Docker部署深度学习模型
Docker部署深度学习模型
基础概念
Docker
Docker是一个打包、分发和运行应用程序的平台,允许将你的应用程序和应用程序所依赖的整个环境打包在一起。比如我有一个目标检测的项目,我想分享给朋友,那么他首先需要在自己的电脑上配置好显卡驱动、CUDA、CuDNN,在拿到我的项目后,还需要安装各种依赖库,最后代码还不一定跑起来。如果我是用了docker环境进行项目配置,我只需要将环境打包好后分享给朋友。他只需要安装好显卡驱动就行,什么cuda、pytorch之类的都在我分享的环境了。
镜像
Docker镜像里包含了你打包的应用程序及其所依赖的环境。包含应用程序可用的文件系统和其他元数据。
容器
Docker容器通常是一个Linux容器,基于Docker镜像被创建,一个运行中的容器是一个运行在Docker主机上的进程,但和主机及所有在主机上的其他进程是隔离的。其资源是受限的,只能访问和使用分配的资源(CPU、内存)。
拉取镜像
在Windows上安装Docker Desktop就不过多赘述了。
先拉取一个pytorch镜像(结合自己电脑的显卡版本挑选适合的镜像版本):
docker pull anibali/pytorch:1.13.0-cuda11.8-ubuntu22.04
准备深度学习项目
我们拿yolov5举例。
在Windwos上下载好yolov5项目代码,同时下载检查点模型。
准备好测试代码:
import torch
# Model
model = torch.hub.load('.', 'custom', path='yolov5l.pt',source='local')
# Images
img = "./pic/gyt.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.save() # or .show(), .save(), .crop(), .pandas(), etc.
创建容器
镜像我们有了,现在我们可以创建容器了。同时我们需要将深度学习项目资源拷贝到容器中,下面有两种方法。
直接拷贝
创建容器的命令是:
docker run -it --gpus all --name container1 anibali/pytorch:1.13.0-cuda11.8-ubuntu22.04 /bin/bash
在这个命令中,run是创建容器的指令,-it是交互式终端,因为创建的容器就相当于一个本机中的linux服务器,我们可以通过终端与容器交互。–gpus all这个就是使用本机的gpu,–name是给新建容器取个名字, anibali/pytorch:1.13.0-cuda11.8-ubuntu22.04就是要使用的镜像,/bin/bash是指定bash。
当容器创建好后,将Windows的深度学习项目文件直接拷贝到容器中:
# 启动容器,配置或确认文件接收路径
docker ps -a
docker start 容器ID或容器名
docker exec -it 容器ID或容器名 bashmkdir demo
# 关闭容器
docker stop 容器ID或容器名
# 执行拷贝
docker cp D:\FileNeedUploadToDocker.txt 容器ID或容器名:/opt/demo
docker start 容器ID或容器名
docker exec -it 容器ID或容器名 bash
cd opt/demo/dir
资源映射
与直接拷贝不同的是,用资源映射既可以节省存储资源,又更加灵活方便(Windows或容器中的文件变化会实时反映到另一方,因为二者用的是同一份文件)。
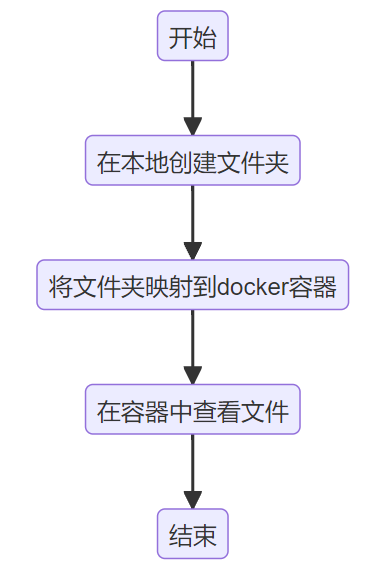
使用资源映射的方法创建容器:
docker run -it -v F:\Desktop\yolov5-master:/app/yolov5 --gpus all --name container1 anibali/pytorch:1.13.0-cuda11.8-ubuntu22.04 /bin/bash
进入容器
下面介绍两种进入容器的方法。
(1)使用命令行进入:
docker exec -it <container_name_or_id> /bin/bash
(2)使用Docker Desktop的GUI进入:
右键点击你想要进入的容器,选择“Open in PowerShell”
配置环境
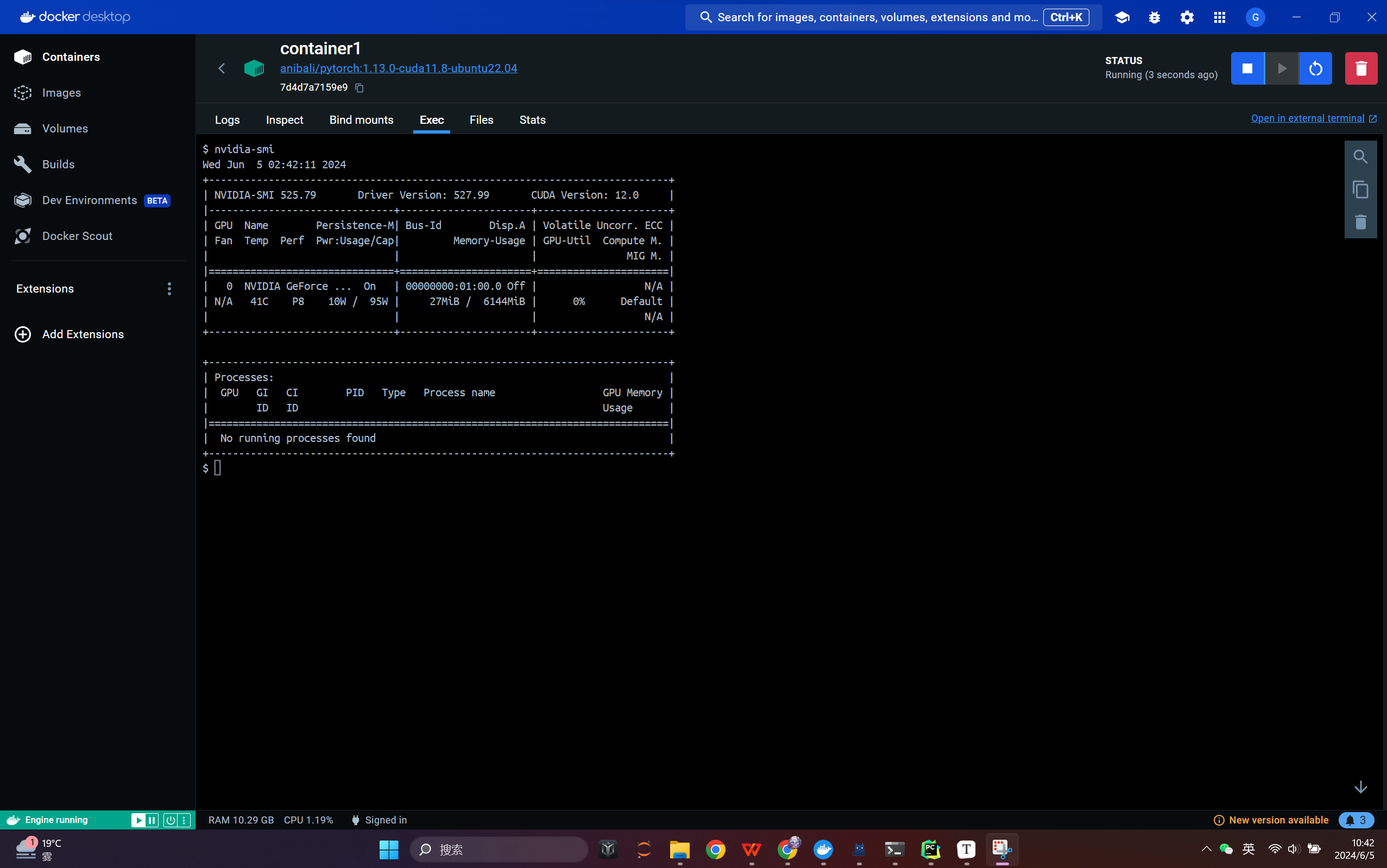
首先在容器中运行nvidia-smi命令,检查容器的显卡是否可用。若出现上图的情况,则表示成功。
创建conda环境:
conda create -n yolo python=3.8
安装pytorch:
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu118
安装其他库:
pip install -r requirements.txt
运行代码
运行“准备深度学习项目”中提到的测试代码,也许会遇到下图中的报错:
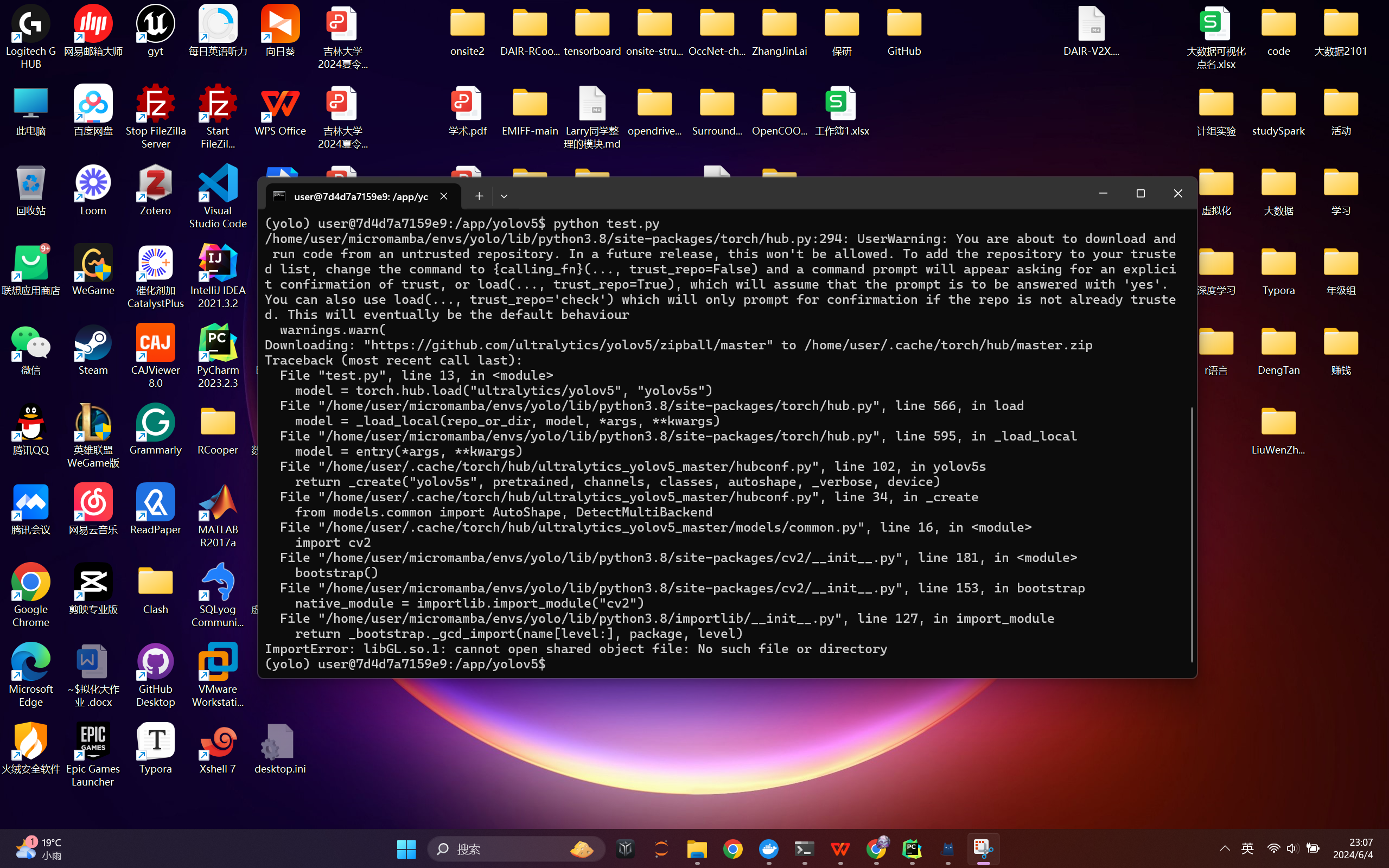
解决方法如下:
apt update
apt install libgl1-mesa-glx
pip uninstall opencv-python -y
pip install opencv-python-headless -i https://pypi.tuna.tsinghua.edu.cn/simple
成功运行截图:
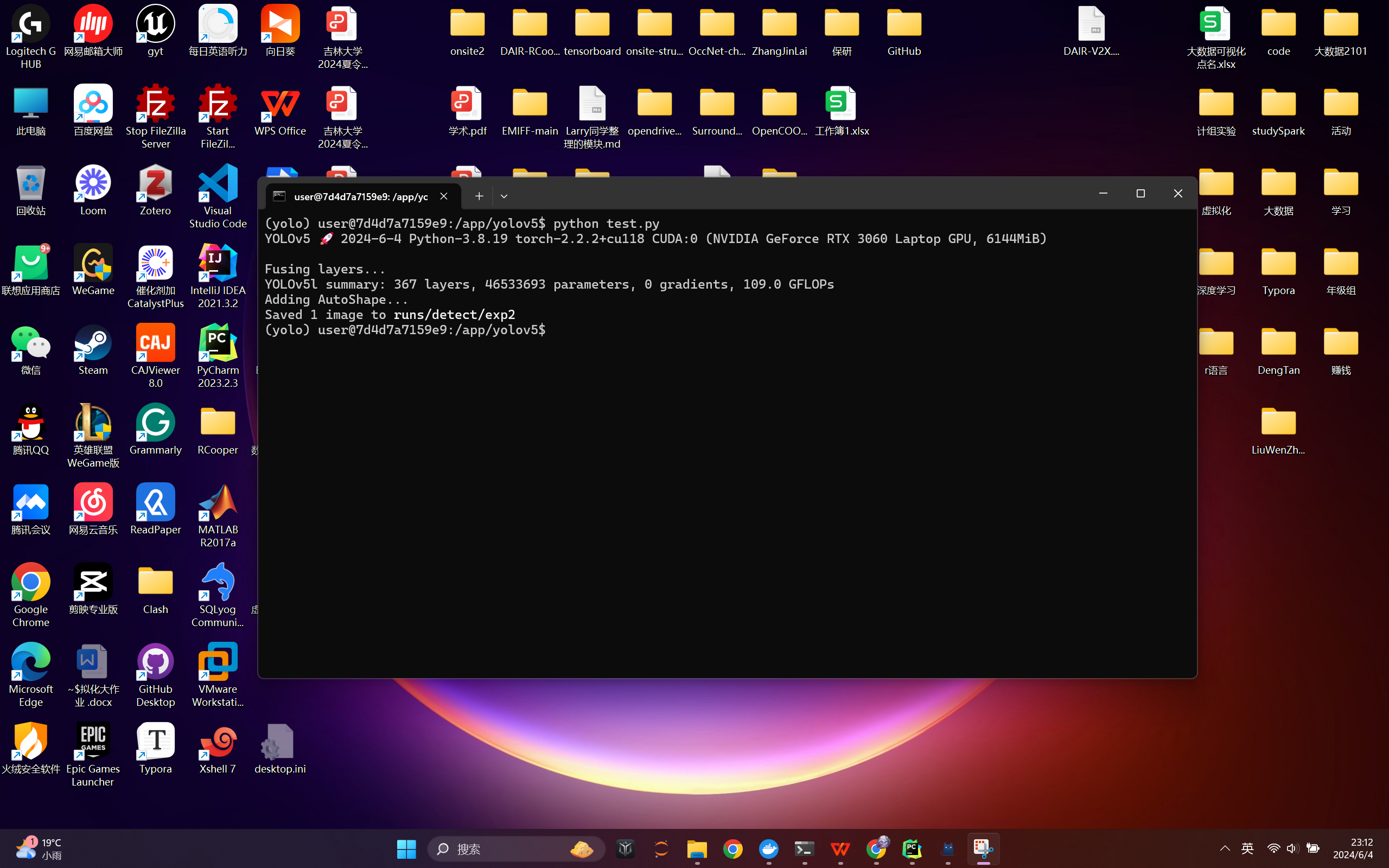
运行结果会保存到runs/detect/exp2这个目录下,下面是模型的输出:

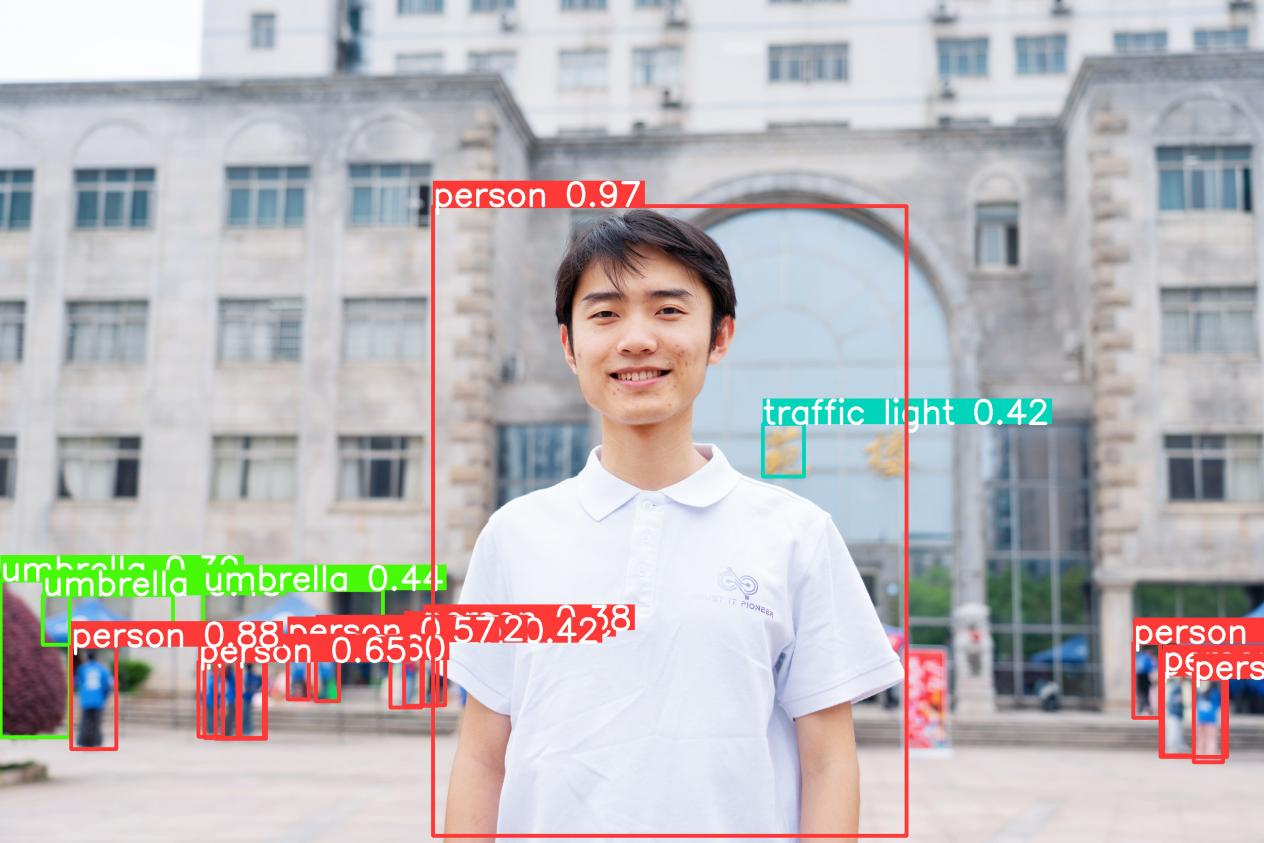
导出镜像
下面介绍两种导出镜像的方法。
将容器打包为镜像
运行命令:
docker commit -m "some information" <容器ID> <image_name:version>
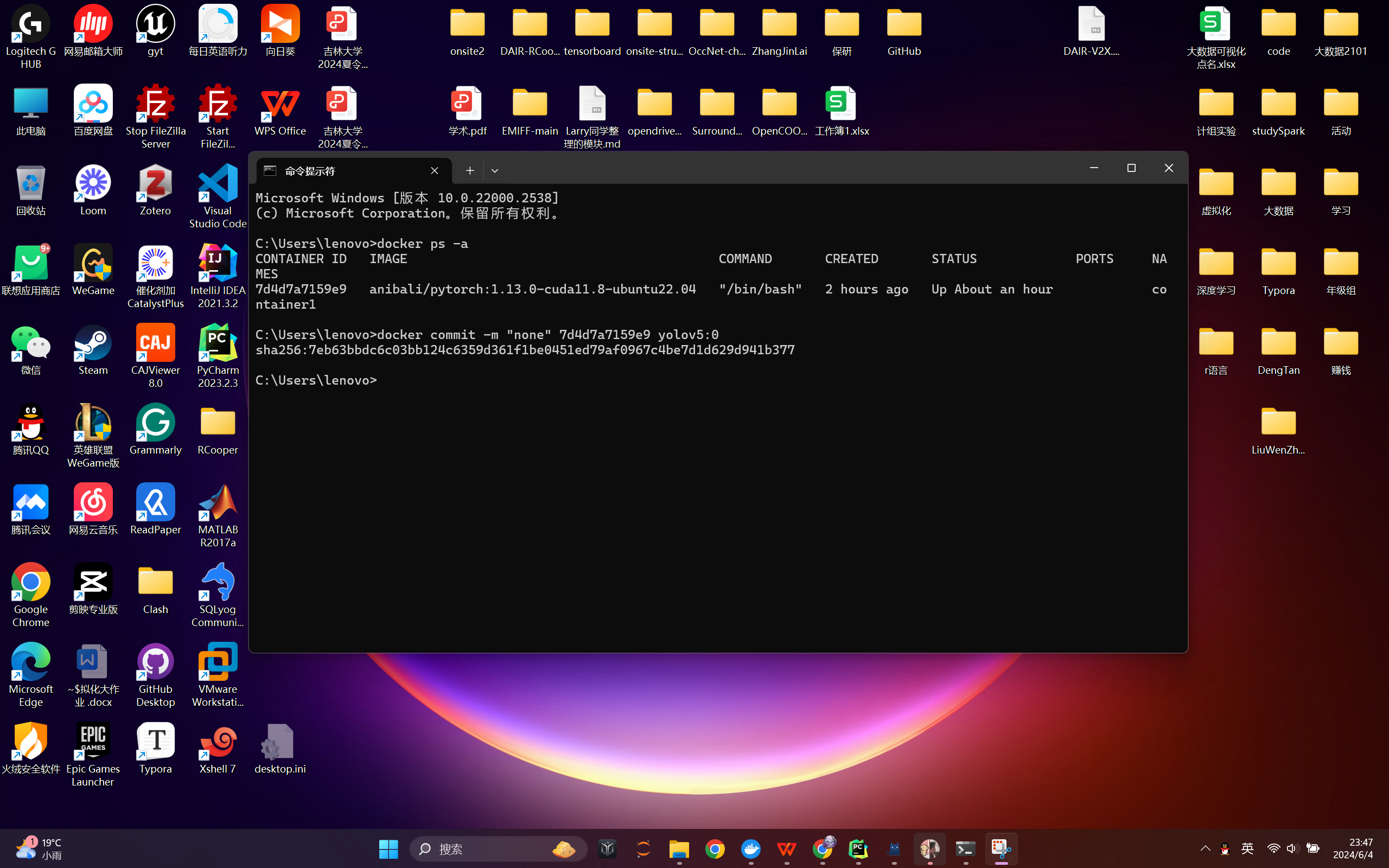
打包成功后,我们再介绍两种方法分享镜像。
(1)将镜像导出为tar分享给他人
docker save image_naem:version -o output_name.tar
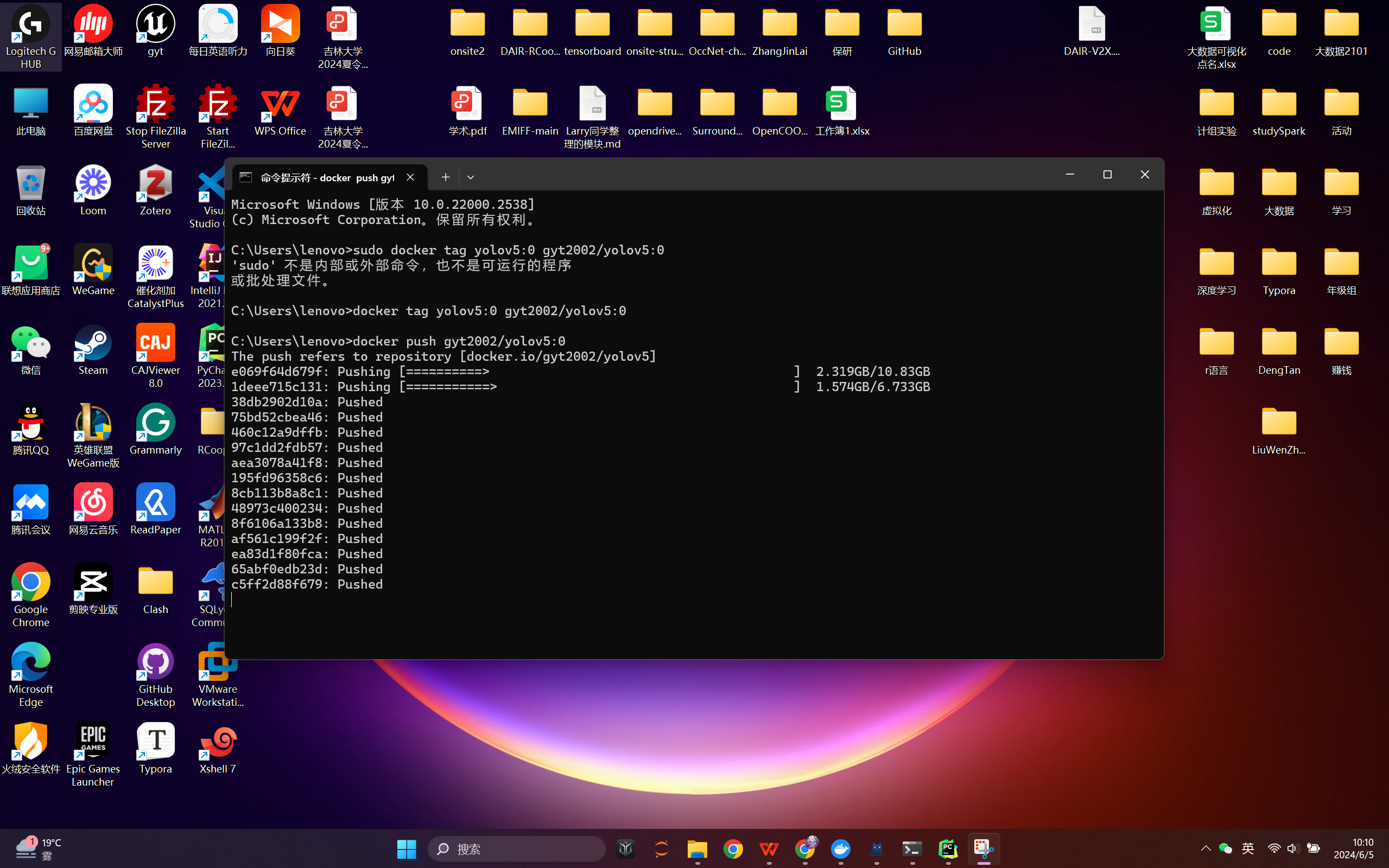
(2)将镜像推送到云仓库
docker tag new_image:version username/new_image:version
docker push username/pt_test_image:0
基于Dockerfile构建镜像
在Windows中的深度学习项目文件夹下运行命令:
docker build -t myapp .
-t参数用于指定镜像的名称,.表示使用当前文件夹中的Dockerfile。
下面看一下yolov5提供的Dockerfile文件:
# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch
FROM pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
# Downloads to user config dir
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
# Install linux packages
ENV DEBIAN_FRONTEND noninteractive
RUN apt update
RUN TZ=Etc/UTC apt install -y tzdata
RUN apt install --no-install-recommends -y gcc git zip curl htop libgl1 libglib2.0-0 libpython3-dev gnupg
# RUN alias python=python3
# Security updates
# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796
RUN apt upgrade --no-install-recommends -y openssl
# Create working directory
RUN rm -rf /usr/src/app && mkdir -p /usr/src/app
WORKDIR /usr/src/app
# Copy contents
COPY . /usr/src/app
# Install pip packages
COPY requirements.txt .
RUN python3 -m pip install --upgrade pip wheel
RUN pip install --no-cache -r requirements.txt albumentations comet gsutil notebook \
coremltools onnx onnx-simplifier onnxruntime 'openvino-dev>=2023.0'
# tensorflow tensorflowjs \
# Set environment variables
ENV OMP_NUM_THREADS=1
# Cleanup
ENV DEBIAN_FRONTEND teletype
Docker部署深度学习模型的更多相关文章
- flask部署深度学习模型
flask部署深度学习模型 作为著名Python web框架之一的Flask,具有简单轻量.灵活.扩展丰富且上手难度低的特点,因此成为了机器学习和深度学习模型上线跑定时任务,提供API的首选框架. 众 ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
- 用 Java 训练深度学习模型,原来可以这么简单!
本文适合有 Java 基础的人群 作者:DJL-Keerthan&Lanking HelloGitHub 推出的<讲解开源项目> 系列.这一期是由亚马逊工程师:Keerthan V ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- 用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈
用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈 深度学习已变得无处不在,不可或缺.这场革命的一部分是由可扩展的深度学习系统推动的,如滕索弗洛.MXNet.咖啡和皮托奇.大多数现有系统针对 ...
- CUDA上的量化深度学习模型的自动化优化
CUDA上的量化深度学习模型的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参 ...
- TVM将深度学习模型编译为WebGL
使用TVM将深度学习模型编译为WebGL TVM带有全新的OpenGL / WebGL后端! OpenGL / WebGL后端 TVM已经瞄准了涵盖各种平台的大量后端:CPU,GPU,移动设备等.这次 ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
随机推荐
- 力扣183(MySQL)-从不订购的客户(简单)
题目: 某网站包含两个表,Customers 表和 Orders 表.编写一个 SQL 查询,找出所有从不订购任何东西的客户. Customers 表: Orders 表: 解题思路: 需要查询出没 ...
- Java 应用压测性能问题定位经验分享
简介: 问题千千万,但只要修练了足够深厚的内功,形成一套属于自己的排查问题思路和打法,再加上一套支撑问题排查的工具,凭借已有的经验还有偶发到来的那一丝丝灵感,相信所有的问题都会迎刃而解. 作者:凡勇 ...
- iLogtail使用入门-K8S环境日志采集到SLS
简介:iLogtail是阿里云中简单日志服务又名"SLS"的采集部分. 它用于收集遥测数据,例如日志.跟踪和指标,目前已经正式开源(https://github.com/alib ...
- [Go] assignment count mismatch 1 = 2
Golang 中这个错误的的意思是赋值变量的数目不匹配. 举例: result := json.Marshal(List) 由于没有给返回值中的 error 正确赋值,就会报 assignment ...
- WPF 已知问题 BitmapDecoder.Create 不支持传入 Asynchronous 的文件流
这是在 GitHub 上有小伙伴报的问题,在 WPF 中,不支持调用 BitmapDecoder.Create 方法,传入的 FileStream 是配置了 FileOptions.Asynchron ...
- Linux系统命令-目录命令
1.ls命令:主要作用是显示目录下的内容 基本格式 [root@localhost ~]# ls [选项] [参数是文件名或目录名] 常用选项 -a:显示所有文件 --color=when:支持颜色输 ...
- kali使用apt-get update 出现数字签名失效
kali使用apt-get update 出现数字签名失效 下载签名:wget archive.kali.org/archive-key.asc 安装签名:apt-key add archive-ke ...
- 01、Windows 排查
Windows 分析排查 分析排查是指对 Windows 系统中的文件.进程.系统信息.日志记录等进行检测,挖掘 Windows 系统中是否具有异常情况 1.开机启动项检查 一般情况下,各种木马.病毒 ...
- windows版 navicat_15.0.18 安装
视频安装地址: https://www.ghpym.com/ghvideo07.html 一.下载安装包 下载地址(百度网盘): 链接:https://pan.baidu.com/s/1MIZfmS5 ...
- WEB服务与NGINX(15)-NGINX安装第三方模块
1.nginx安装第三方模块 nginx安装第三方模块需要进行编译安装,安装方法如下: ./configure --prefix=/你的安装目录 --add-module=/第三方模块目录 ... 注 ...