C语言无锁高并发安全环形缓冲队列设计(一)
1、前言
队列,常用数据结构之一,特点是先进先出。
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
2、设计思想
从理想的无限缓冲区到实际的使用进行设计思考。
2.1、理想化的无限缓冲区
在理想情况下,写入器(数据生产者)和读取器(数据消费者)在使用过程中,能够访问相同的、连续的、并且是无限的缓冲区。写入器和读取器各自保存一个索引,分别指向缓冲区中写和读的位置,即与之对齐的“写”和“读”指针开始进行操作。
当写入器想要在末端加入数据时,它会将数据追加到“写索引”后面的位置,之后将“写索引”移动到新写数据块的末尾。而读取器在顶端读取数据时,如果“写索引”比“读索引”位置大时,读写器就可以对已有数据进行读取操作。完成之后,读写器将“读索引”移动到读取数据块的末尾,以跟踪记录已经处理至缓冲区的哪一部分。

读取器永远不会试图读取超过“写索引”位置的数据,因为不能保证那里有有效的数据,即写入器在那里写入了东西。这也意味着“读索引”永远不能超过“写索引”。目前为止,我们假设这个理想内存系统总是连贯一致的,也就是说一旦执行了写操作,数据可以立即地、顺序地进行读取出来。
2.2、有界限的缓冲区
而现实中计算机并没有神奇的无限缓冲区。我们必须分配有限的内存空间,以供写入器和读取器之间进行或许无限的使用。在循环缓冲区中,“写索引”可以在抵达缓冲区末尾时跨越缓冲区的边界回绕到缓冲区的开始位置。
当“写索引”接近缓冲区末尾并且又有新数据输入进来时,会将写操作分成两个数据块:一个写入缓冲区末尾剩余的空间,另一个将剩下的数据写入缓冲区开头。请注意,如果此时“读索引”位置接近缓冲区开头,那么这个写入操作可能会破坏尚未被读取器处理的数据。由于这个原因,“写索引”在被回绕后不允许超过“读索引”。
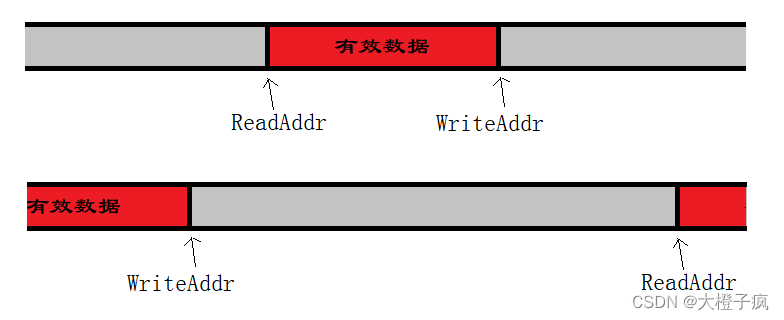
这样下来,可能会得到两种内存分布情况:
“写索引”在前面,“读索引”在后面,即在索引移动方向上,“写索引”超前于“读索引”,已写入但未被读取器处理的有效数据位于“读索引”和“写索引”之间的缓冲区内;
“读索引”在前面,“写索引”在后面,即在索引移动方向上,“读索引”超前于“写索引”,有效数据开始于“读索引”,结束于缓冲区末尾,并回绕到缓冲区开头直至“写索引”位置。
注意:上述第二种情况下,“写索引”和“读索引”可能存在重合,为了区分这两种情况,一般规定第二种情况下“写索引”和“读索引”不允许重合,即“写索引”位置必须落后于“读索引”一步。
因此,在循环缓冲区中,不断地从内存分布情况 1 进行到内存分布情况 2,又从 2 再回到 1,如此循环往复,当“读索引”到达缓冲区的末尾时,也回绕到缓冲区开头继续进行读取。
2.3、并发性设计
通常在使用缓冲区队列时,读数据和写数据大部分情况都是多线程或者前后台(中断)分别处理的,为了减少写入器、读取器两个线程之间或者前后台系统之间需要发生的协调,一种常见策略是,将读写变量独立出来,分别由读取器和写入器进行改变。这也简化了并发性设计中的逻辑推理,因为谁负责更改哪个变量总是很清楚。
让我们从一个简单的循环缓冲区开始,它具有原始的“写索引”和“读索引”。唯有写入器能更改“写索引”,而唯有读取器能更改“读索引”。
这样就可以不用锁进行操作,提高效率。
2.4、如何保证地址的连续性
在上述提到的有界缓冲区内存分布情况,第二种情况无法保证地址的连续性,因为有些场景需要使用到连续的内存块地址,解决这种场景的办法有:可以对缓存区进行分块,每一块固定的长度,即固定长度的队列,这样就能在一定程度上保证了地址的连续性。
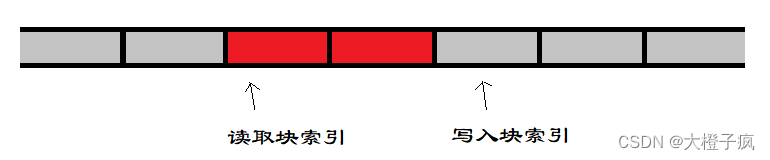
3、代码实现
3.1、队列结构体定义
先定义一个队列结构体,包含了每个块的大小、数目、写入块索引、读取块索引等,为了解决“写索引”和“读索引”可能存在重合的两种情况,加入状态变量用来区分。
typedef uint16_t queuesize_t;
typedef struct{
volatile uint8_t state; /*!< 控制状态 */
queuesize_t end; /*!< 循环队列尾哨兵 */
queuesize_t head; /*!< 循环队列首哨兵 */
queuesize_t num; /*!< 循环队列中能存储的最多组数 */
queuesize_t size; /*!< 单组内存大小 */
char *pBufMem; /*!< Buf 指针 */
} QueueCtrl_t;3.2、队列初始化
定义结构体后一定要对数据初始化,同时为接口提供一些入参变量设置队列的信息进行封装,如缓存区地址、队列的组数目、组内存大小和是否内存覆盖等信息。
/**
* @brief 队列控制初始化, 可采用的是动态/静态内存分配方式
*
* @param[in,out] pCtrl 队列控制句柄
* @param[in] buf buf 地址
* @param[in] queueNum 队列数目大小
* @param[in] size 队列中单个内存大小
* @param[in] isCover false,不覆盖; true,队列满了覆盖未读取的最早旧数据
* @return 0,成功; -1,失败
*/
int Queue_Init(QueueCtrl_t *pCtrl, const void *pBufMem, queuesize_t queueNum, queuesize_t size, bool isCover)
{
if (pCtrl == NULL || pBufMem == NULL || queueNum == 0 || size == 0)
{
return -1;
}
pCtrl->end = 0;
pCtrl->head = 0;
pCtrl->pBufMem = (char *)pBufMem;
pCtrl->num = queueNum;
pCtrl->size = size;
pCtrl->state = 0x00;
if (isCover)
{
QUEUE_STATE_SET(pCtrl, QUEUE_ENABLE_COVER);
}
return 0;
}3.3、队列写操作
队列都是在末端增加数据,因为队列组的大小已经固定,因此在写操作数据时可以省略新数据的内存大小。
/**
* @brief 在队列末尾加入新的数据
*
* @param[in,out] pCtrl 队列控制句柄
* @param[in] src 新的数据
* @retval 返回的值含义如下
* @arg 0: 写入成功
* @arg -1: 写入失败
*/
extern int Queue_Push(QueueCtrl_t *pCtrl, const void *src)
{
if (pCtrl == NULL || src == NULL)
{
return -1;
}
if (IS_QUEUE_STATE_SET(pCtrl, QUEUE_DISABLE_PUSH))
{
return -1;
}
memcpy(&pCtrl->pBufMem[pCtrl->end * pCtrl->size], src, pCtrl->size);
pCtrl->end++;
QUEUE_STATE_SET(pCtrl, QUEUE_EXIT_DATA);
if ((pCtrl->end) >= (pCtrl->num))
{
(pCtrl->end) = 0;
}
if (IS_QUEUE_STATE_SET(pCtrl, QUEUE_DATA_FULL))
{
(pCtrl->head) = (pCtrl->end);
}
else if ((pCtrl->end) == (pCtrl->head))
{
QUEUE_STATE_SET(pCtrl, QUEUE_DATA_FULL);
if (!IS_QUEUE_STATE_SET(pCtrl, QUEUE_ENABLE_COVER))
{
QUEUE_STATE_SET(pCtrl, QUEUE_DISABLE_PUSH);
}
}
return 0;
}3.4、队列读操作
队列都是在顶端读取数据,因为队列组的大小已经固定,因此在都操作数据时可以省略数据读取存入的内存大小(必须保证读取的内存大小足够)。
/**
* @brief 读取并弹出队列顶端的数据
*
* @param[in,out] pCtrl 队列控制句柄
* @param[in] dest 读取的数据
* @retval 返回的值含义如下
* @arg 0: 成功
* @arg -1: 失败
*/
int Queue_Pop(QueueCtrl_t *pCtrl, void *dest)
{
if (pCtrl == NULL)
{
return -1;
}
if (!IS_QUEUE_STATE_SET(pCtrl, QUEUE_EXIT_DATA))
{
return -1;
}
memcpy((char *)dest, &pCtrl->pBufMem[pCtrl->head * pCtrl->size], pCtrl->size);
pCtrl->head++;
if ((pCtrl->head) >= (pCtrl->num))
{
pCtrl->head = 0;
}
if ((pCtrl->head) == (pCtrl->end))
{
if (!IS_QUEUE_STATE_SET(pCtrl, QUEUE_DATA_FULL))
{
QUEUE_STATE_CLEAR(pCtrl, QUEUE_EXIT_DATA);
}
}
QUEUE_STATE_CLEAR(pCtrl, QUEUE_DISABLE_PUSH);
QUEUE_STATE_CLEAR(pCtrl, QUEUE_DATA_FULL);
return 0;
}4、代码实现
代码可下载:queue
C语言无锁高并发安全环形缓冲队列设计(一)的更多相关文章
- Java互联网架构-直播互动平台高并发分布式架构应用设计
概述 网页HTML 静态化: 其实大家都知道网页静态化,效率最高,消耗最小的就是纯静态化的 html 页面,所以我们尽可能使我们的网站上的页面采用静态页面来实现,这个最简单的方法其实也是最有效的方法, ...
- nodejs高并发大流量的设计实现,控制并发的三种方法
nodejs高并发大流量的设计实现,控制并发的三种方法eventproxy.async.mapLimit.async.queue控制并发Node.js是建立在Google V8 JavaScript引 ...
- Go语言无锁队列组件的实现 (chan/interface/select)
1. 背景 go代码中要实现异步很简单,go funcName(). 但是进程需要控制协程数量在合理范围内,对应大批量任务可以使用"协程池 + 无锁队列"实现. 2. golang ...
- 【数据结构】C++语言无锁环形队列的实现
无锁环形队列 1.Ring_Queue在payload前加入一个头,来表示当前节点的状态 2.当前节点的状态包括可以读.可以写.正在读.正在写 3.当读完成后将节点状态改为可以写,当写完成后将节点状态 ...
- 从SpringBoot构建十万博文聊聊高并发文章浏览量设计
前言 在经历了,缓存.限流.布隆穿透等等一系列加强功能,十万博客基本算是成型,网站上线以后也加入了百度统计来见证十万+ 的整个过程. 但是百度统计并不能对每篇博文进行详细的浏览量统计,如果做一些热点博 ...
- 应用案例——高并发 WEB 服务器队列的应用
在高并发 HTTP 反向代理服务器 Nginx 中,存在着一个跟性能息息相关的模块 - 文件缓存. 经常访问到的文件会被 nginx 从磁盘缓存到内存,这样可以极大的提高 Nginx 的并发能力,不过 ...
- JAVA高并发系列
高并发Java(1):前言 高并发Java(2):多线程基础 高并发Java(3):Java内存模型和线程安全 高并发Java(4):无锁 高并发Java(5):JDK并发包1 高并发Java(6): ...
- disruptor 高并发编程 简介demo
原文地址:http://www.cnblogs.com/qiaoyihang/p/6479994.html disruptor适用于大规模低延迟的并发场景.可用于读写操作分离.数据缓存,速度匹配(因为 ...
- 【实战Java高并发程序设计6】挑战无锁算法:无锁的Vector实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
- Surfer 高并发双核无头浏览器 (Golang语言)
Surfer A high level concurrency downloader. surfer是一款Go语言编写的高并发爬虫下载器,拥有surf与phantom两种下载内核. 支持固定Use ...
随机推荐
- 1、springboot工程新建(单模块)
系列导航 springBoot项目打jar包 1.springboot工程新建(单模块) 2.springboot创建多模块工程 3.springboot连接数据库 4.SpringBoot连接数据库 ...
- proxy代理
- vue.js从输入中的contenteditable元素获取innerhtml
<div class="actual-score" :contenteditable="$route.params.mode === 'edit'" v- ...
- 从零开发一款图片编辑器(使用html5+javascript)
最近开发了一个图片编辑器,类似于photoshop的网页版,源码参考自GitHub上,顺便也总结下使用html+js开发一个编辑器需要用到哪些知识点. 预览地址: https://ps.gitapp. ...
- 基于AHB_BUS的eFlash控制器设计-软硬件系统设计
eFlash软硬件系统设计 软硬件划分 划分好软硬件之后,IP暴露给软件的寄存器和时序如何? 文档体系:详细介绍eflash控制器的设计文档 RTL代码编写:详细介绍eflash控制器的RTL代码 1 ...
- 【C/C++】 代码质量控制手段
问题引入 多人协作开发的项目,没有统一的代码规范,那么最终的编写状态必定风格迥异,产生的结果:对内,阅读审核代码是很痛苦的:对外,公司形象就是差. 单干的项目也必须要严格按照代码规范,因为最终还是会对 ...
- 【scikit-learn基础】--『回归模型评估』之偏差分析
模型评估在统计学和机器学习中具有至关重要,它帮助我们主要目标是量化模型预测新数据的能力. 本篇主要介绍模型评估时,如何利用scikit-learn帮助我们快速进行各种偏差的分析. 1. **R² ** ...
- [转帖]浅析SQL数据类型的隐式转换与显式转换以及隐式转换可能导致的问题
https://www.cnblogs.com/goloving/p/15222604.html 一.隐式类型转换问题 1.隐式类型转换: 比如:SELECT 1 + '1'; 2.隐式类型转换的问题 ...
- [转帖]mysql-connect-java驱动从5.x升级到8.x的CST时区问题
https://juejin.cn/post/7029291622537887774 前言 旧项目MySQL Java升级驱动,本来一切都好好的,但是升级到8.x的驱动后,发现入库的时间比实际时间 ...
- [转帖]CENTOS6.5 没有/LIB64/LIBFUSE.SO.2的问题
yum install fuse-libs