title_list)
#获取所有2021年12个月的url链接
def get_url_list(s_page, e_page):
url_list = []
for i in range(s_page, e_page):
if i < 10:
url_list.append('https://lishi.tianqi.com/shenzhen/2021{}.html'.format('0' + str(i)))
else:
url_list.append('https://lishi.tianqi.com/shenzhen/2021{}.html'.format(str(i)))
return url_list
#解析获取url数据,并解析
def parse_datas(url):
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
t_list = html.xpath('/html/body/div[7]/div[1]/div[4]/ul/li')
datas=[]
for li in t_list:
data = li.xpath('./div/text()')
datas.append(data)
return datas
#合并每一页url获取的数据
def temp_datas(s_page, e_page):
url_list = get_url_list(s_page, e_page)
c_datas = []
for url in url_list:
c_datas.extend(parse_datas(url))
return c_datas
if __name__ == '__main__':
datas = pd.DataFrame(temp_datas(s_page=1, e_page=13),
columns=['date', 'h_temp', 'l_temp', 'weather', 'w_d'])
print(datas)
数据存储
存储数据成CSV格式,或存入sqlite数据库中。
代码:
from weather_spider import temp_datas #从上面数据爬取的模块文件中导入temp_datas函数
import os
import pandas as pd
from sqlalchemy import create_engine
def save_csv(datas):
'''存储成csv数据格式'''
if not os.path.exists('./weather_datas'):
os.mkdir('./weather_datas')
save_path = './weather_datas/weather_datas_sz.csv'
datas.to_csv(save_path, index=False)
def save_sqlite(datas, datasname):
'''存储到sqlite数据库'''
engine = create_engine('sqlite:///weather_datas/weather_datas.db')
datas.to_sql(datasname, engine, index=False)
if __name__ == '__main__':
datas = pd.DataFrame(temp_datas(s_page=1, e_page=13),
columns=['date', 'h_temp', 'l_temp', 'weather', 'w_d'])
save_sqlite(datas, 'weather_datas_sz')
数据可视化
对2021年深圳的天气数据进行可视化分析。
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
from pyecharts import options as opts
from pyecharts.charts import Bar, Line, Timeline, Page, Pie, Grid
def get_datas():
"""从sqlite数据库读取数据"""
engine = create_engine(r'sqlite:///weather_datas/weather_datas.db')
sql = 'SELECT * FROM weather_datas_sz'
datas = pd.read_sql(sql, engine)
# 从csv文件读取数据
# datas = pd.read_csv('./weather_datas/weather_datas_sz.csv')
#数据处理
datas.date = datas.date.str.split(' ', expand=True)[0]
datas.h_temp = datas.h_temp.str.split('℃', expand=True)[0].astype(np.float)
datas.l_temp = datas.l_temp.str.split('℃', expand=True)[0].astype(np.float)
datas['w_d0'] = datas['w_d'].str.split(' ', expand=True)[0]
datas['w_d1'] = datas['w_d'].str.split(' ', expand=True)[1]
datas['month'] = datas.date.apply(lambda x: x.split('-')[1])
datas['deltaT'] = datas.h_temp - datas.l_temp
datas['averageT'] = (datas.h_temp + datas.l_temp) / 2
return datas
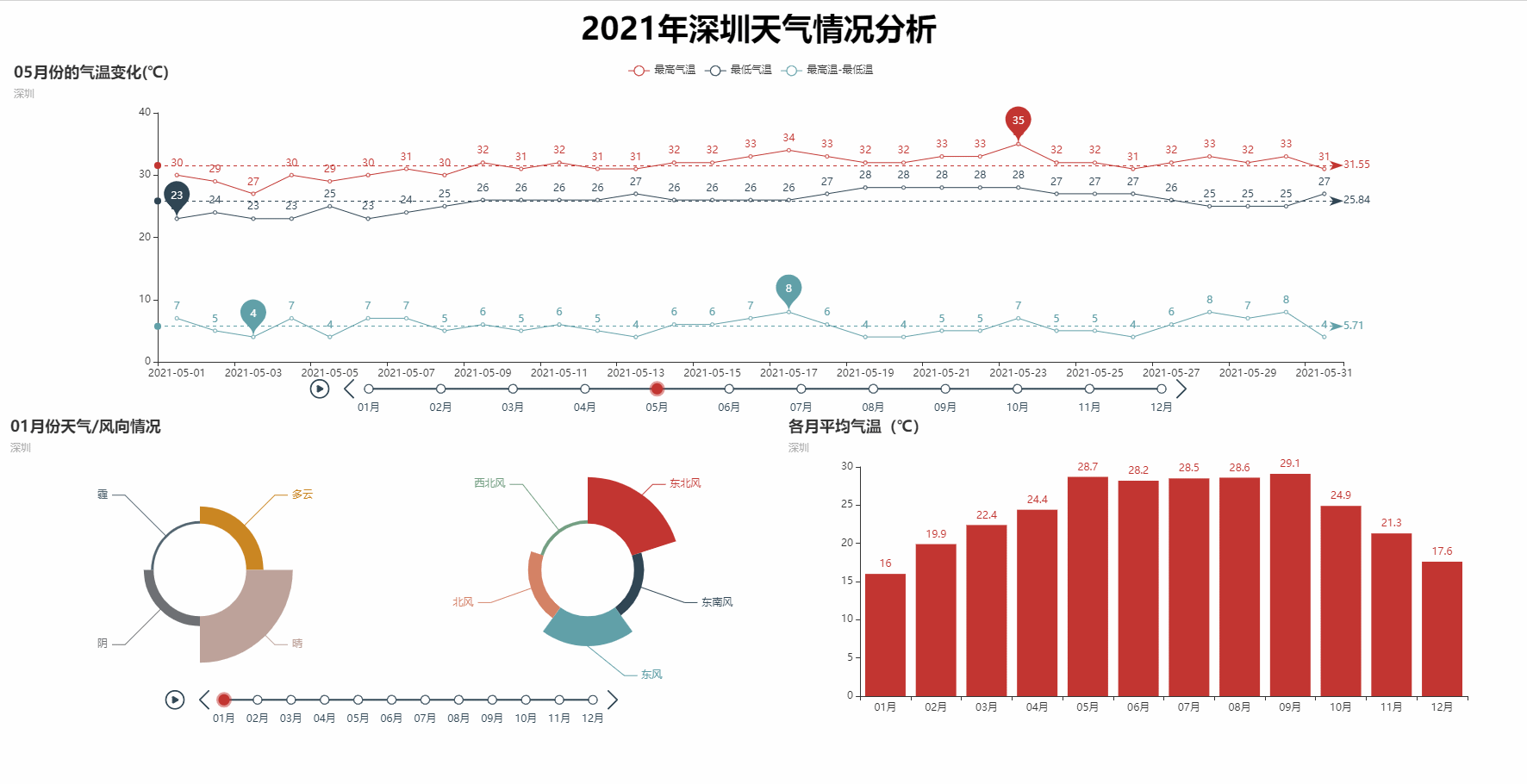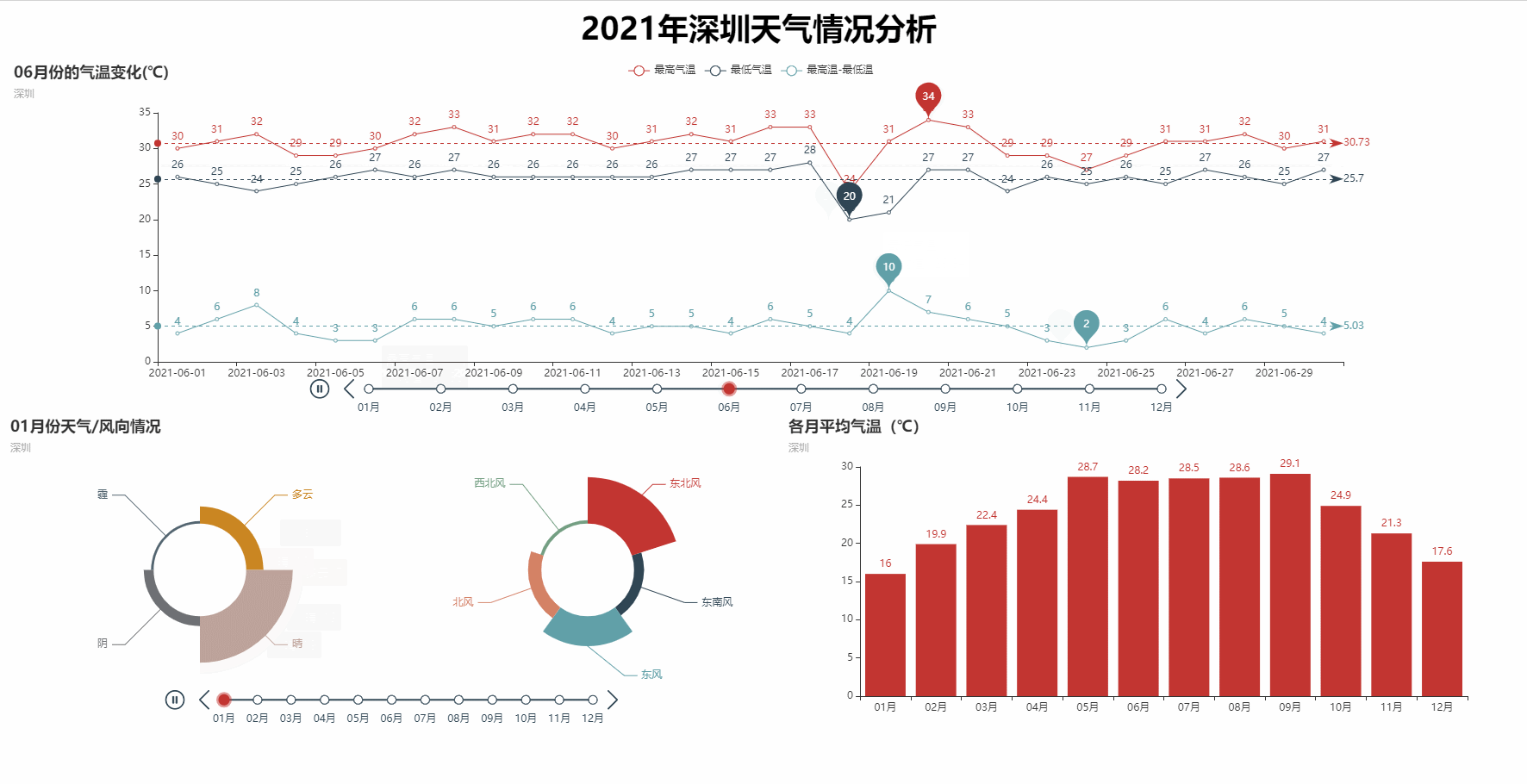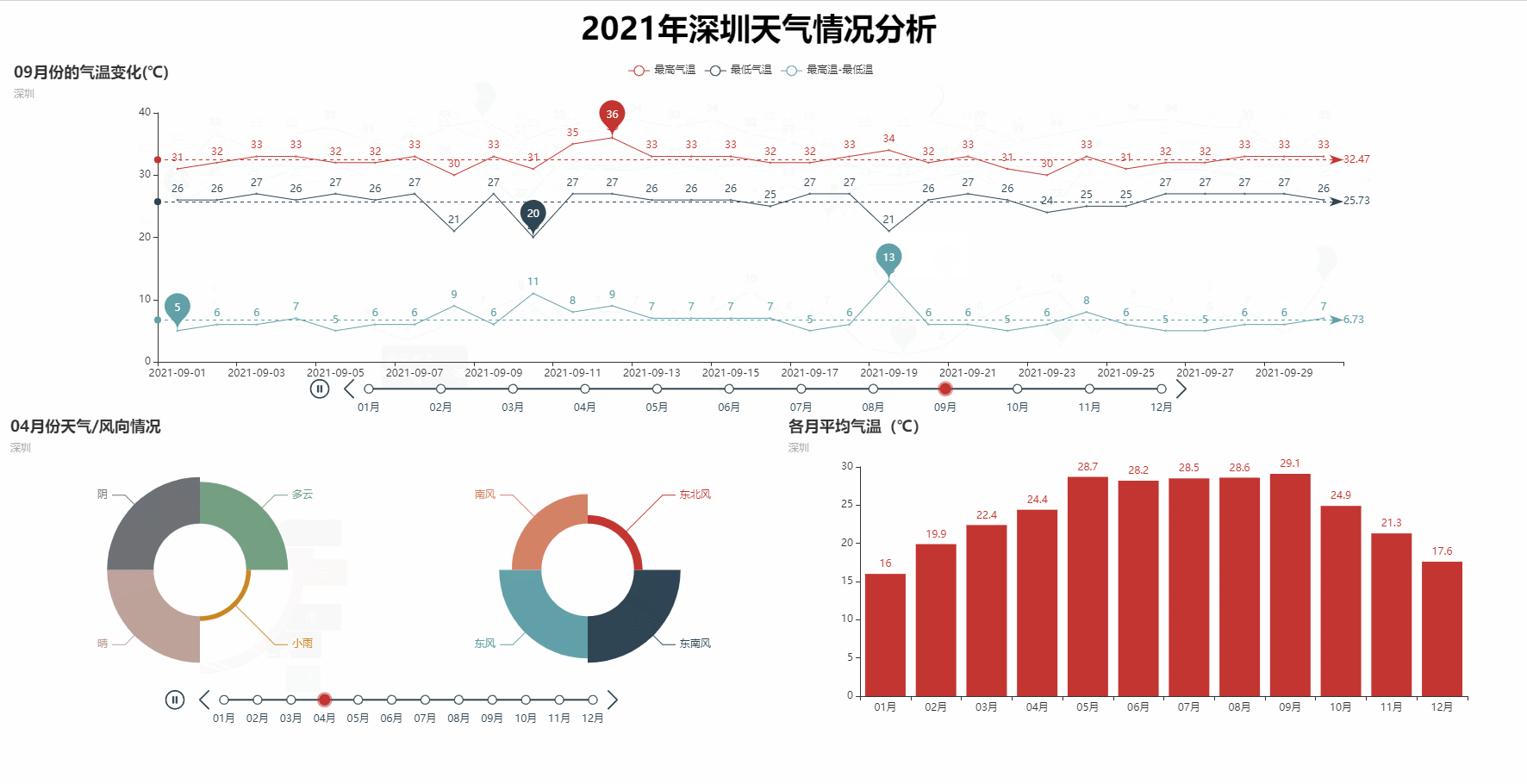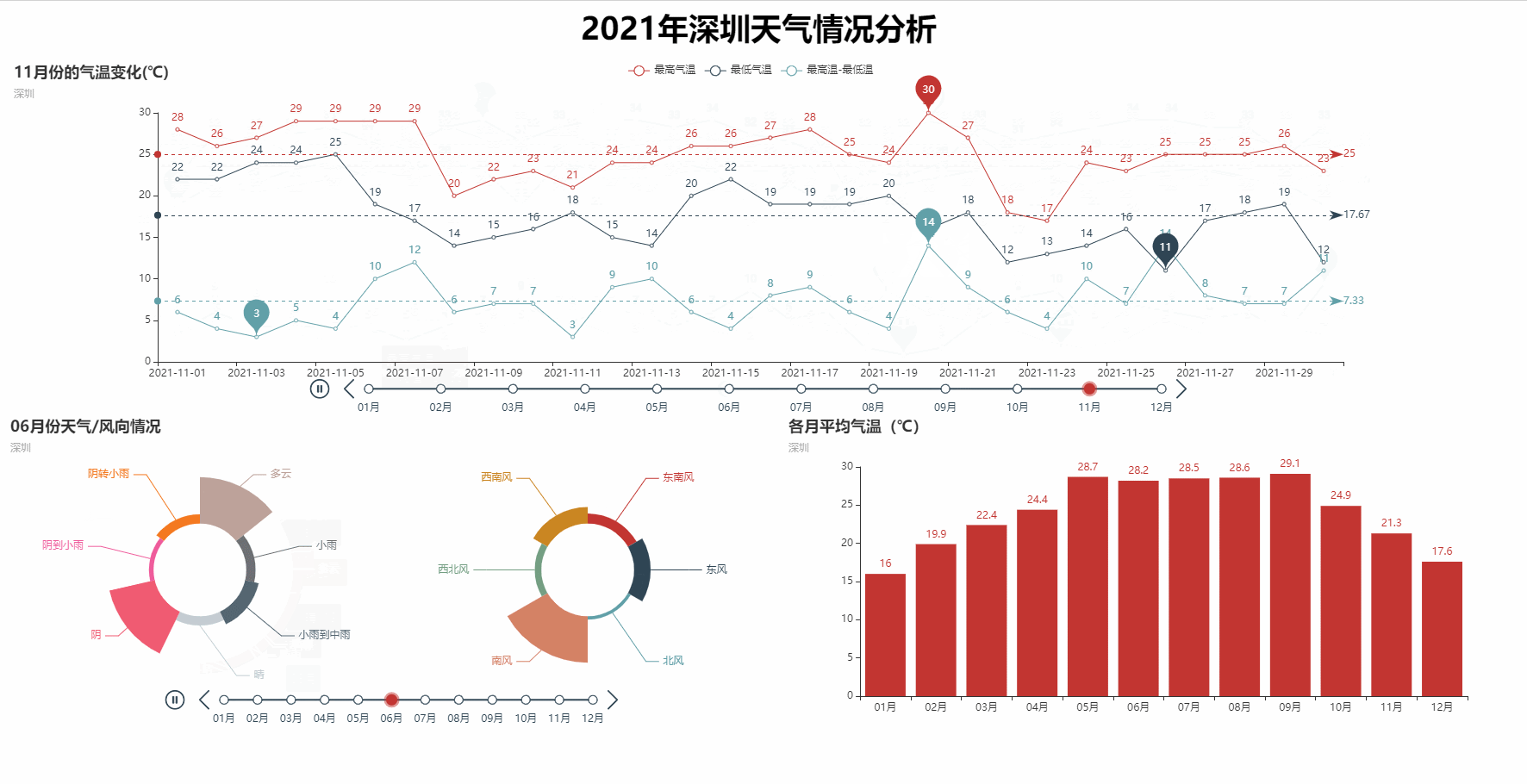
def t_line(datas, city):
'''绘制折线轮播图'''
t2 = Timeline()
for i in datas.month.unique():
data = datas[datas.month == i]
line = Line()
line.add_xaxis(data['date'].tolist())
#最高气温折线
line.add_yaxis('最高气温', data['h_temp'].tolist(),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='max', name='最大值'),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_='average', name='平均值')]
)
)
#最低气温折线
line.add_yaxis('最低气温', data['l_temp'].tolist(),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='min', name='最小值'),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_='average', name='平均值')]
)
)
#最高温与最低温的差值
line.add_yaxis('最高温-最低温', data['deltaT'].tolist(),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='max', name='最大值'),
opts.MarkPointItem(type_='min', name='最小值'),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_='average', name='平均值')]
)
)
line.set_global_opts(
title_opts=opts.TitleOpts(title="{}月份的气温变化(℃)".format(i), subtitle=city),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_='category')
)
t2.add(line, '{}月'.format(i))
return t2
def t_pie(datas, city):
"""绘制饼型轮播图"""
tp = Timeline()
for i in datas.month.unique():
data = datas[datas['month'] == i]
weather_datas = data.groupby('weather').size().reset_index()
weather_datas = [list(z) for z in zip(weather_datas['weather'], weather_datas[0])]
wind_datas = data.groupby('w_d0').size().reset_index()
wind_datas = [list(z) for z in zip(wind_datas['w_d0'], wind_datas[0])]
#风向情况
pie1 = (
Pie()
.add(
"",
wind_datas,
radius=["30%", "60%"],
center=["75%", "50%"],
rosetype="area",
)
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
)
#天气情况
pie2 = (
Pie()
.add(
"",
weather_datas,
radius=["30%", "60%"],
center=["25%", "50%"],
rosetype="area")
.set_global_opts(title_opts=opts.TitleOpts(title="{}月份天气/风向情况".format(i), subtitle=city),
legend_opts=opts.LegendOpts(is_show=False))
)
grid = (
Grid()
.add(pie1, grid_opts=opts.GridOpts(pos_left="55%"))
.add(pie2, grid_opts=opts.GridOpts(pos_right="55%"))
)
tp.add(grid, '{}月'.format(i))
return tp
def bar_plot(datas, city):
"""2021年12个月各月的平均气温"""
x_list = [i+'月' for i in datas.groupby('month')['averageT'].mean().index]
y_list = [round(i, 1) for i in datas.groupby('month')['averageT'].mean().values]
bar = Bar()
bar.add_xaxis(x_list)
bar.add_yaxis('', y_list)
bar.set_global_opts(title_opts=opts.TitleOpts(title='各月平均气温(℃)', subtitle=city))
return bar
def title(city):
"""利用Pie模块绘制页面标头"""
c = (
Pie()
.set_global_opts(
title_opts=opts.TitleOpts(title='2021年{}天气情况分析'.format(city),
title_textstyle_opts=opts.TextStyleOpts(font_size=36, color='#000000'),
pos_left='center',
pos_top='middle'))
)
return c
def page_layout(datas, city):
'''布置页面'''
page = Page(layout=Page.DraggablePageLayout)
page.add(
title(city),
bar_plot(datas, city),
t_line(datas, city),
t_pie(datas, city)
)
return page
def resave_page():
"""调整页面布局后重新存储生成新页面"""
page = Page()
page.save_resize_html(source='./2021年1-12月份深圳天气分析统计.html', cfg_file=r'./chart_config.json',
dest='mynew_render.html')
if __name__ == '__main__':
resave_page()
天气数据爬取+pyechart可视化的更多相关文章
- 豆瓣读书top250数据爬取与可视化
爬虫–scrapy 题目:根据豆瓣读书top250,根据出版社对书籍数量分类,绘制饼图 搭建环境 import scrapy import numpy as np import pandas as p ...
- python+echarts+flask实现对全国疫情数据的爬取并可视化展示
用Python进行数据爬取并存储到数据库,3.15学习总结(Python爬取网站数据并存入数据库) - 天岁 - 博客园 (cnblogs.com) 通过echarts+flask实现数据的可视化展示 ...
- 关于python的中国历年城市天气信息爬取
一.主题式网络爬虫设计方案(15分)1.主题式网络爬虫名称 关于python的中国城市天气网爬取 2.主题式网络爬虫爬取的内容与数据特征分析 爬取中国天气网各个城市每年各个月份的天气数据, 包括最高城 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- 用python写一个豆瓣短评通用爬虫(登录、爬取、可视化)
原创技术公众号:bigsai,本文在1024发布,祝大家节日快乐,心想事成. @ 目录 前言 登录 爬取 储存 可视化分析 前言 在本人上的一门课中,老师对每个小组有个任务要求,介绍和完成一个小模块. ...
- python新冠疫情分析-世界疫情数据爬取
事情发展:1.毕业设计是关于疫情数据的可视化展示(基于java,需要做数据可视化,需要做管理员端对数据进行增删改查处理)2.飞起来速度学爬虫,参考了非常多资料,比如b站的黑马爬取(报错,就是在切片那里 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
随机推荐
- HttpClient实现https调用
在HttpClient 4.x版本中引入了大量的构造器设计模式 https请求建立详解 首先建立一个信任任何密钥的策略.代码很简单,不去考虑证书链和授权类型,均认为是受信任的: class AnyTr ...
- 【Azure 应用服务】添加自定义域时,Domain ownership 验证无法通过
问题描述 在Azure App Service添加自定义域名时,遇见了Domain ownership 验证无法通过的问题? 问题解决 因为DNS中配置App Service默认域名和自定义域名的CN ...
- 【Azure Function】调试 VS Code Javascript Function本地不能运行,报错 Value cannot be null. (Parameter 'provider')问题
问题描述 参考官方文档,通过CS Code创建JavaScription Function,在本地远行时候出现: Value cannot be null. (Parameter 'provider' ...
- mysql-批量修改表的主键id,修改成联合主键
1.sql脚本 一. 通过sql脚本,查出所有表的功能,并编写插入修改的联合主键,sql select concat('ALTER table ', TABLE_NAME, ' DROP PRIMAR ...
- C++ //类模板对象做函数参数 //三种方式 //1.指定传入的类型 --直接显示对象的数据类型 //2.参数模板化 --将对象中的参数变为模板进行传递 //3.整个类模板化 --将这个对象类型 模板化进行传递
1 //类模板对象做函数参数 2 //三种方式 3 //1.指定传入的类型 --直接显示对象的数据类型 4 //2.参数模板化 --将对象中的参数变为模板进行传递 5 //3.整个类模板化 --将这个 ...
- AutoNumber VsCode插件开发
AutoNumber VsCode插件开发 ::: details 目录 目录 AutoNumber VsCode插件开发 Step. 2: 安装脚手架 Step. 3: 创建空项目 Step. 4: ...
- git svn 提交代码日志填写规范 BUG NEW DEL CHG TRP gitz 日志z
git svn 提交代码日志填写规范 BUG NEW DEL CHG TRP gitz 日志z
- 向TreeView添加自定义信息
可在 Windows 窗体 TreeView 控件中创建派生节点,或在 ListView 控件中创建派生项. 通过派生可添加任何所需字段,以及添加处理这些字段的自定义方法和构造函数. 此功能的用途之一 ...
- 启动Eclipse 弹出Failed to load the JNI shared library jvm.dll解决方案
原因:eclipse的版本与jdk版本不一致 解决方案:两者都安装64位的,或者都安装32位的,不能一个是32位一个是64位.
- Java加密技术(四)——非对称加密算法RSA
Java非对称加密算法rsa 接下来我们介绍典型的非对称加密算法--RSA RSA 这种算法1978年就出现了,它是第一个既能用于数据加密也能用于数字签名的算法.它易于理解和操作,也很 ...