SimCLR: 一种视觉表征对比学习的简单框架《A Simple Framework for Contrastive Learning of Visual Representations》(对比学习、数据增强算子组合,二次增强、投影头、实验细节很nice),好文章,值得反复看
现在是2024年5月18日,好久没好好地看论文了,最近在学在写代码+各种乱七八糟的事情,感觉要和学术前沿脱轨了(虽然本身也没在轨道上,太菜了),今天把师兄推荐的一个框架的论文看看(视觉CV领域的)。
20:31,正经的把这篇论文看完。
论文:A Simple Framework for Contrastive Learning of Visual Representations
或者是:A simple framework for contrastive learning of visual representations
GitHub:https://github.com/google-research/simclr
ICML 2020的论文。
(为什么看这篇论文呢?因为要做实验,哈哈哈哈哈哈哈哈哈.)
(声明,我看的时候是看的英文原文,写博士是直接整段翻译器翻译的,偶尔会调一下翻译不合适的地方.)
摘要
本文介绍了 SimCLR:一个用于视觉表征对比学习的简单框架。我们简化了最近提出的对比自监督学习算法,而不需要专门的架构或内存库。为了了解是什么让对比预测任务能够学习有用的表征,我们系统地研究了我们框架的主要组成部分。我们的研究表明:(1) 数据增强的组成在定义有效的预测任务中起着至关重要的作用;(2) 在表征和对比损失之间引入可学习的非线性变换能大幅提高所学表征的质量;(3) 与监督学习相比,对比学习能从更大的批量规模和更多的训练步骤中获益。综合这些发现,我们在 ImageNet 上的自监督和半监督学习方法大大优于以往的方法。在 SimCLR 学习的自监督表示法上训练的线性分类器达到了 76.5% 的 top-1 准确率,比以前的技术水平相对提高了 7%,与监督 ResNet-50 的性能不相上下。当仅对 1%的标签进行微调时,我们的前五名准确率达到了 85.8%,超过了标签数量少 100 倍的 AlexNet。
1. 引言
(20:56,开溜,先回寝室收拾卫生了,现在学不进去,好累,先占个坑,明天写.)
(现在是2024年5月19日,14:09,星期日,来实验室摸鱼了,把这篇论文看了,现在是14:09.)
在没有人类监督的情况下学习有效的视觉表征是一个长期存在的问题。大多数主流方法分为两类:生成法和判别法。生成式方法学习生成输入空间中的像素或以其他方式对其进行建模(Hinton 等人,2006 年;Kingma 和 Welling,2013 年;Goodfellow 等人,2014 年)。
然而,像素级生成的计算成本很高,对于表征学习可能并非必要。判别方法使用与监督学习类似的目标函数来学习表征,但训练网络执行借口任务,其中输入和标签均来自无标签数据集。许多此类方法都依赖启发式方法来设计借口任务(Doersch 等人,2015 年;Zhang 等人,2016 年;Noroozi & Favaro,2016 年;Gidaris 等人,2018 年),这可能会限制所学表征的通用性。基于潜空间对比学习的判别方法最近显示出巨大的前景,取得了一流的成果(Hadsell 等人,2006 年;Dosovitskiy 等人,2014 年;Oord 等人,2018 年;Bachman 等人,2019 年)。
在这项工作中,我们引入了一个简单的视觉表征对比学习框架,我们称之为 SimCLR。SimCLR 不仅优于之前的工作(图 1),而且更简单,既不需要专门的架构(Bachman 等人,2019 年;Hénaff 等人,2019 年),也不需要记忆库(Wu 等人,2018 年;Tian 等人,2019 年;He 等人,2019 年;Misra & van der Maaten,2019 年)。
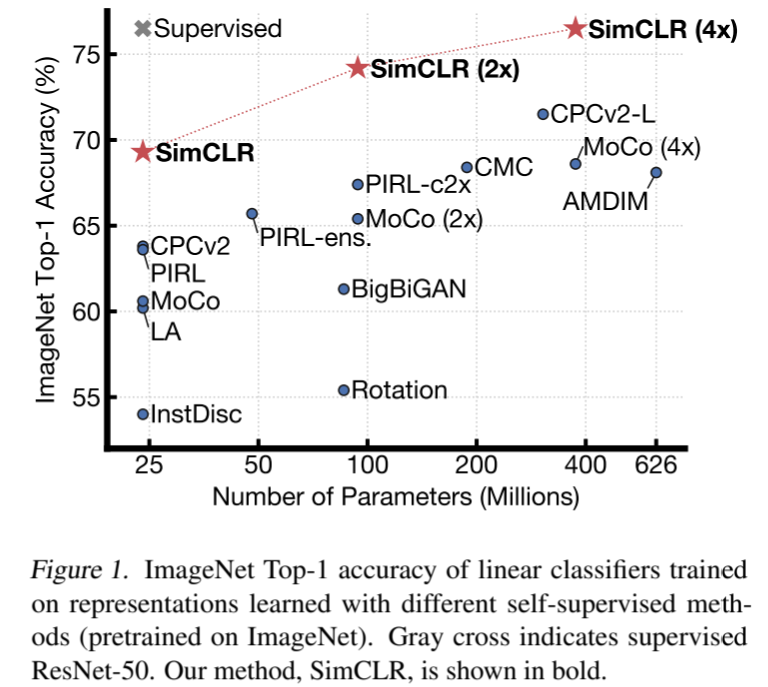
图 1. 使用不同自监督方法(在 ImageNet 上进行预训练)学习的表征训练的线性分类器的 ImageNet Top-1 准确率。灰色交叉表示有监督的 ResNet-50。我们的方法 SimCLR 以粗体显示。
为了了解是什么促成了良好的对比表征学习,我们系统地研究了我们框架的主要组成部分,结果表明(建议复诵,有用,哈哈哈哈哈哈哈哈哈):
- 多种数据增强操作的组合对于确定产生有效表征的对比预测任务至关重要。此外,与有监督学习相比,无监督对比学习受益于更强的数据增强。
- 在表征和对比损失之间引入可学习的非线性变换,可大幅提高所学表征的质量。
- 使用对比交叉熵损失进行表征学习,可以从归一化嵌入和适当调整的温度参数中获益。
- 与监督学习相比,对比学习受益于更大的批量和更长的训练时间。与监督学习一样,对比学习受益于更深更广的网络。
我们结合这些发现,在 ImageNet ILSVRC-2012 (Russakovsky et al.) 在线性评估协议下,SimCLR达到了76.5%的top-1准确率,比之前的先进水平相对提高了7%(Hénaff等人,2019)。当仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 的前五名准确率达到 85.8%,相对提高了 10%(Hénaff 等人,2019 年)。在其他自然图像分类数据集上进行微调时,SimCLR 在 12 个数据集中的 10 个数据集上的表现与强监督基线(Kornblith 等人,2019 年)相当或更好。
2. 方法
2.1 对比学习框架
受近期对比学习算法的启发(概述见第 7 节),SimCLR 通过潜在空间中的对比损失,最大化同一数据实例的不同增强视图之间的一致性,从而学习表征。如图 2 所示,该框架由以下四个主要部分组成。
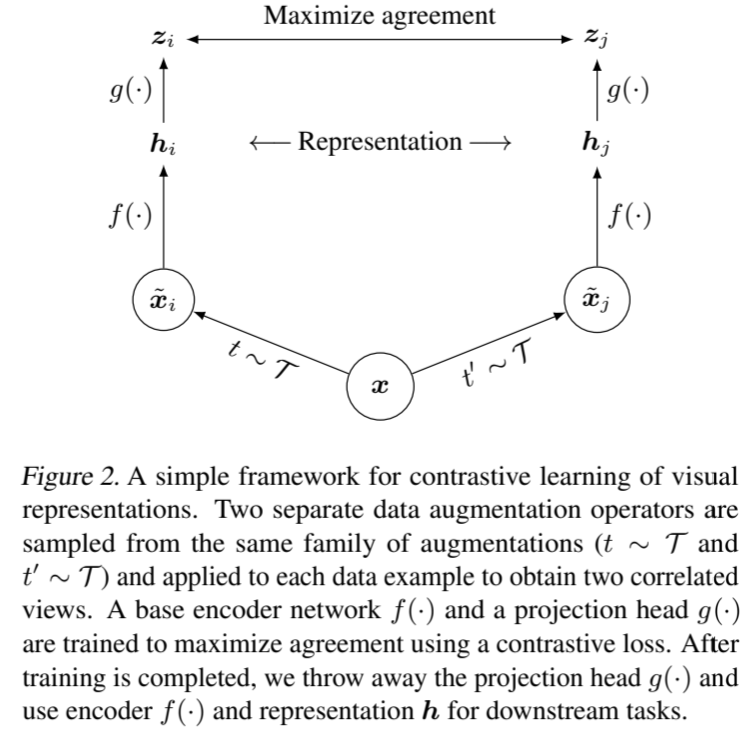
图 2. 视觉表征对比学习的简单框架。两个独立的数据增强算子从相同的增强系列(t ∼ T 和 t ∼ T)中采样,并应用于每个数据示例,以获得两个相关的视图。基础编码器网络 f (-) 和投影头 g(-) 经过训练,使用对比损失最大化一致性。训练完成后,我们丢弃投影头 g(-),使用编码器 f (-) 和表示法 h 完成下游任务。
- 随机数据增强模块:随机转换任何给定的数据示例,从而产生同一示例的两个相关视图,分别表示为 x˜ i 和 x˜ j,我们将其视为一对正对视图。在这项工作中,我们依次应用了三种简单的增强技术:随机裁剪并调整为原始大小、随机色彩失真和随机高斯模糊。如第 3 节所示,随机裁剪和色彩失真的组合对于实现良好的性能至关重要。
- 神经网络基础编码器 f (-) 可从增强数据示例中提取表示向量。我们的框架允许在没有任何限制的情况下选择不同的网络架构。我们选择简单的方法,采用常用的 ResNet(He 等人,2016 年),得到 h i = f(x˜ i ) = ResNet(x˜ i ) ,其中 h i∈ R d 是平均池化层后的输出。
- 一个小型神经网络投影头 g(-),可将表征映射到应用对比损失的空间。我们使用一个有一个隐藏层的 MLP,得到 z i = g(h i ) = W (2) σ(W (1) h i ) ,其中 σ 是 ReLU 非线性。如第 4 节所示,我们发现在 z i 而不是 h i 上定义对比损失是有益的。
- 为对比预测任务定义的对比损失函数。给定一个包含一对正例 x˜ i 和 x˜ j 的集合 {x˜ k },对比预测任务的目的是针对给定的 x˜ i 在 {x˜ k } k =i 中识别出 x˜ j。
我们随机抽取 N 个示例的小批量样本,并对小批量样本中的成对增强示例定义对比预测任务,从而得到 2N 个数据点。我们不会明确抽取负面示例。取而代之的是,在给定一对正例的情况下,类似于(Chen 等人,2017 年),我们将迷你批中的其他 2(N - 1) 个增强示例视为负例。让 sim(u, v) = u v/ u v 表示两个归一化的 u 和 v 之间的点积(即余弦相似度)。那么一对正例 (i, j) 的损失函数定义为
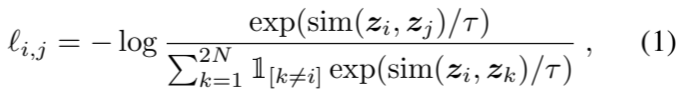
其中,[k =i] ∈ {0, 1} 是一个指标函数,如果 k = i,其值为 1,τ 表示温度参数。最终损失是在一个迷你批次中对所有正对(i, j)和(j, i)计算得出的。这一损失已在之前的工作中使用过(Sohn,2016;Wu 等人,2018;Oord 等人,2018);为方便起见,我们称之为 NT-Xent(归一化温度标度交叉熵损失)。

算法 1 概述了所提出的方法。
2.2. 大批量训练
为了简单起见,我们不使用记忆库训练模型(Wu 等人,2018;He 等人,2019)。相反,我们将训练批次大小 N 从 256 调整为 8192。批量大小为 8192 时,我们可以从两个增强视图中获得每对正例 16382 个负例。在使用具有线性学习率缩放的标准 SGD/Momentum 时,大批次的训练可能会不稳定(Goyal 等人,2017 年)。为了稳定训练,我们对所有批次规模都使用了 LARS 优化器(You 等人,2017 年)。我们使用云 TPU 训练模型,根据批量大小使用 32 到 128 个内核。2 全局 BN。标准 ResNets 使用批次归一化(Ioffe & Szegedy,2015 年)。在具有数据并行性的分布式训练中,BN 的均值和方差通常在每个设备的本地汇总。在我们的对比学习中,由于正对是在同一设备中计算的,因此模型可以利用本地信息泄漏来提高预测准确性,而无需改进表征。我们通过在训练过程中汇总所有设备的 BN 均值和方差来解决这一问题。其他方法包括跨设备洗牌数据示例(He 等人,2019 年),或者用层规范取代 BN(Hénaff 等人,2019 年)。
2.3. 评估协议
在此,我们列出了实证研究的协议,旨在了解我们框架中的不同设计选择。
数据集和指标。我们对无监督预训练(在没有标签的情况下学习编码器网络 f)的大部分研究都是使用 ImageNet ILSVRC-2012 数据集完成的(Russakovsky 等人,2015 年)。在 CIFAR-10 数据集(Krizhevsky & Hinton,2009 年)上进行的其他预训练实验见附录 B.9。我们还在大量数据集上测试了预训练结果,以进行迁移学习。为了评估学习到的表征,我们遵循了广泛使用的线性评估协议(Zhang 等人,2016;Oord 等人,2018;Bachman 等人,2019;Kolesnikov 等人,2019),即在冻结的基础网络之上训练线性分类器,并将测试准确率作为表征质量的代表。除了线性评估外,我们还将半监督学习和迁移学习与最先进的技术进行了比较。默认设置。除非另有说明,我们使用随机裁剪和调整大小(随机翻转)、色彩失真和高斯模糊(详见附录 A)来增强数据。我们使用 ResNet-50 作为基础编码器网络,并使用 2 层 MLP 投影头将表示投射到 128 维潜在空间。我们使用 NT-Xent 作为损失,并使用 LARS 进行优化,学习率为 4.8(= 0.3 × BatchSize/256),权重衰减为 10 -6。我们以 4096 的批量大小进行 100 次训练。3 此外,我们在前 10 个 epoch 中使用线性预热,并使用余弦衰减计划衰减学习率,而不重新开始(Loshchilov & Hutter,2016 年)。
(现在16:26,断断续续有事情,现在要去拆服务器机器修显卡了,哈哈哈哈哈哈,果然学计算机的最终都是修电脑的,告辞.)
(现在是20:28,浪回来了,吃了饭,一边吃清补凉一边看论文吧,哈哈哈哈哈哈哈哈哈哈.)
3. 用于对比表征学习的数据增强
数据增强定义了预测任务。虽然数据增强已被广泛应用于有监督和无监督表征学习中(Krizhevsky 等人,2012;Hénaff 等人,2019;Bachman 等人,2019),但它尚未被视为定义对比预测任务的系统方法。许多现有方法通过改变架构来定义对比预测任务。例如,Hjelm 等人(2018 年);Bachman 等人(2019 年)通过限制网络架构中的感受野实现了全局到局部视图预测,而 Oord 等人(2018 年);Hénaff 等人(2019 年)则通过固定的图像分割程序和上下文聚合网络实现了邻近视图预测。我们的研究表明,可以通过对目标图像进行简单的随机裁剪(调整大小)来避免这种复杂性,从而创建一个包含上述两种预测任务的预测任务系列,如图 3 所示。这种简单的设计选择方便地将预测任务与神经网络架构等其他组件分离开来。通过扩展增强系列并随机组合它们,可以定义更广泛的对比预测任务。

图 3 实线矩形为图像,虚线矩形为随机裁剪。通过随机裁剪图像,我们对包括全局视图到局部视图(B → A)或相邻视图(D → C)预测在内的对比预测任务进行了抽样。
3.1. 数据增强操作的组合对学习良好的表征至关重要
为了系统地研究数据增强的影响,我们在此考虑了几种常见的增强操作。一种扩增涉及数据的空间/几何转换,如裁剪和调整大小(水平翻转)、旋转(Gidaris 等人,2018 年)和剪切(DeVries & Taylor,2017 年)。另一类扩增涉及外观变换,如颜色变形(包括掉色、亮度、对比度、饱和度、色调)(Howard,2013;Szegedy 等人,2015)、高斯模糊和索伯滤波。图 4 展示了我们在这项工作中研究的增强技术。

图 4. 所研究的数据增强算子示意图。每个增强算子都能利用一些内部参数(如旋转度、噪声水平)随机转换数据。请注意,我们只在消融中测试了这些算子,用于训练模型的增强策略只包括随机裁剪(翻转和调整大小)、色彩失真和高斯模糊。(原图抄送:Von.grzanka)
为了了解单个数据增强的效果以及增强组合的重要性,我们研究了单独或成对应用增强时框架的性能。由于 ImageNet 图像大小不一,我们总是对图像进行裁剪和调整大小(Krizhevsky 等人,2012 年;Szegedy 等人,2015 年),因此很难在不裁剪的情况下研究其他增强。为了消除这种干扰,我们考虑对这种消融进行非对称数据转换设置。具体来说,我们总是先随机裁剪图像并将它们调整到相同的分辨率,然后只对图 2 中框架的一个分支应用目标变换,而让另一个分支保持不变(即 t(x i ) = x i )。需要注意的是,这种非对称的数据增强会损害性能。不过,这种设置应该不会对单个数据增强或其组合的影响产生实质性改变。
图 5 显示了单独变换和组合变换下的线性评估结果。我们注意到,尽管模型在对比任务中几乎可以完美地识别出正对,但没有任何一种变换足以学习到良好的表征。当组合增强时,对比预测任务变得更加困难,但表征质量却显著提高。附录 B.2 提供了对组成更广泛的扩增集的进一步研究。(为什么非对称的数据增强会损害性能?)(组合增强的时候,是不是就是特征没那么明显,但是如果模型学的好的话,那么泛化能力应该很好.)
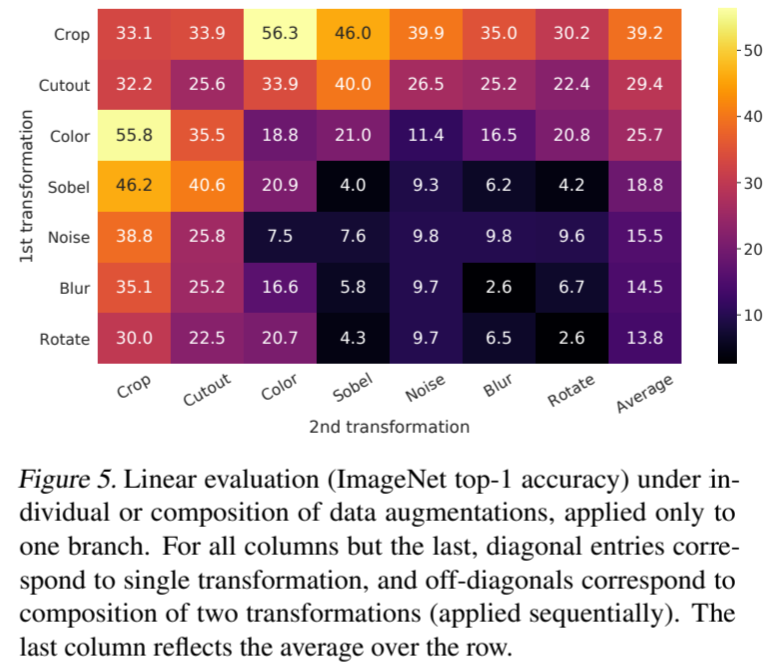
图 5. 在单独或组合数据增强(仅应用于一个分支)情况下的线性评估(ImageNet top-1 准确率)。除最后一列外的所有列,对角线条目对应的是单一变换,非对角线条目对应的是两种变换的组合(按顺序应用)。最后一列反映的是该行的平均值。
其中有一种增强方法比较突出:随机裁剪和随机颜色变形。我们推测,仅使用随机裁剪作为数据增强时的一个严重问题是,图像中的大多数斑块具有相似的颜色分布。图 6 显示,仅靠颜色直方图就足以区分图像。神经网络可能会利用这一捷径来解决预测任务。因此,为了学习可通用的特征,将裁剪与色彩失真结合起来至关重要。
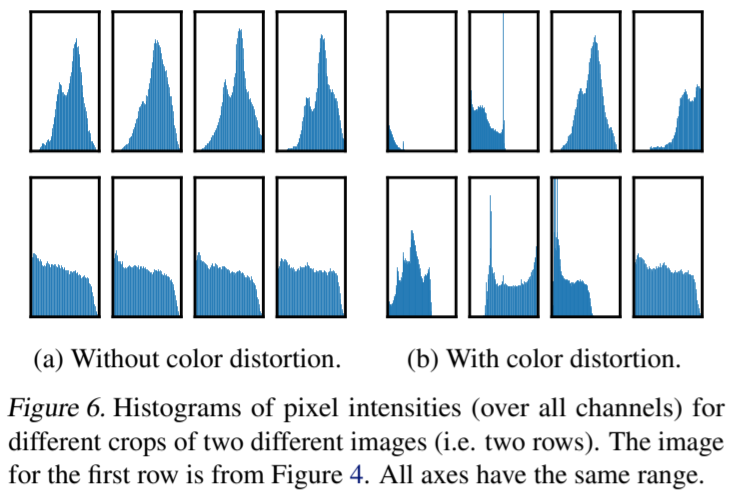
图 6. 两幅不同图像(即两行)的不同作物的像素强度(所有通道)直方图。第一行的图像来自图 4。所有坐标轴的范围相同。
(21;32,准备打印一下这篇论文,下班,呜呜呜,周日了,为什么我还在实验室...)
(现在是2024年5月20日,寡王只适合看论文摸鱼,现在是20:15,继续看这篇论文.)
3.2. 对比学习需要比监督学习更强的数据增强
为了进一步证明颜色增强的重要性,我们调整了颜色增强的强度,如表 1 所示。更强的颜色增强可以大大提高无监督学习模型的线性评估效果。在这种情况下,使用监督学习发现的复杂增强策略 AutoAugment(Cubuk 等人,2019 年)并不比简单裁剪+(更强的)色彩失真效果更好。在使用相同的增强集训练有监督模型时,我们发现更强的色彩增强并不能提高甚至会损害其性能。因此,我们的实验表明,与有监督学习相比,无监督对比学习可以从更强(颜色)的数据增强中获益。尽管以前的工作已经报道过数据增强对自我监督学习很有用(Doersch 等人,2015 年;Bachman 等人,2019 年;Hénaff 等人,2019 年;Asano 等人,2019 年),但我们的研究表明,对监督学习没有产生准确性益处的数据增强仍然对对比学习有很大帮助。
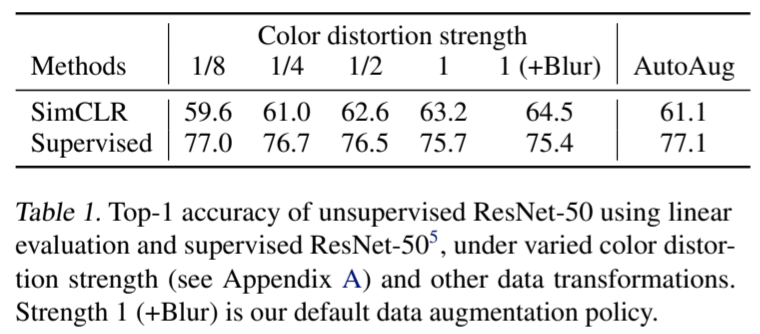
表 1. 在不同颜色失真强度(见附录 A)和其他数据转换条件下,使用线性评估的无监督 ResNet-50 和有监督 ResNet-50 5 的最高准确率。强度 1(+模糊)是我们的默认数据增强策略。
4. 编码器和头部的架构
4.1. 无监督对比学习从更大的模型中获益(更多)
图 7 显示,增加深度和宽度都能提高性能,这也许并不令人意外。虽然有监督学习也有类似的发现(He 等人,2016 年),但我们发现有监督模型与在无监督模型上训练的线性分类器之间的差距随着模型大小的增加而缩小,这表明与有监督学习相比,无监督学习从更大的模型中获益更多。
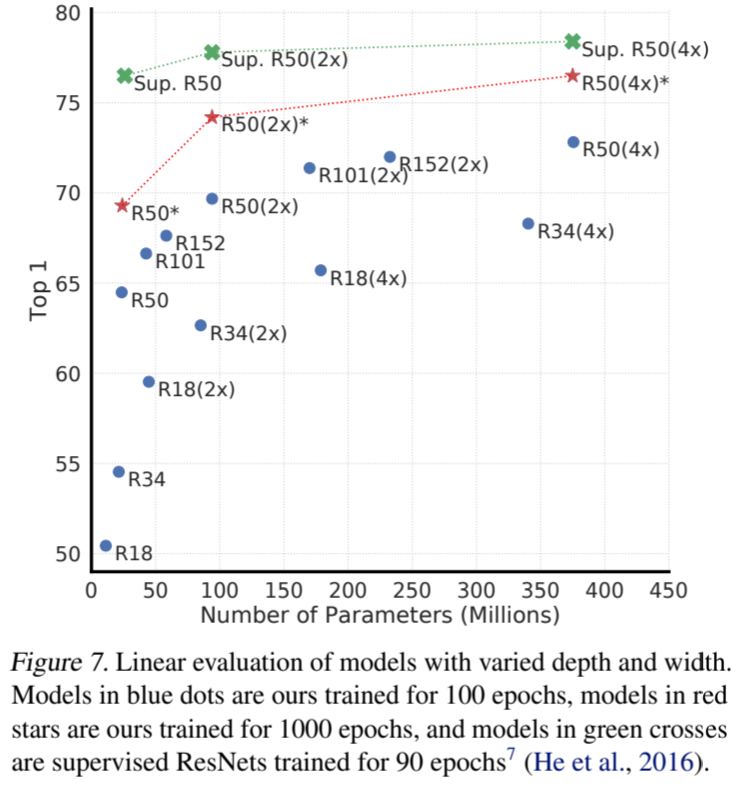
图 7. 不同深度和宽度模型的线性评估。蓝点中的模型是我们训练了 100 个历时的模型,红星中的模型是我们训练了 1000 个历时的模型,绿色十字中的模型是监督 ResNets 训练了 90 个历时的模型 7 (He 等人,2016 年)。
4.2. 非线性投影头提高了前一层的表征质量
我们接着研究了包含投影头(即 g(h))的重要性。图 8 显示了使用三种不同结构的投影头的线性评估结果:(1)身份映射;(2)线性投影,如之前几种方法所使用的(Wu 等人,2018 年);(3)默认的非线性投影,带有一个额外的隐藏层(和 ReLU 激活),类似于 Bachman 等人(2019 年)。我们观察到,非线性投影比线性投影好(+3%),比无投影好得多(>10%)。使用投影头时,无论输出维度如何,都能观察到类似的结果。此外,即使使用了非线性投影,投影头之前的层 h 仍然比投影头之后的层 z = g(h) 好得多(>10%),这表明投影头之前的隐藏层比投影头之后的隐藏层具有更好的代表性。(GPT解释:因为投影头的设计目标是为了辅助训练特征提取层,而不是直接用于下游任务。投影头的设计主要目的是为了在训练过程中增强特征学习的效果。在对比学习(如SimCLR)中,投影头通常用于将高维特征映射到一个低维空间,使得对比损失在这个空间中计算得更为有效。)投影头之后的特征(通常记作z=g(h)是专门为优化对比损失函数设计的。)
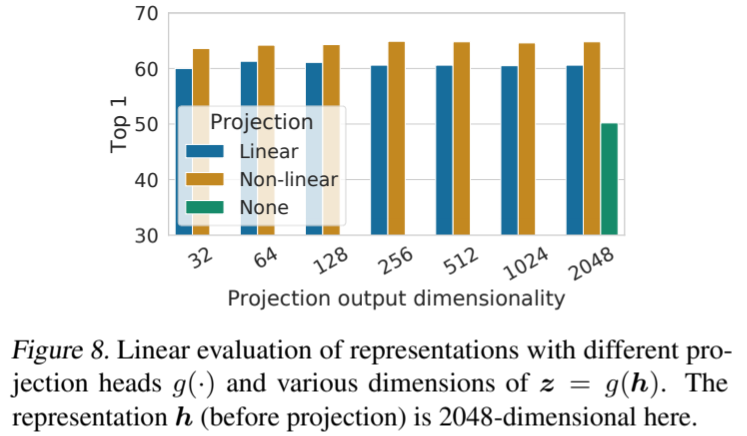
图 8. 对不同投影头 g(-) 和 z = g(h) 不同维度的表示进行线性评估。这里的表示 h(投影前)为 2048 维。
我们推测,使用非线性投影前的表征的重要性是由于对比损失引起的信息损失。特别是,z = g(h)经过训练后不会受到数据转换的影响。因此,g 可以去除对下游任务有用的信息,如物体的颜色或方向。为了验证这一假设,我们进行了实验,使用 h 或 g(h) 来学习预测预训练时应用的变换。在这里,我们设置 g(h) = W (2) σ(W (1) h),输入和输出维度相同(即 2048)。表 3 显示,h 包含了更多关于所应用变换的信息,而 g(h) 则丢失了更多信息。进一步分析见附录 B.4。
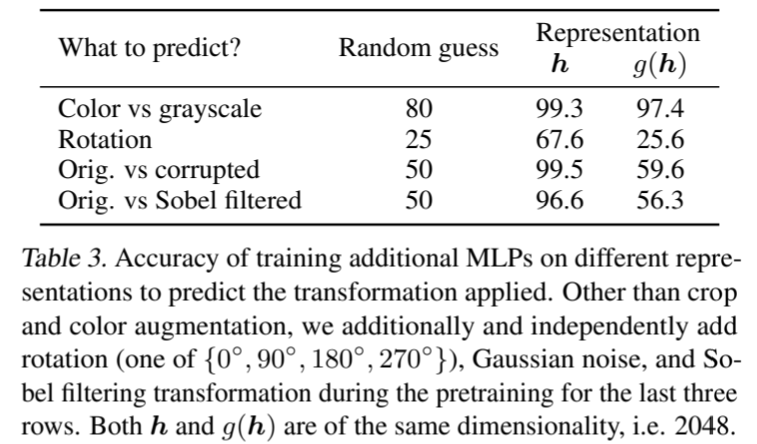
表 3. 在不同表征上训练额外 MLP 以预测所应用变换的准确率。除了裁剪和颜色增强外,我们还在最后三行的预训练过程中独立添加了旋转({0 ◦ , 90 ◦ , 180 ◦ , 270 ◦ }中的一种)、高斯噪声和索伯滤波变换。h 和 g(h) 的维度相同,即 2048。
5. 损失函数和批量大小
5.1. 带有可调温度的归一化交叉熵损失优于其他损失函数
我们将 NT-Xent 损失函数与其他常用的对比损失函数进行了比较,如 logistic 损失函数(Mikolov 等人,2013 年)和 margin 损失函数(Schroff 等人,2015 年)。表 2 显示了目标函数以及损失函数输入的梯度。通过观察梯度,我们可以发现:1)l2 归一化(即余弦相似度)和温度能有效地对不同实例进行加权,而适当的温度能帮助模型从困难负样本(难负样本)中学习;2)与交叉熵不同,其他目标函数并不能根据负样本的相对难度对其进行加权。因此,我们必须对这些损失函数进行半难负样本挖掘(Schroff 等人,2015 年):我们可以使用半难负样本项(即在损失边界内、距离较近但比正样本距离更远的负样本)来计算梯度,而不是计算所有损失项的梯度。

表 2. 负损失函数及其梯度。所有输入向量(即 u、v +、v -)均已 l2 归一化。NT-Xent 是 "归一化温度标度交叉熵 "的缩写。不同的损失函数对正样本和负样本施加不同的权重。
为了使比较公平,我们对所有损失函数使用了相同的 l2 归一化,并调整了超参数,报告了它们的最佳结果。表 4 显示,虽然(半难)负样本挖掘有帮助,但最佳结果仍然比我们的默认 NT-Xent 损失差很多。

表 4. 使用不同损失函数训练的模型的线性评估(top-1)。"sh "表示使用半难负样本挖掘。
接下来,我们测试了默认 NT-Xent 损失中 l2 归一化(即余弦相似度与点积)和温度 τ 的重要性。表 5 显示,如果不进行归一化和适当的温度缩放,性能会明显下降。在没有进行 l2 归一化的情况下,对比任务的准确性更高,但在线性评估中,结果表示更差。
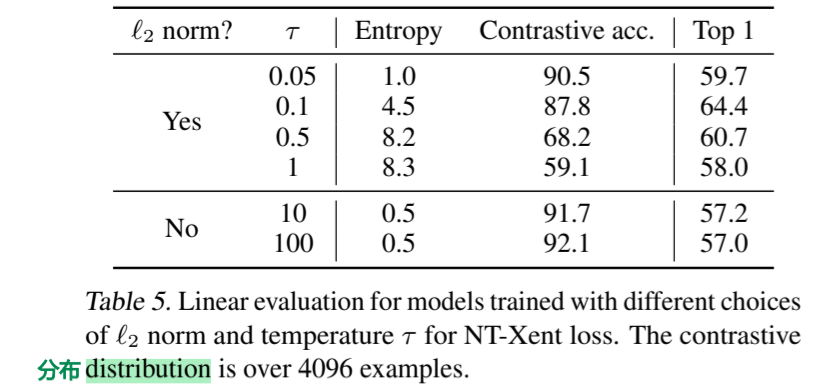
表 5. 对 NT-Xent loss 采用不同 l2 准则和温度 τ 所训练模型的线性评估。对比分布超过 4096 个实例。
(现在22:09,看得我头晕眼花,准备回寝室了.)
(现在是2024年5月21日,10:18,继续看.)
5.2. 对比学习从更大的批次和更长时间的训练中获益(更多)
图 9 显示了当模型训练的epochs不同时,批次(batch size)大小的影响。我们发现,当训练epochs数较少时(例如 100 个历元),较大的batch size比较小的batch size有明显优势。随着训练steps/epochs的增加,不同批次(batch size)大小之间的差距会缩小或消失,前提是这些批次(batches)是随机重采样的。与监督学习(Goyal 等人,2017 年)不同的是,在对比学习中,较大的batch size能提供更多的负样本,从而促进收敛(即用较少的epochs和steps就能获得给定的准确率)。更长时间的训练也能提供更多负样本,从而改善结果。附录 B.1 提供了训练steps更长的结果。
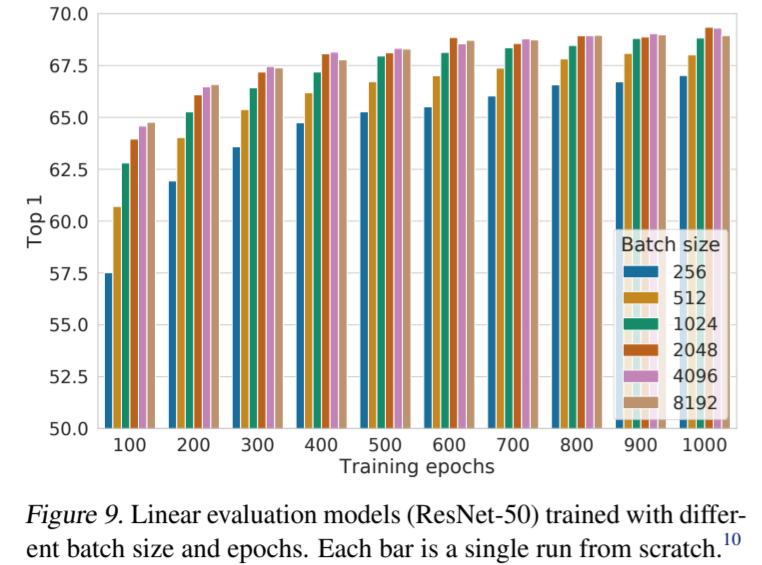
图 9. 使用不同batch size和epochs训练的线性评估模型(ResNet-50)。每个条形图都是一次从头开始的运行。
6. 与最先进技术的比较
在本小节中,与 Kolesnikov 等人(2019)、He 等人(2019)类似,我们使用了 3 种不同隐层宽度(宽度乘数分别为 1×、2× 和 4×)的 ResNet-50。为了更好地收敛,我们的模型训练了 1000 个历时。线性评估。表 6 比较了我们与之前的方法(Zhuang 等人,2019;He 等人,2019;Misra & van der Maaten,2019;Hénaff 等人,2019;Kolesnikov 等人,2019;Donahue & Simonyan,2019;Bachman 等人,2019;Tian 等人,2019)在线性评估设置下的结果(见附录 B.6)。表 1 显示了不同方法之间的更多数值比较。与之前需要专门设计架构的方法相比,我们能够使用标准网络获得更好的结果。使用我们的 ResNet-50 所获得的最佳结果(4×)可以与经过监督预训练的 ResNet-50 相媲美。
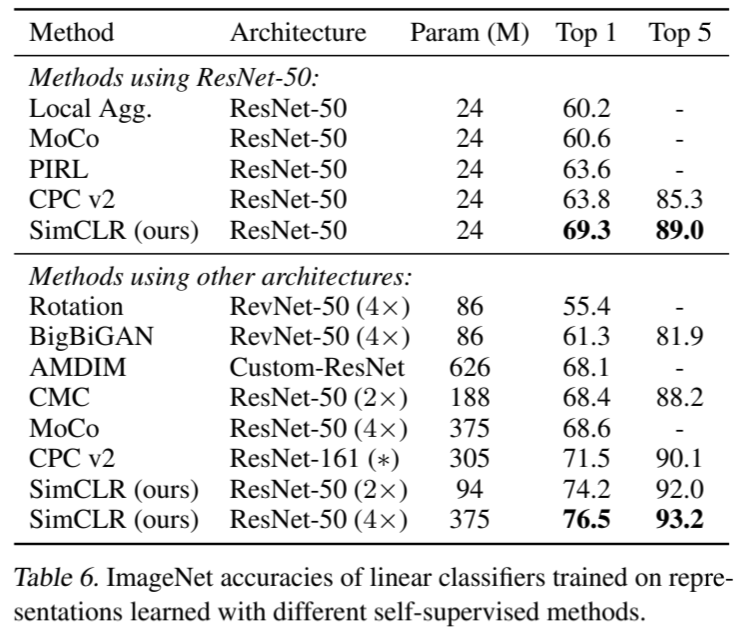
表 6. 使用不同自监督方法学习的表征训练的线性分类器的 ImageNet 准确率。
半监督学习。我们效仿Zhai等人(2019)的做法,以类平衡的方式从已标注的 ILSVRC-12 训练数据集中抽取 1%或 10%的样本(每类分别抽取 ∼12.8 和 ∼128 幅图像)。我们只需在标注数据上对整个基础网络进行微调,无需正则化(见附录 B.5)。表 7 显示了我们的结果与最新方法的比较(Zhai 等人,2019;Xie 等人,2019;Sohn 等人,2020;Wu 等人,2018;Donahue & Simonyan,2019;Misra & van der Maaten,2019;Hénaff 等人,2019)。由于对超参数(包括增强参数)进行了深入搜索,Zhai等人,2019)的监督基线非常强大。同样,我们的方法在使用1%和10%的标签时都明显优于最先进的方法。有趣的是,在完整 ImageNet 上微调我们预训练的 ResNet-50(2×、4×)也明显优于从头开始训练(最高达 2%,见附录 B.2)。
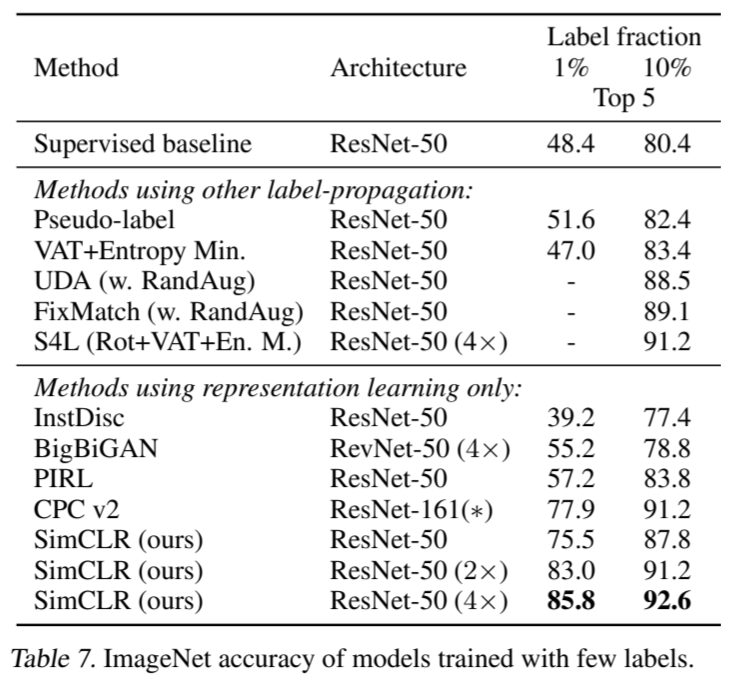
表 7. 使用少量标签训练的模型的 ImageNet 准确率。
迁移学习。我们在线性评估(固定特征提取器)和微调设置中评估了 12 个自然图像数据集的迁移学习性能。按照 Kornblith 等人(2019 年)的做法,我们对每个模型-数据集组合进行超参数调整,并在验证集上选择最佳超参数。表 8 显示了 ResNet-50 (4×) 模型的结果。经过微调后,我们的自监督模型在 5 个数据集上的表现明显优于监督基线,而监督基线仅在 2 个数据集(即宠物和花卉)上表现较好。在其余 5 个数据集上,模型在统计上打成平手。附录 B.8 提供了完整的实验细节以及标准 ResNet-50 架构的结果。
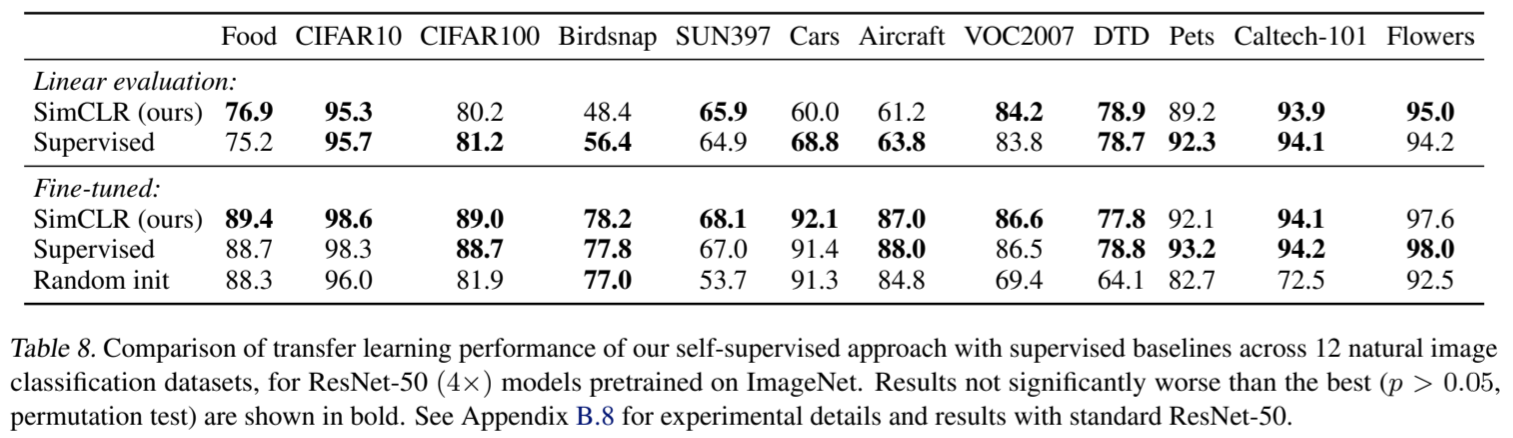
表 8. 在 12 个自然图像分类数据集上,对于在 ImageNet 上预处理过的 ResNet-50 (4×) 模型,我们的自监督方法与监督基线的迁移学习性能比较。不明显劣于最佳结果(P > 0.05,置换检验)的结果以粗体显示。有关标准 ResNet-50 的实验细节和结果,请参见附录 B.8。
7. 相关工作
让图像表征在微小变换下相互一致的想法可以追溯到 Becker 和 Hinton(1992 年)。我们利用最近在数据增强、网络架构和对比损失方面取得的进展对其进行了扩展。在半监督学习等其他场合,我们也探索过类似的一致性想法,但仅限于类标签预测(Xie 等人,2019;Berthelot 等人,2019)。
手工制作的借口任务。最近自我监督学习的复兴始于人工设计的借口任务,如相对补丁预测(Doersch 等人,2015 年)、解拼图(Noroozi & Favaro,2016 年)、着色(Zhang 等人,2016 年)和旋转预测(Gidaris 等人,2018 年;Chen 等人,2019 年)。虽然通过更大的网络和更长时间的训练可以获得良好的结果(Kolesnikov 等人,2019 年),但这些借口任务依赖于一些临时的启发式方法,这限制了所学表征的通用性。
对比视觉表征学习。这些方法可以追溯到 Hadsell 等人(2006 年)的研究,通过对比正对与反对来学习表征。按照这一思路,Dosovitskiy 等人(2014 年)提出将每个实例视为一个由特征向量(参数形式)表示的类。Wu 等人(2018)提出使用记忆库来存储实例类表示向量,最近的几篇论文(Zhuang 等人,2019;Tian 等人,2019;He 等人,2019;Misra & van der Maaten,2019)采用并扩展了这种方法。其他工作则探讨了使用批内样本代替记忆库进行负采样(Doersch & Zisserman, 2017; Ye et al., 2019; Ji et al., 2019)。
最近有文献试图将这些方法的成功与潜表征之间互信息的最大化联系起来(Oord 等人,2018 年;Hénaff 等人,2019 年;Hjelm 等人,2018 年;Bachman 等人,2019 年)。然而,对比方法的成功与否是由互信息决定的,还是由对比损失的具体形式决定的,目前还不清楚(Tschannen 等人,2019)。
我们注意到,我们框架的几乎所有组成部分都出现在以前的工作中,尽管具体的实例可能有所不同。我们的框架相对于之前工作的优越性并不是由任何单一的设计选择造成的,而是由它们的组成所决定的。我们在附录 C 中对我们的设计选择与前人的设计选择进行了全面比较。
8. 结论
在这项工作中,我们提出了一个用于对比性视觉表征学习的简单框架及其实例化。我们仔细研究了它的各个组成部分,并展示了不同设计选择的效果。结合我们的研究成果,我们大大改进了以往的自我监督、半监督和迁移学习方法。
我们的方法与 ImageNet 上的标准监督学习仅在数据增强的选择、网络末端非线性头的使用和损失函数上有所不同。这一简单框架的优势表明,尽管自监督学习最近备受关注,但其价值仍被低估。
(10:56,看完了.)
总结:
1.一篇好的论文,写的是通俗易懂的,不是大量堆砌高级词汇,逻辑清晰有条理,nice.
2.一篇好的论文,是能经得起时间的考验的,我现在2024年看这篇2020年的论文,里面的实验和结论都是经得起推敲的.
希望我也可以做出来这种底气十足,能顶天立地的工作,加油.
SimCLR: 一种视觉表征对比学习的简单框架《A Simple Framework for Contrastive Learning of Visual Representations》(对比学习、数据增强算子组合,二次增强、投影头、实验细节很nice),好文章,值得反复看的更多相关文章
- 论文解读(SimCLR)《A Simple Framework for Contrastive Learning of Visual Representations》
1 题目 <A Simple Framework for Contrastive Learning of Visual Representations> 作者: Ting Chen, Si ...
- 设计模式学习之简单工厂(Simple Factory,创建型模式)(1)
简单工厂(Simple Factory,创建型模式) 第一步: 比如我们要采集苹果和香蕉,那么我们需要创建一个Apple类和Banana类,里面各自有采集方法get(),然后通过main方法进行调用, ...
- 解决:百度编辑器UEditor,怎么将图片保存到图片服务器,或者上传到ftp服务器的问题(如果你正在用UE,这篇文章值得你看下)
在使用百度编辑器ueditor的时候,怎么将图片保存到另一个服务器,或者上传到ftp服务器?这个问题,估计很多使用UE的人会遇到.而且我百度过,没有找到这个问题的解决方案.那么:本篇文章就很适合你了. ...
- 如何搭建老板想要的dashborad管理驾驶舱,这篇文章值得一看!
随着企业管理向精细化发展和信息化步伐的加快,企业采集到的市场客户及内部管理数据越来越多.越来越趋向于实时,系统大量的信息给企业带来了一个问题:管理者怎么用这些数据才能掌握企业动态,做出及时关键的决策? ...
- 遇到bug怎么分析,这篇文章值得一看
博主总结的非常到位:https://mp.weixin.qq.com/s/UpaLWjix2tnfTqybx9dmoQ 为什么定位问题如此重要? 可以明确一个问题是不是真的"bug" ...
- [源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer
[源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer 目录 [源码解析] 深度学习分布式训练框架 horovod (7) --- Distri ...
- [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 0x00 摘要 0 ...
- [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark
[源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark ...
- [源码解析] 深度学习分布式训练框架 horovod (18) --- kubeflow tf-operator
[源码解析] 深度学习分布式训练框架 horovod (18) --- kubeflow tf-operator 目录 [源码解析] 深度学习分布式训练框架 horovod (18) --- kube ...
- [源码解析] 深度学习分布式训练框架 horovod (21) --- 之如何恢复训练
[源码解析] 深度学习分布式训练框架 horovod (21) --- 之如何恢复训练 目录 [源码解析] 深度学习分布式训练框架 horovod (21) --- 之如何恢复训练 0x00 摘要 0 ...
随机推荐
- 详解C#委托与事件
在C#中,委托是一种引用类型的数据类型,允许我们封装方法的引用.通过使用委托,我们可以将方法作为参数传递给其他方法,或者将多个方法组合在一起,从而实现更灵活的编程模式.委托类似于函数指针,但提供了类型 ...
- Java-记住上一次访问时间案例
记住上一次访问时间 1.需求: 1.访问一个Servlet,如果是第一次访问,则提示:您好,欢迎您首次访问 2.如果不是第一次访问,则提示:欢迎回来,您上次访问的时间为:显示字符串 2.分析 1.可以 ...
- oeasy教您玩转vim - 62 - # 缓冲buffer
编辑过程 回忆上次 我们这次了解了编辑过程 默认有一个替换文件swap 修改的内容会保存到一个swap文件 如果swp已经存在 会有个swo文件 以此类推 替换文件可以进行对源文件的修复 没保存到 ...
- 学习笔记--Java中this关键字
Java中this关键字 关于Java语言中的this关键字 this 是一个关键字,翻译为:这个 this 是一个引用,一个变量,this变量中保存的内存地址指向自身 每一个对象都有自己的this, ...
- 免费使用TasteWP一键搭建线上临时WordPress网站
虽然用宝塔面板或者1Panel面板可以非常快速的搭建一个WordPress网站,但是有时候只想测试下我设计的页面或者开发的主题和插件,又得买服务器,绑定域名,安装程序,搭建起来也过于浪费时间了:再或者 ...
- blender建模渲染Tips
blender渲染 灯光的三种方式 1,常规灯光:shift+A选择灯光. 2,世界环境光:右侧地球图标调整. 3,物体自发光:把渲染物体变成一个发光体来进行调节灯光. 渲染视窗的调节 ctrl+b裁 ...
- 为什么自动驾驶领域发论文都是用强化学习算法,但是实际公司里却没有一家使用强化学习算法?—— (特斯拉今年年初宣布推出实际上第一款纯端到端的自动驾驶系统,全部使用强化算法,替换掉30万行C++的rule-based代码)
为什么自动驾驶领域发论文都是用强化学习算法,但是实际公司里却没有一家使用强化学习算法?-- (特斯拉今年年初宣布推出实际上第一款纯端到端的自动驾驶系统,全部使用强化算法,替换掉原有的30万行C++的r ...
- 构建人工智能的工具 —— VXscan-R:数字孪生环境软件模块
地址: https://www.creaform3d.com.cn/zh/ji-liang-jie-jue-fang/vxscan-rshu-zi-luan-sheng-huan-jing-ruan- ...
- 【转载】 PID算法的解析
原文来自DF创客社区地址:http://www.dfrobot.com.cn/community/thread-14783-1-1.html ----------------------------- ...
- 区块链共识机制 —— PoW共识的Python实现
原始实现(python2 版本) https://github.com/santisiri/proof-of-work 依据python3特性改进后: #!/usr/bin/env python # ...