ASCII、Unicode、UTF8 10年后,史无前例,自己用js实现《专题3》
我自己史无前例的开发了一个网页小工具,可以利用这个工具 直接查询到 一个字符的unicode二进制的定义,和utf8格式下内存中 存储的二进制。
============================================================================================================================
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div><h1 >得出一个字符的二进制,英文或中文都是一个字符,一个字符对应1-n个字节《完全自主思考开发》</h1></div>
<div>输入一个字符:<input type="text" id="zifu"> <button onclick="showJinZhi()">开始运行</button></div>
<br/>
<div>Unicode 2进制:<label id="unicode_b"></label></div><br/>
<div>Unicode 10进制:<label id="unicode_d"></label></div><br/>
<div>Unicode 16进制:<label id="unicode_x"></label></div><br/>
<div>UTF-8格式存储 2进制:<label id="utf8_b"></label></div><br/>
<div>UTF-8格式存储 10进制:<label id="utf8_d"></label></div><br/>
<div>UTF-8格式存储 16进制:<label id="utf8_x"></label></div><br/>
<div>
注意点:<br/>
1. unicode只是一种规定,通常存储到内存中时用不到;<br/>
2. Java18也开始默认Utf8存储了,以后估计都会utf8,其它存储格式可忽略<br/>
</div> <script> /**
* 把二进制的字符串,以4位一组 隔开输出
*/
function binFormat(bitStr) {
//开始格式化
let newBitStr = "";
let position = 0;
while (position != bitStr.length){
//截取4个
newBitStr = newBitStr + " " + bitStr.substring(position, position + 4);
position = position + 4;
}
return newBitStr.trim();//去除第一个空格
} /**
* 显示进制
*/
function showJinZhi(){
/*
在Unicode编码中,由于码点大于0xFFFF的字符必须用双字节表示,导致使用String.length获取这些字符串长度时会返回2。
"啊".length
// 1
"".length
// 2
那么我们该如何正确的获取包含这些字符的字符串长度呢?
此时可以使用ES6新增的扩展运算符(...)将字符串转为数组,然后获取数组的长度。
[...""].length
// 1
他妈的,这太坑了
*/
let zifu = document.getElementById("zifu").value;
if([...zifu].length != 1){
alert("请输入一个字符");
return;
} //得到这个字符对应的unicode字节的进制表示法,.codePointAt(0) 就是字符串的第一个字符
let unicodeDec = zifu.codePointAt(0);
let unicodeBitStr = unicodeDec.toString(2);
document.getElementById("unicode_b").innerText = unicodeBitStr + "(unicode只是一种规定,不真正存储,不格式化了,忽略前面的0)";
document.getElementById("unicode_d").innerText = unicodeDec.toString(10);
document.getElementById("unicode_x").innerText = unicodeDec.toString(16).toUpperCase(); /*
得到这个字符对应的unicode字节的10进制,根据10进制来直观的得出utf8格式下需要几个字节;
可以看下我自己的博客,utf8下 10进制 对应的 字节数如下:
0 - 127 1个字节
128 - 2047 2个字节
2048 - 65535 3个字节
65536 - 1114 111 4个字节
*/
if(unicodeDec <= 127){
//一个字节时把缺省的0补全
let zeroStr = "";
for (let i = 0; i < (8 - unicodeBitStr.length); i++) {
zeroStr += "0";
}
document.getElementById("utf8_b").innerText = binFormat(zeroStr + unicodeBitStr) + "(1个字节)";
document.getElementById("utf8_d").innerText = unicodeDec.toString(10);
document.getElementById("utf8_x").innerText = unicodeDec.toString(16).toUpperCase();
} if(unicodeDec >= 128 && unicodeDec <= 2047){
/*
128的二进制为: 1000 0000,2047 的二进制为:1111 1111 111
由于高位为0的时候会省略掉,所以Unicode二进制的字符串的位数为: 8 =< bitStrLength <= 11
*/
//分别获取各个字节的bit字符串
let oneBitStr, twoBitStr, utf8BitStr;
if(unicodeBitStr.length == 8){
oneBitStr = "110000" + unicodeBitStr.substring(0, 2);
}else if (unicodeBitStr.length == 9) {
oneBitStr = "11000" + unicodeBitStr.substring(0, 3);
}else if (unicodeBitStr.length == 10) {
oneBitStr = "1100" + unicodeBitStr.substring(0, 4);
}else if (unicodeBitStr.length == 11) {
oneBitStr = "110" + unicodeBitStr.substring(0, 5);
}
twoBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length -6, unicodeBitStr.length);
utf8BitStr = oneBitStr + twoBitStr; document.getElementById("utf8_b").innerText = binFormat(utf8BitStr) + "(2个字节)";
document.getElementById("utf8_d").innerText = parseInt(utf8BitStr, 2).toString(10);
document.getElementById("utf8_x").innerText = parseInt(utf8BitStr, 2).toString(16).toUpperCase();
} if(unicodeDec >= 2048 && unicodeDec <= 65535){
/*
2048的二进制为: 1000 0000 0000,65535 的二进制为:1111 1111 1111 1111
由于高位为0的时候会省略掉,所以Unicode二进制的字符串的位数为: 12 =< bitStrLength <= 16
*/
//分别获取各个字节的bit字符串
let oneBitStr, twoBitStr, threeBitStr, utf8BitStr;
if(unicodeBitStr.length == 12){
oneBitStr = "11100000";
}else if (unicodeBitStr.length == 13) {
oneBitStr = "1110000" + unicodeBitStr.substring(0, 1);
}else if (unicodeBitStr.length == 14) {
oneBitStr = "111000" + unicodeBitStr.substring(0, 2);
}else if (unicodeBitStr.length == 15) {
oneBitStr = "11100" + unicodeBitStr.substring(0, 3);
}else if (unicodeBitStr.length == 16) {
oneBitStr = "1110" + unicodeBitStr.substring(0, 4);
}
twoBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length -12, unicodeBitStr.length-6);
threeBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length -6, unicodeBitStr.length);
utf8BitStr = oneBitStr + twoBitStr + threeBitStr; document.getElementById("utf8_b").innerText = binFormat(utf8BitStr) + "(3个字节)";
document.getElementById("utf8_d").innerText = parseInt(utf8BitStr, 2).toString(10);
document.getElementById("utf8_x").innerText = parseInt(utf8BitStr, 2).toString(16).toUpperCase();
} if(unicodeDec >= 65536 && unicodeDec <= 1114111){
/*
65536的二进制为: 1000 0000 0000 0000 0,1114111 的二进制为:1000 0111 1111 1111 1111 1
由于高位为0的时候会省略掉,所以Unicode二进制的字符串的位数为: 17 =< bitStrLength <= 21
*/
//分别获取各个字节的bit字符串
let oneBitStr, twoBitStr, threeBitStr, fourBitStr, utf8BitStr;
if(unicodeBitStr.length == 17){
oneBitStr = "11110000";
}else if (unicodeBitStr.length == 18) {
oneBitStr = "11110000";
}else if (unicodeBitStr.length == 19) {
oneBitStr = "1111000" + unicodeBitStr.substring(0, 1);
}else if (unicodeBitStr.length == 20) {
oneBitStr = "111100" + unicodeBitStr.substring(0, 2);
}else if (unicodeBitStr.length == 21) {
oneBitStr = "11110" + unicodeBitStr.substring(0, 3);
}
if(unicodeBitStr.length == 17){
twoBitStr = "100" + unicodeBitStr.substring(0, 5);
}else {
twoBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length - 18, unicodeBitStr.length - 12);
}
threeBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length - 12, unicodeBitStr.length - 6);
fourBitStr = "10" + unicodeBitStr.substring(unicodeBitStr.length - 6, unicodeBitStr.length);
utf8BitStr = oneBitStr + twoBitStr + threeBitStr + fourBitStr; document.getElementById("utf8_b").innerText = binFormat(utf8BitStr) + "(4个字节)";
document.getElementById("utf8_d").innerText = parseInt(utf8BitStr, 2).toString(10);
document.getElementById("utf8_x").innerText = parseInt(utf8BitStr, 2).toString(16).toUpperCase();
}
}
</script>
</body>
</html>
将以上代码保持至html就可在浏览器中运行。一下是例子:
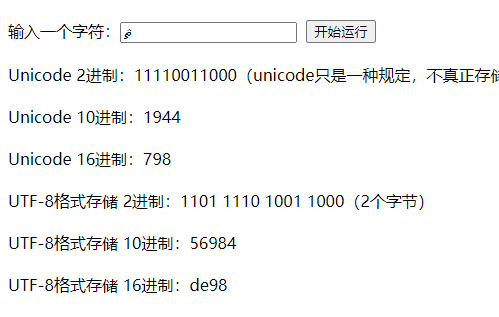
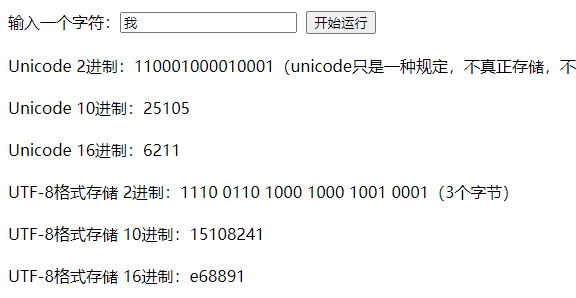
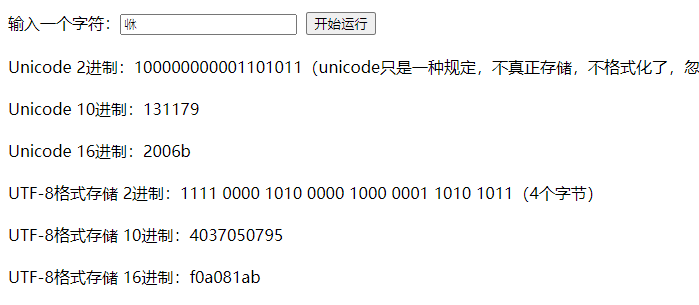
a 一个字节
ޘ,中东 伊朗那边的符号,伊斯兰拉丁符号,伊斯兰那些国家,主要是英文+扩展拉丁符号 2个字节,编辑器不太方便打出来,去网站上看吧
我,这个常用的中文字符,是3个字节
,不常用的中文字符更多,比如这个是4个字节
测试的结果如下:

==============================================================================================================
接下来聊一个问题,这个问题以后也可以用作 招聘
中文字符 utf8格式下 占几个字节,很多老师或教程上都是说 大多数中文字符 占3个字节,其实是不严谨的。当然还有很多更菜的菜鸟。
1. 首先我们看下unicode支持的 中文字符一共有多少个。我从网络找了一个数据,当然unicode也在不停的更新,会支持更多的中文字符。
引用:https://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php

我根据上图计算了下,目前unicode支持的中文字符一共95,055,其中 UTF8格式下 占3个字节的有,根据utf-8的格式(1110xxxx 10xxxxxx 10xxxxxx) 3个字节能表示的unicode的最大值为16个bit位都为1,16进制的话就是FFFF,所以小于4个F的
都是3个字节,大于4个F的是4个自己,比如5位16进制,那肯定是4个字节,由此得出,红框中的占4个字节,其它都是3个字节;
总结:unicode 中文字符一共95055,在UTF8格式存储下, 3个字节的字符数是29,244,4个字节字符数为65,811。所以应该说,utf8下 常用的字符都是3个字节,非常用的占4个字节,非常用的字符 是 常用的2倍多。
错误教学,大多数中文字符 占3个字节。应该是 【大多数“常用的”那么3万个左右,占3个字节】,其余的大多数都是4个字节;4个字节的中文字符比3个字节的多2倍。
============================================================================
很不错unicode查询网站,因为官网 https://home.unicode.org/,若要查看一个字符的二进制指定,比较麻烦,需要下载pdf。
好在有这样一个网站:https://unicode-table.com/ 方便查
ASCII、Unicode、UTF8 10年后,史无前例,自己用js实现《专题3》的更多相关文章
- 浅显总结ASCII Unicode UTF-8的区别
如果觉得此地排版不好,欢迎访问我的博客 浅显总结ASCII Unicode UTF-8的区别 制作表单时,为了追求更好的用户交互体验,常常会有提示性的内容,比如提醒用户字符的限制.由于英文,中文字符的 ...
- 字符编码 ASCII unicode UTF-8
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(b ...
- 【转】【编码】ANSI,ASCII,Unicode,UTF8之一
不同的国家和地区制定了不同的标准,由此产生了 GB2312.GBK.GB18030.Big5.Shift_JIS 等各自的编码标准.这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称 ...
- ASCII,unicode, utf8 ,big5 ,gb2312,gbk,gb18030等几种常用编码区别(转载)
原文出处:http://www.blogjava.net/xcp/archive/2009/10/29/coding2.html 最近老为编码问题而烦燥,下定决心一定要将其弄明白!本文主要总结网上一些 ...
- ASCII, UNICODE, UTF-8, 字符集理解
字符编码的发展历史 一个字节:最初一个字节的标准是混乱的,出现过4位.6位.7位的一字节标准,最终由于历史原因和物理存储需求(8位是2的3次方,方便物理存储),所以采用了8位为一个字节的标准. ASC ...
- ascii unicode utf-8 url编码
ascii 编码 计算机内部,所有信息最终都是一个二进制值 上个世纪60年代,美国制定了一套字符编码ascii ascii 编码就是定义:英语字符与二进制位之间的关系 unixcs unicode编码 ...
- 理解记忆三种常见字符编码:ASCII, Unicode,UTF-8
理解什么是字符编码? 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是25 ...
- 【转】关于字符编码,你所需要知道的(ASCII,Unicode,Utf-8,GB2312…)
转载地址:http://www.imkevinyang.com/2010/06/%E5%85%B3%E4%BA%8E%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81%EF%BC ...
- 关于字符编码,你所需要知道的(ASCII,Unicode,Utf-8,GB2312…)
字符编码的问题看似很小,经常被技术人员忽视,但是很容易导致一些莫名其妙的问题.这里总结了一下字符编码的一些普及性的知识,希望对大家有所帮助. 还是得从ASCII码说起 说到字符编码,不得不说ASCII ...
- 字符编码:ASCII,Unicode,UTF-8
1.ASCII码美国制定的一套字符编码,对英语字符和二进制位之间的关系,做了统一规定.ASCII码一共规定了128个字符(包括32个不能打印出来的控制符号)的编码,占用一个字节,字节的最前面1位统一为 ...
随机推荐
- 【驱动】SPI驱动分析(二)-SPI驱动框架
SPI驱动框架 SPI驱动属于总线-设备-驱动模型的,与I2C总线设备驱动模型相比,大体框架是一样,他们都是实际的总线.总体框架如下图所示: 从上到下,分为三层,用户空间,内核空间,和硬件层. 用户空 ...
- P1216-DP【橙】
在这道题中,我第一次用了memset,确实方便,不过需要注意的是只有全部赋值-1和0的时候才能使用它,否则他能干出吓死人的事.以及memset在cstring头文件里,在本地就算不include也能照 ...
- C#使用迭代器显示公交车站点
public static IList<object> items = new List<object>();//定义一个泛型对象,用于存储对象 /// <summary ...
- bitcask论文翻译/笔记
翻译 论文来源:bitcask-intro.pdf (riak.com) 背景介绍 Bitcask的起源与Riak分布式数据库的历史紧密相连.在Riak的K/V集群中,每个节点都使用了可插拔的本地存储 ...
- -- spi flash 擦除接口调用HAL库不同函数的区别
[描述] 在使用STM32F429操作W25Q128时,为验证flash工作正常,做简单的读写数据校验,在擦除接口中使用 HAL_SPI_Transmit 方法一直工作异常,使用 HAL_SPI_Tr ...
- [转帖]Linux 页表、大页与透明大页
一. 内存映射与页表 1. 内存映射 我们通常所说的内存容量,指的是物理内存,只有内核才可以直接访问物理内存,进程并不可以. Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间 ...
- [转帖]Nginx(3):上手Nginx,从配置文件开始
https://cloud.tencent.com/developer/article/1886147?areaSource=&traceId= 其实吧,我配置 tcp 负载均衡的时候也就 ...
- Linux无头模式使用mat分析dump的方法
摘要 mat可以很好的进行jvm的内存dump的分析. 但是大部分服务器是没有GUI界面的. 而且就算是有GUI界面也很难直接使用. 但是随着jvm堆区越来越大. WindowsPC机器已经很难进行分 ...
- Linux查找当前目录下包含部分内容的文件,并且copy到指定路径的简单方法
1 获取文件列表 find . -name "*.data" |xargs grep -i 'yearvariable' | uniq | awk '{print $1}' |cu ...
- uni-app中使用map
uni-app中使用地图显示当前的位置 我们现在的需求是,显示用户在地图上所处的位置. 有的小伙伴可能会说,这个是不是需要接入第三方的地图. 其实是不需要的,从目前这个需求来看. 我们只需要引入uni ...