使用阿里canal实现mysql与Elasticsearch增量同步
一、背景介绍
最近在做一个地理信息相关的项目,需要维护大量的地址描述数据,同时需要提供对数据检索的功能,准备采用Elasticsearch(6.7)实现。那么问题就来了,地址数据需要同时在MySQL和ES中维护,如果通过代码层面实现会增加代码量也不易维护,权衡之下决定使用阿里的Canal中间件来实现,留念备查。
Canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,工作原理是伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。同时支持客户端数据落地的适配功能,目前支持关系型数据库的数据同步、HBase的数据同步和ElasticSearch多表数据同步。
二、环境准备
1、MySQL数据库安装;
2、Elasticsearch安装;
3、Canal Server安装及配置,参考https://github.com/alibaba/canal/wiki/QuickStart;
4、Canal Client Adapter安装,参考https://github.com/alibaba/canal/wiki/ClientAdapter;
三、Canal Server配置instance
1、在canal server安装目录下找到/conf/canal.properties,在canal.destinations配置项中增加一个instance,我这里配置的是es-address-original
1 #################################################
2 ######### destinations #############
3 #################################################
4 canal.destinations = es-address-original
2、在/conf目录下创建es-address-original文件夹,并创建instance.properties文件,大家可以直接复制conf目录下的example目录进行修改,主要配置参数如下,其它参考自行参考官方文档
# MySQL数据库连接信息
canal.instance.master.address=192.168.x.x:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8 # mysql 数据解析关注的表,Perl正则表达式
# 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
# 常见例子:
# 1. 所有表:.* or .*\\..*
# 2. canal schema下所有表: canal\\..*
# 3. canal下的以canal打头的表:canal\\.canal.*
# 4. canal schema下的一张表:canal\\.test1
# 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
canal.instance.filter.regex=address-platform\\.address_original
四、Canal Adapter配置
client-adapter分为适配器和启动器两部分, 适配器为多个fat jar, 每个适配器会将自己所需的依赖打成一个包, 以SPI的方式让启动器动态加载, 目前所有支持的适配器都放置在plugin目录下
1、在canal adapter的conf目录下找到application.yml配置文件(根据官方介绍启动器为SpringBoot项目)
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null canal.conf:
mode: tcp # 客户端模式 tcp or kafka or rocketMQ
canalServerHost: 127.0.0.1:11111 # canal server address
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500 # 每次获取数据的批大小,单位为K
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数,-1为无限重试
timeout: # 同步超时时间,单位为毫秒
accessKey:
secretKey:
srcDataSources: # 源数据库
defaultDS:
url: jdbc:mysql://192.168.0.201:3306/address-platform?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: es-address-original # canal instance Name or mq topic name对应canal server中配置的instance名称
groups:
- groupId: g1
outerAdapters:
-
key: addressOriginalKey
name: es
hosts: 192.168.x.x:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # transport or rest
# # security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # ES集群名称
2、/conf/es下新增配置文件,文件名随意,配置内容如下
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
outerAdapterKey: addressOriginalKey # 对应application.yml中es配置的key
destination: es-address-original # cannal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: address_original # es 的索引名称
_type: _doc # es 的type名称, es7下无需配置此项
_id: id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
upsert: true
# pk: id
sql: "select a.ID as id, a.ADDRESS as address, a.SERIAL_NO as serial_no from address_original a" # sql映射,注意区分表字段和索引字段大小写
# objFields:
# _labels: array:;
# etlCondition: "where a.c_time>={}" # etl 的条件参数
commitBatch: 3000 # 提交批大小
3、创建ES索引信息,通过postman请求ES服务器http://192.168.x.x:9200/address_original,address_original是索引的名称,请求方式为PUT,参数类型为raw(json)
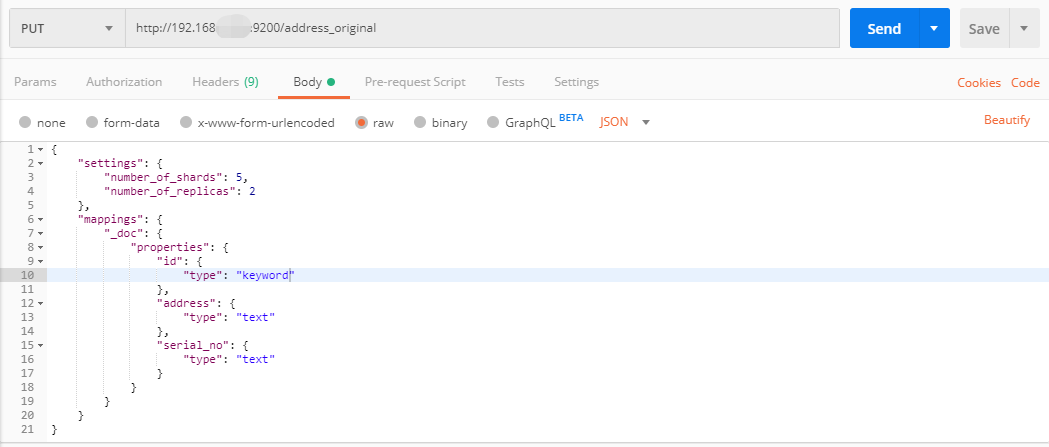
4、这里有几个坑注意一下:
1)canal适配器会通过GET http://192.168.x.x:9200/address_original/_mapping的方式读取es mapping,如果创建索引的时候没有配置mappings信息,会报Not found the mapping info of index异常;
2)测试的时候表字段名是大写,es索引字段名称小写,抛了空指针异常没有具体的异常描述,后来将/canal adapter/conf/es目录中的配置文件sql配置项采用别名统一小写后解决,这里推测数据库表与索引映射名称区分大小写的,后面再看看源码求证一下;
五、运行测试
1、在MySQL数据库address_original表中维护数据(增删改);
2、观察canal adapter日志;
六、运行结果
索引文档结果会根据数据库操作同步更新

使用阿里canal实现mysql与Elasticsearch增量同步的更多相关文章
- 转载:阿里canal实现mysql binlog日志解析同步redis
from: http://www.cnblogs.com/duanxz/p/5062833.html 背景 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求.不过早期的数 ...
- alibaba/canal 阿里巴巴 mysql 数据库 binlog 增量订阅&消费组件
基于日志增量订阅&消费支持的业务: 数据库镜像 数据库实时备份 多级索引 (卖家和买家各自分库索引) search build 业务cache刷新 价格变化等重要业务消息 项目介绍 名称:ca ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- canal 实现Mysql到Elasticsearch实时增量同步
简介: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
- mysql 与elasticsearch实时同步常用插件及优缺点对比(ES与关系型数据库同步)
前言: 目前mysql与elasticsearch常用的同步机制大多是基于插件实现的,常用的插件包括:elasticsearch-jdbc, elasticsearch-river-MySQL , g ...
- logstash-input-jdbc实现mysql 与elasticsearch实时同步(ES与关系型数据库同步)
引言: elasticsearch 的出现使得我们的存储.检索数据更快捷.方便.但很多情况下,我们的需求是:现在的数据存储在mysql.oracle等关系型传统数据库中,如何尽量不改变原有数据库表结构 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第五篇:logstash-input-jdbc实现mysql 与elasticsearch实时同步深入详解
文章转载自: https://blog.csdn.net/laoyang360/article/details/51747266 引言: elasticsearch 的出现使得我们的存储.检索数据更快 ...
- 用solr DIH 实现mysql 数据定时,增量同步到solr
基础环境: (二)设置增量导入为定时执行的任务: 很多人利用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题. 但 ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
随机推荐
- ASR项目实战-交付团队的分工
对于通常的软件项目,参与角色,比如可以有用户,消费者,产品团队,研发团队(研发团队包括开发和测试),运营团队,运维团队,管理团队. 通常认为,用户,负责购买服务的群体,而消费者,负责使用业务的群体.这 ...
- ElasticSearch之Exists API
检查指定名称的索引是否存在. 命令样例如下: curl -I "https://localhost:9200/testindex_002?pretty" --cacert $ES_ ...
- Springboot3核心特性
一.简介 1. 前置知识 Java17 Spring.SpringMVC.MyBatis Maven.IDEA 2. 环境要求 环境&工具 版本(or later) SpringBoot 3. ...
- CentOS 7 部署 Seafile 服务器(使用 MySQL/MariaDB)
本文档用来说明通过预编译好的安装包来安装并运行基于 MySQL/MariaDB 的 Seafile 服务器.(MariaDB 是 MySQL 的分支) 提示:如果您是初次部署 Seafile 服务,我 ...
- Python汉诺塔递归算法实现
关于用递归实现的原理,请查看我之前的文章: C语言与汉诺塔 C#与汉诺塔 以下为代码: count = 0 def move(pile, src, tmp, dst): global count if ...
- 如何开发一个ORM数据库框架
如何开发一个ORM框架 ORM(Object Relational Mapping)对象关系映射,ORM的数据库框架有hibernate,mybatis.我该如何开发一个类似这样的框架呢? 为什么会有 ...
- Prometheus 监控告警系统搭建(对接飞书告警)
Prometheus 是一套开源的系统监控报警框架,非常适合大规模集群的监控.它也是第二个加入CNCF的项目,受欢迎度仅次于 Kubernetes 的项目.本文讲解完整prometheus 监控和告警 ...
- Windows中开启自动dump的方法
@echo off echo 正在启用Dump... reg add "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\Windows Error ...
- 物联网SIM卡和SIM卡真的不是一回事
办卡吗,兄弟? 物联网卡?相信大家第一反应都是一愣.大家听过银行卡.电话SIM卡.会员卡-等等,很多人可能都是第一次听说物联网卡.那它到底是个什么东东?它能干什么呢?今天就带大家一探究竟. 那在物联网 ...
- 常用的echo和cat,这次让我折在了特殊字符丢失问题上
摘要:用过linux的都知道,echo和cat是我们常用的展示内容和写入内容的方式. 本文分享自华为云社区<echo和cat,重定向到文件时,解决特殊字符丢失问题>,作者: 大金(内蒙的) ...