1. Canal入门
1. Canal简介
官方文档: https://github.com/alibaba/canal/wiki/简介
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元,也就是Canal,翻译为管道的意思
工作原理
官网截图
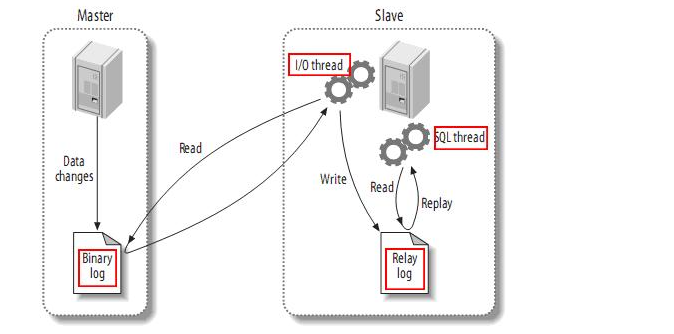
先简单了解一下关于Mysql,master和slave的同步机制:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);需要手动打开,master在更新数据时,会同步操作日志文件,会有性能方面的影响,如果没有同步需要,关闭即可
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
详细信息可以参考:
- http://dev.mysql.com/doc/refman/5.5/en/binary-log.html
- http://www.taobaodba.com/html/474_mysqls-binary-log_details.html
以上是mysql主从备份的简单了解,以下是Canal的工作原理:
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)
- canal将数据推送给指定的目标位置,并封装为对象的形式操作
2. Canal服务端搭建
2.1 部署Mysql
Mysql的搭建我这里就不说了,搭建完毕后,需要修改一些信息:
修改Mysql配置文件(我是在windows下,默认文件夹是C:\ProgramData\MySQL\MySQL Server 5.7\my.ini,需要打开隐藏目录):
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
创建Canal连接的账号,并赋予slave的权限:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
然后重启mysql服务即可
可以使用如下命令查看是否打开binlog模式:
show variables like 'log_bin';
查看binlog日志文件列表:
show binary logs
2.2 Canal服务搭建
下载canal包: https://github.com/alibaba/canal/releases ,我下载的是 1.1.5 版本, canal.deployer-1.1.5.tar.gz
解压完毕后, 修改conf/example/instance.properties 配置文件,如下:
# enable gtid use true/false
canal.instance.gtidon=false
# 数据库地址
canal.instance.master.address=127.0.0.1:3306
#执行binlog文件
canal.instance.master.journal.name=mysql-bin.000001
#起始位置.跳过Mysql初始的一部分
canal.instance.master.position=154
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
# 数据库账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
# 指定同步的表名 这里是全部
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# mq config
canal.mq.topic=example
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
然后执行bin目录下对应操作系统的启动脚本即可:
这样就启动成功了
3. 客户端搭建
创建客户端连接Canal服务
创建maven项目,导入依赖:
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.5</version>
</dependency>
</dependencies>
客户端代码:
class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "root", "root");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
//如果是事务开启关闭时间则跳过
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
当我们操作数据库时,客户端则可以获取到事件的发生:
empty count : 1
empty count : 2
empty count : 3
empty count : 4
empty count : 5
empty count : 6
empty count : 7
empty count : 8
empty count : 9
empty count : 10
empty count : 11
empty count : 12
empty count : 13
empty count : 14
================> binlog[mysql-bin.000001:1893] , name[test,aa_test] , eventType : CREATE
empty count : 1
empty count : 2
empty count : 3
empty count : 4
empty count : 5
empty count : 6
empty count : 7
empty count : 8
empty count : 9
empty count : 10
empty count : 11
empty count : 12
empty count : 13
empty count : 14
empty count : 15
empty count : 16
empty count : 17
empty count : 18
================> binlog[mysql-bin.000001:2698] , name[test,aa_test] , eventType : INSERT
id : 1111110946 update=true
status : 1 update=true
orderId : 1 update=true
orderProductId : 1 update=true
stanId : 1 update=true
quantity : 1 update=true
paymentDate : 2021-07-07 14:07:23 update=true
warehouse : 1 update=true
pid : 1 update=true
customerId : 1 update=true
type : 1 update=true
empty count : 1
empty count : 2
empty count : 3
empty count : 4
如上日志显示, 创建表和向中插入一条数据的时间都被记录,并打印出插入的数据
1. Canal入门的更多相关文章
- canal入门Demo
关于canal具体的原理,以及应用场景,可以参考开发文档:https://github.com/alibaba/canal 下面给出canal的入门Demo (一)部署canal服务器 可以参考官方文 ...
- (1)Canal入门
1.前言 在我们系统开发过程中,根据业务场景很多数据库数据并不会直接给用户访问的,需要同步保存到ElasticSearch.Redis等存储应用当中(例如最常见的是搜索页面的ElasticSearch ...
- canal 入门(基于docker)
第一步:安装MySQL:(可以参考:https://my.oschina.net/amhuman/blog/1941540) 命令: sudo docker run -it -d --restart ...
- canal 入门
参考文章:Canal - 安装 https://www.aliyun.com/jiaocheng/1131288.html?spm=5176.100033.2.7.7b422237XAirIe 前 ...
- canal入门使用
1.下载canal安装包: 地址:https://github.com/alibaba/canal/releases 图例: 2.将下载好的安装包复制到Linux,解压 3.修改配置文件 vi con ...
- Canal入门
配置mysql 1.mysql开启binlog mysql默认没有开启binlog,修改mysql的my.cnf文件,添加如下配置,注意binlog-format必须为row,因为binlog如果为S ...
- 数据的异构实战(一) 基于canal进行日志的订阅和转换
什么是数据的异构处理.简单说就是为了满足我们业务的扩展性,将数据从某种特定的格式转换到新的数据格式中来. 为什么会有这种需求出现呢? 传统的企业中,主要都是将数据存储在了关系型数据库中,例如说MySQ ...
- 使用canal分析binlog(一) 入门
canal介绍 canal是应阿里巴巴存在杭州和美国的双机房部署,存在跨机房同步的业务需求而提出的.早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求.不过早期的数据库同步 ...
- canal 结合 kafka 入门
1.kafka的安装: 略 2.cannal 配置 使用卡夫卡: 修改 /home/admin/canal-server/conf/canal.properties 2.1 修改canal.ser ...
- 「从零单排canal 01」 canal 10分钟入门(基于1.1.4版本)
1.简介 canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费.应该是阿里云DTS(Data Transfer Servi ...
随机推荐
- git checkout switch restore
前言 在 Git 术语中,"checkout"是在目标实体的不同版本之间切换的行为.该命令对三个不同的实体进行操作:文件.提交和分支.除了"checkout"的 ...
- Java 自增自减运算符和移位运算符介绍
摘自 JavaGuide (「Java学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识.准备 Java 面试,首选 JavaGuide!) 自增自减运算符 在写代码的过程中,常见的 ...
- C/C++ 实现常用的线程注入
各种API远程线程注入的方法,分别是 远程线程注入,普通消息钩子注入,全局消息钩子注入,APC应用层异步注入,ZwCreateThreadEx强力注入,纯汇编实现的线程注入等. 简单编写DLL文件: ...
- 同时配置github和gitee秘钥
1.设置用户名和邮箱 git config --global --list 查看全局配置信息 git config --global --list 删除配置:必须删除该设置 git config -- ...
- JDK8新特性Stream流操作
1 package stream; 2 3 import java.util.ArrayList; 4 import java.util.function.Function; 5 import jav ...
- 【.NET】聊聊 IChangeToken 接口
由于两个月的奋战,导致很久没更新了.就是上回老周说的那个产线和机械手搬货的项目,好不容易等到工厂放假了,我就偷偷乐了.当然也过年了,老周先给大伙伴们拜年了,P话不多讲,就祝大家身体健康.生活愉快.其实 ...
- 开源.NetCore通用工具库Xmtool使用连载 - OSS文件上传篇
[Github源码] <上一篇> 介绍了Xmtool工具库中的图像处理类库,今天我们继续为大家介绍其中的OSS文件上传类库. 将本地文件上传到服务器是软件系统经常会遇到的需求,例如:设置用 ...
- NC54586 小翔和泰拉瑞亚
题目链接 题目 链接:https://ac.nowcoder.com/acm/problem/54586 来源:牛客网 题目描述 小翔爱玩泰拉瑞亚 . 一天,他碰到了一幅地图.这幅地图可以分为 \(n ...
- ipset 笔记
官网:http://ipset.netfilter.org/ ipset是维护内核中IP sets结构的工具,允许你创建 匹配整个地址集合的规则.iptables配合ipset使用后不仅能单IP匹配, ...
- SpringBoot整合EasyExcel实现Excel表格的导出功能
前言 大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教. 在后端管理系统的开发中,经常有导出当前表格数 ...