【八】强化学习之DDPG---PaddlePaddlle【PARL】框架{飞桨}
相关文章:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
代码链接:码云:https://gitee.com/dingding962285595/parl_work ;github:https://github.com/PaddlePaddle/PARL
1. 连续动作空间
离散动作&连续动作
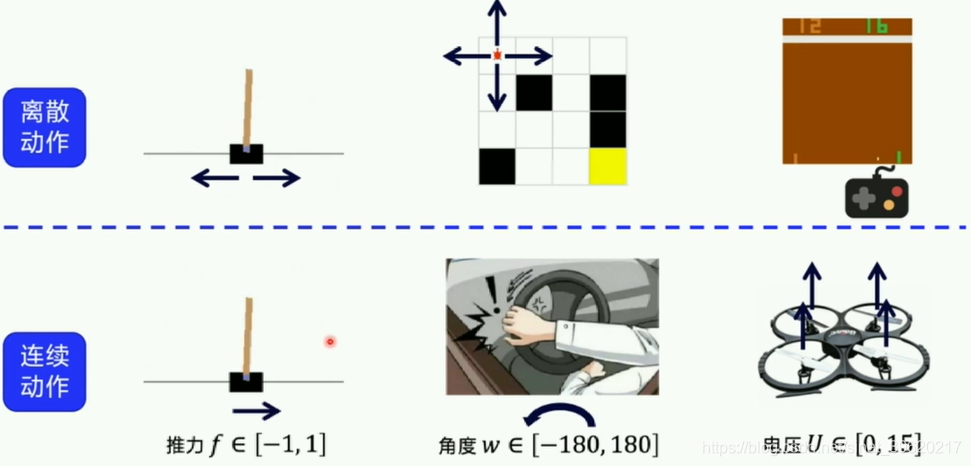
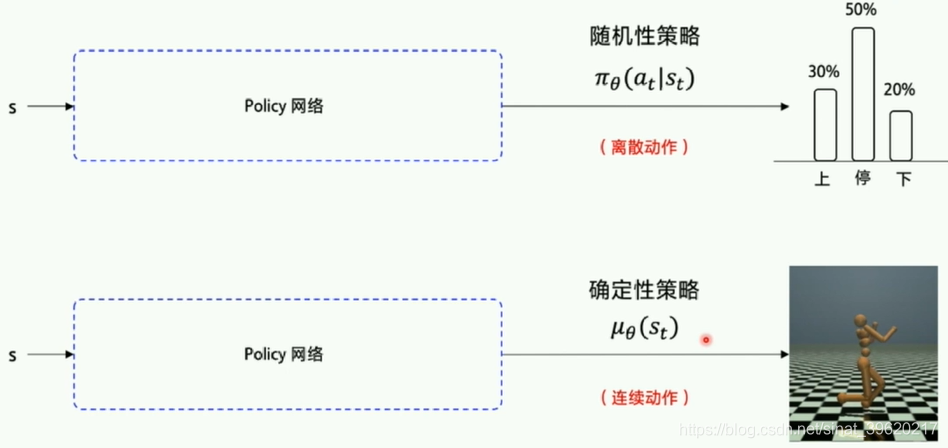
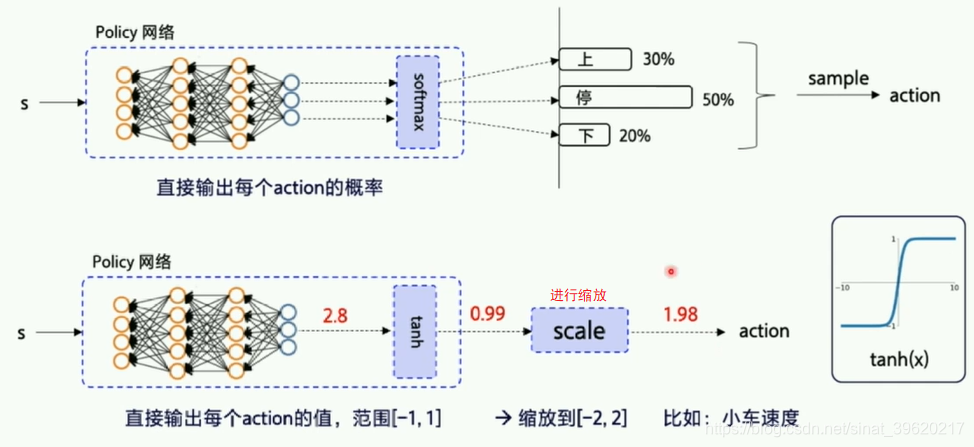
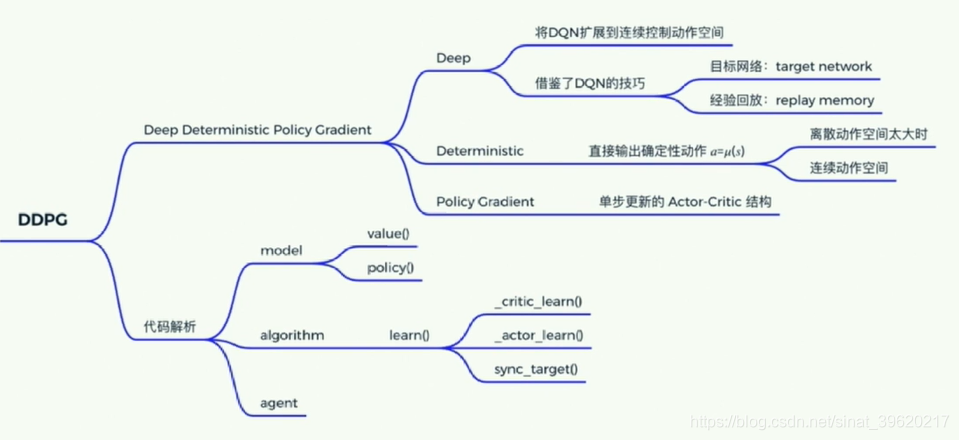
2.DDPG讲解Deep Deterministic Policy Gradient
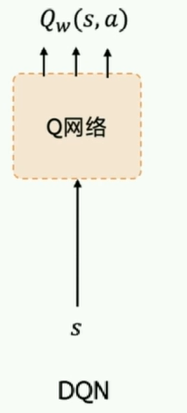
- deep-神经网络--DNQ扩展
目标网络 target work
经验回放 replay memory
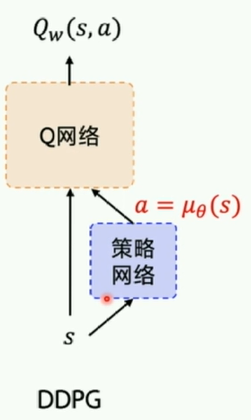
- Deterministic Policy Gradient
·Deterministic 直接输出确定的动作
·Policy Gradient 单步更新的policy网络
DDPG是DQN的扩展版本,可以扩展到连续控制动作空间
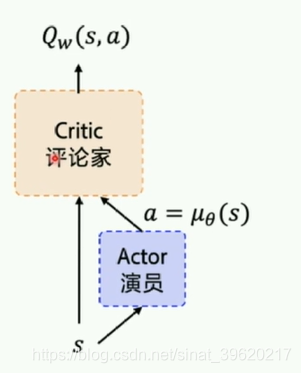
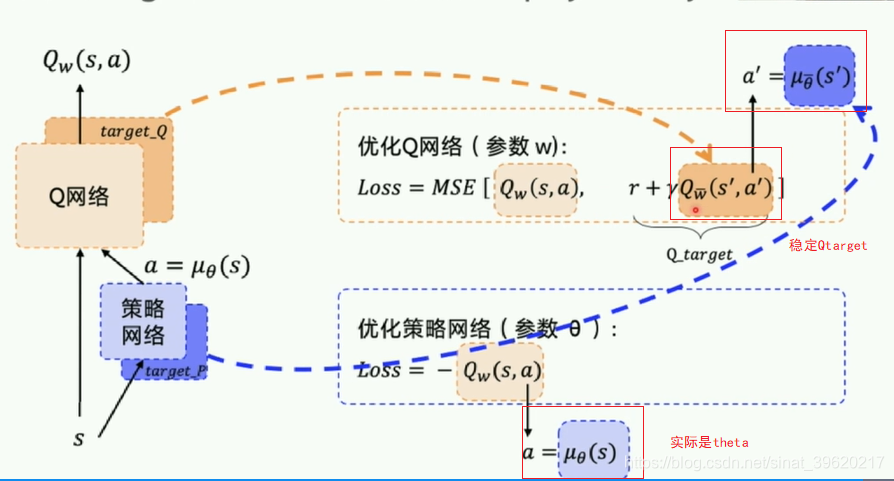
2.1 策略网络:
actor对外输出动作;critic会对每个输出的网络进行评估。刚开始随机参数初始化,然后根据reward不断地反馈。
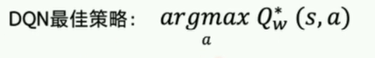

目标网络target network +经验回放ReplayMemory
两个target_Q/P网络的作用是稳定Q网络里的Q_target 复制原网络一段时间不变。
2.2 经验回放ReplayMemory
用到数据:
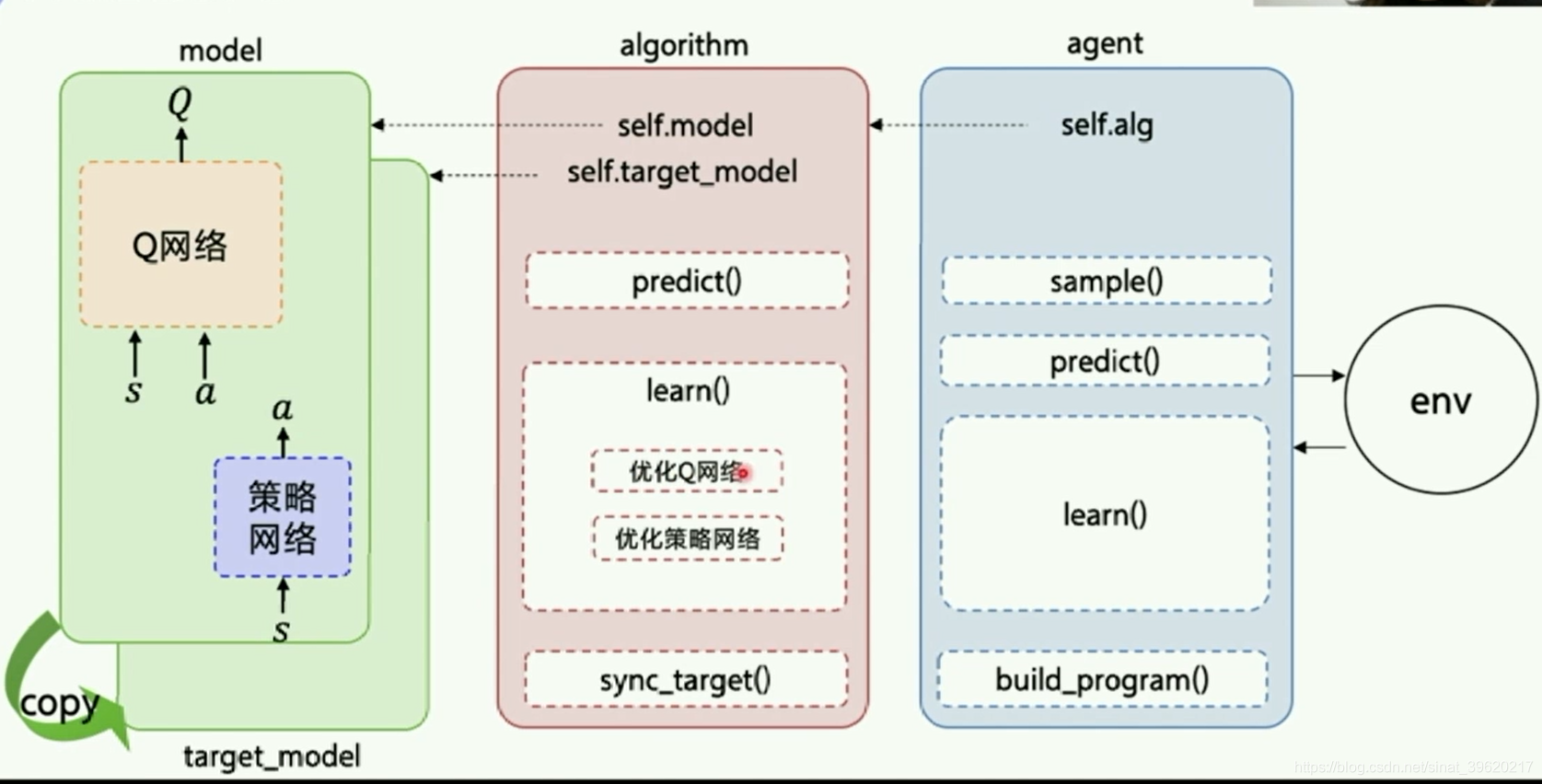
Agent把产生的数据传给algorithm,algorithm根据model的模型结构计算出Loss,使用SGD或者其他优化器不断的优化,PARL这种架构可以很方便的应用在各类深度强化学习问题中。
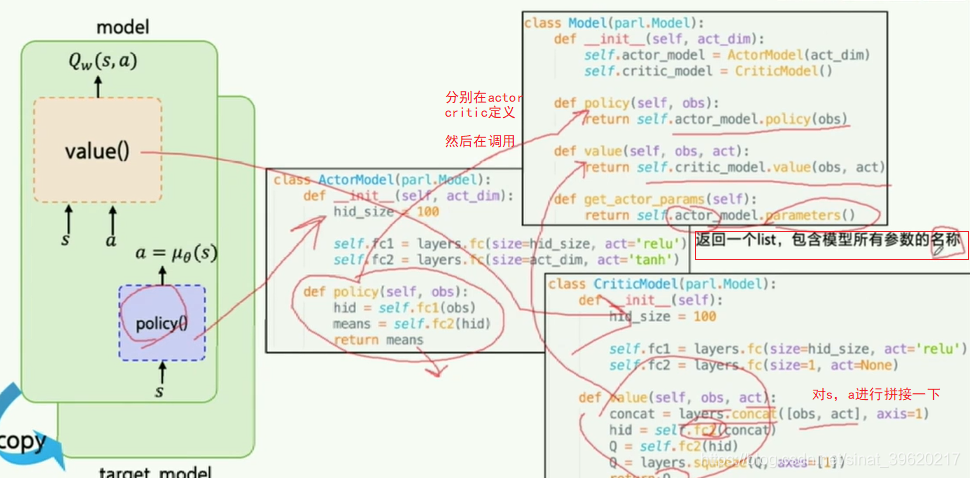
(1)Model
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构
class Model(parl.Model):
def __init__(self, act_dim):
self.actor_model = ActorModel(act_dim)
self.critic_model = CriticModel() def policy(self, obs):
return self.actor_model.policy(obs) def value(self, obs, act):
return self.critic_model.value(obs, act) def get_actor_params(self):
return self.actor_model.parameters()class ActorModel(parl.Model):
def __init__(self, act_dim):
hid_size = 100 self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=act_dim, act='tanh') def policy(self, obs):
hid = self.fc1(obs)
means = self.fc2(hid)
return means
class CriticModel(parl.Model):
def __init__(self):
hid_size = 100 self.fc1 = layers.fc(size=hid_size, act='relu')
self.fc2 = layers.fc(size=1, act=None) def value(self, obs, act):
concat = layers.concat([obs, act], axis=1)
hid = self.fc1(concat)
Q = self.fc2(hid)
Q = layers.squeeze(Q, axes=[1])
return Q
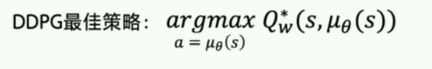

(2)Algorithm
Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
def _critic_learn(self, obs, action, reward, next_obs, terminal):
next_action = self.target_model.policy(next_obs)
next_Q = self.target_model.value(next_obs, next_action) terminal = layers.cast(terminal, dtype='float32')
target_Q = reward + (1.0 - terminal) * self.gamma * next_Q
target_Q.stop_gradient = True Q = self.model.value(obs, action)
cost = layers.square_error_cost(Q, target_Q)
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.AdamOptimizer(self.critic_lr)
optimizer.minimize(cost)
return cost

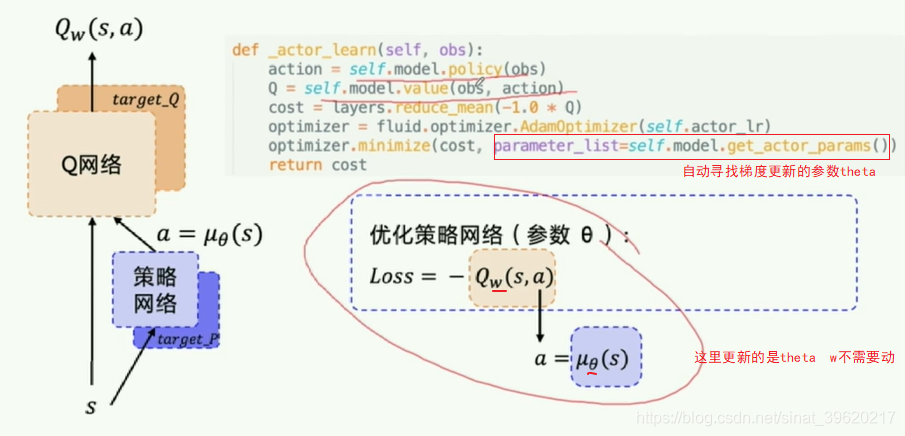
def _actor_learn(self, obs):
action = self.model.policy(obs)
Q = self.model.value(obs, action)
cost = layers.reduce_mean(-1.0 * Q)
optimizer = fluid.optimizer.AdamOptimizer(self.actor_lr)
optimizer.minimize(cost, parameter_list=self.model.get_actor_params())
return cost
软更新:每次更新一点参数,用\tau控制,按比例更新
硬更新:是每隔一段时间全部参数都更新
def sync_target(self, decay=None, share_vars_parallel_executor=None):
""" self.target_model从self.model复制参数过来,若decay不为None,则是软更新
"""
if decay is None:
decay = 1.0 - self.tau
self.model.sync_weights_to(
self.target_model,
decay=decay,
share_vars_parallel_executor=share_vars_parallel_executor)

(3)Agent
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
assert isinstance(obs_dim, int)
assert isinstance(act_dim, int)
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm) # 注意:最开始先同步self.model和self.target_model的参数.
self.alg.sync_target(decay=0) def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program() with fluid.program_guard(self.pred_program):
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
self.pred_act = self.alg.predict(obs) with fluid.program_guard(self.learn_program):
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(
name='act', shape=[self.act_dim], dtype='float32')
reward = layers.data(name='reward', shape=[], dtype='float32')
next_obs = layers.data(
name='next_obs', shape=[self.obs_dim], dtype='float32')
terminal = layers.data(name='terminal', shape=[], dtype='bool')
_, self.critic_cost = self.alg.learn(obs, act, reward, next_obs,
terminal) def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
act = self.fluid_executor.run(
self.pred_program, feed={'obs': obs},
fetch_list=[self.pred_act])[0]
act = np.squeeze(act)
return act def learn(self, obs, act, reward, next_obs, terminal):
feed = {
'obs': obs,
'act': act,
'reward': reward,
'next_obs': next_obs,
'terminal': terminal
}
critic_cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.critic_cost])[0]
self.alg.sync_target()
return critic_cost
(4)env.py
连续控制版本的CartPole环境
- 该环境代码与算法无关,可忽略不看,参考gym
(5)经验池 ReplayMemory
- 与
DQN的replay_mamory.py代码一致class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size) def append(self, exp):
self.buffer.append(exp) def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], [] for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done) return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32') def __len__(self):
return len(self.buffer)
(6)train
# 训练一个episode
def run_episode(agent, env, rpm):
obs = env.reset()
total_reward = 0
steps = 0
while True:
steps += 1
batch_obs = np.expand_dims(obs, axis=0)
action = agent.predict(batch_obs.astype('float32')) # 增加探索扰动, 输出限制在 [-1.0, 1.0] 范围内
action = np.clip(np.random.normal(action, NOISE), -1.0, 1.0) next_obs, reward, done, info = env.step(action) action = [action] # 方便存入replaymemory
rpm.append((obs, action, REWARD_SCALE * reward, next_obs, done)) if len(rpm) > MEMORY_WARMUP_SIZE and (steps % 5) == 0:
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) obs = next_obs
total_reward += reward if done or steps >= 200:
break
return total_reward增加扰动保持探索,添加一个高斯噪声。np.clip做一下裁剪,确保在合适的范围内。
总结
【八】强化学习之DDPG---PaddlePaddlle【PARL】框架{飞桨}的更多相关文章
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- 深度强化学习:Policy-Based methods、Actor-Critic以及DDPG
Policy-Based methods 在上篇文章中介绍的Deep Q-Learning算法属于基于价值(Value-Based)的方法,即估计最优的action-value function $q ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- 谷歌重磅开源强化学习框架Dopamine吊打OpenAI
谷歌重磅开源强化学习框架Dopamine吊打OpenAI 近日OpenAI在Dota 2上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不 ...
- NABCD框架(作业和事件的定期提醒)及第八周学习进度条
NABCD框架(作业和事件的定期提醒): N(need,需求): 你的创意解决了用户的什么需求? 我们的创意能够一定程度上督促我们的用户(学生)尽快完成自己近期的任务或者是作业.我们认为如果增设定时提 ...
- 谷歌推出新型强化学习框架Dopamine
今日,谷歌发布博客介绍其最新推出的强化学习新框架 Dopamine,该框架基于 TensorFlow,可提供灵活性.稳定性.复现性,以及快速的基准测试. GitHub repo:https://git ...
- 强化学习调参技巧二:DDPG、TD3、SAC算法为例:
1.训练环境如何正确编写 强化学习里的 env.reset() env.step() 就是训练环境.其编写流程如下: 1.1 初始阶段: 先写一个简化版的训练环境.把任务难度降到最低,确保一定能正常训 ...
随机推荐
- peewee update和save性能分析
背景 python项目中使用了peewee这款orm框架,在对数据库更新时有两种语法,分别是save和update方法.有同事说从peewee的日志来看,update比save更快,于是做了一个简单的 ...
- 解密Prompt系列23.大模型幻觉分类&归因&检测&缓解方案脑图全梳理
上一章我们主要聊聊RAG场景下的幻觉检测和解决方案,这一章我们单独针对大模型的幻觉问题,从幻觉类型,幻觉来源,幻觉检测,幻觉缓解这四个方向进行整理.这里就不细说任意一种方法了,因为说不完根本说不完,索 ...
- 【mongodb】pymongo使用
pymongo基本使用 import pymongo from bson.objectid import ObjectId # 连接方式1 client = pymongo.MongoClient(h ...
- 0x41 数据结构进阶-并查集
A题 程序自动分析 题目链接:https://ac.nowcoder.com/acm/contest/1031/A 题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考 ...
- 【每日一题】8.Shortest Path (树上DFS)
题目链接:Here 题意总结:给定的是无向图(树),要求把分成 \(n/2\) 对 让权值最小 思路: 看一下范围 在加上是一棵树 所以做法应该是dfs 复杂度为 \(\mathcal{O}(n)\) ...
- 深入剖析 RSA 密钥原理及实践
一.前言 在经历了人生的很多至暗时刻后,你读到了这篇文章,你会后悔甚至愤怒:为什么你没有早点写出这篇文章?! 你的至暗时刻包括: 1.你所在的项目需要对接银行,对方需要你提供一个加密证书.你手上只有一 ...
- Contest3376 - 2024寒假集训-排位赛竞赛(一)
A: 幂位和 高精度. 用高精度加法或乘法算出\(2^{1000}\),再将各位累加即为答案. #include <bits/stdc++.h> using namespace std; ...
- 如何使用chatgpt编写代码
功能列举 回答编程问题 我想让你充当 Stackoverflow 的帖子.我将提出与编程有关的问题,你将回答答案是什么.我希望你只回答给定的答案,在没有足够的细节时写出解释.当我需要用英语告诉你一些事 ...
- Linux 安装 mysql 及配置存储位置
本文为博主原创,未经允许不得转载: 新申请的服务器,需要确认服务器的磁盘是否进行了挂载,可参考这篇文章:https://www.cnblogs.com/zjdxr-up/p/14873242.html ...
- 搞了个Blazor工具站,域名一次性买了10年!
大家好,我是沙漠尽头的狼. 在 Dotnet9 上线在线小工具和小游戏后,服务器的压力感觉挺大的,打开25个页面,内存占用170MB左右,CPU保持在60~70%,看来Server真不适合搞这类交互较 ...