华为云企业级Redis揭秘第15期:Redis为什么需要强一致?
摘要:其实开源Redis的弱一致性已经不满足很多应用场景的诉求。怎么,不信?
本文分享自华为云社区《华为云企业级Redis揭秘第15期:Redis为什么需要强一致?》,作者: GaussDB 数据库。
有人说,开源Redis的最终一致性已经能满足大部分应用场景,也有人说,多副本的强一致代价太大,没有必要实现。要笔者说,其实弱一致性已经不满足很多应用场景的诉求。怎么,不信?请听笔者娓娓道来。
1. 不一致带来的困扰
1.1 秒杀变秒崩
分享一个电商秒杀活动中限流器的例子,在电商的秒杀活动中,为了扛住前端对数据库的超大流量冲击,一般使用两种方案来保护系统,一个是缓存,另一个则是限流。缓存这个容易实现,只需要在数据库前加一层缓存服务器,而对于限流来说,最简单的可以使用Redis的计数器来实现限流功能。
具体来说,假设我们需要对某个接口限定流量为5000QPS,即每秒钟访问的次数不能超过5000。那么我们可以这么做:在一开始的时候设置一个计数器counter为5000,并且过期时间为1s,即1s后计数器失效。每当一个请求过来的时候,counter的值减1,判断当前counter的值是否等于0,如果等于,则说明请求次数过多,直接拒绝请求。如果counter计数器不存在,则重置计数器为5000,开始新一秒的接口限流,注意并发情况下计数器需要加锁。
正常情况下,这种方案不会出现问题,但是针对这种秒杀活动,不怕一万,就怕万一,万一Redis突然宕机怎么办,那岂不是限流器形同虚设,所有流量全部涌向后端的数据库,瞬间系统崩溃。此时聪明的你肯定会想到,给Redis搞一个备用服务器不就解决了,主服务器如果宕机,备用服务器顶上。没错,这种方案是对的,但是只正确了一半。为什么呢,如下图所示。
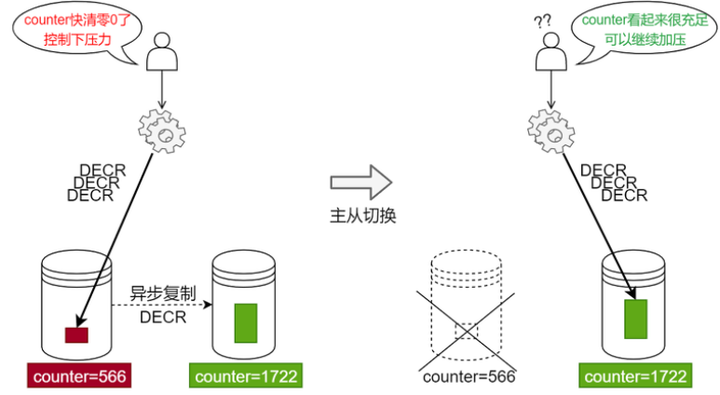
当给Redis配置从服务器之后,如果主服务器出现宕机,可以立刻切换到从服务器,但是由于开源Redis主从服务器之间的数据是异步复制的,如果网络不畅,经常发生主从数据不一致,如果此时主服务器发生宕机,切换到从服务器之后,因为限流器的判断出错,流量压力很容易超出阈值,一下子涌向数据库服务器,同样会造成系统崩溃。
仔细探究这个问题产生,根因是在于开源Redis的一致性机制为弱一致性,在某些时间内,主从副本数据不一致。而要彻底解决这个问题,只有真正的强一致才能解决。
1.2 难以维护的MySQL组件
其实不止Redis,就连大名鼎鼎的MySQL也逃不过弱一致的坑。MySQL的部署中,为了保证高可用性,主从热备份是MySQL常用的部署方式。但是如果发生故障时,仅仅靠MySQL自身的同步机制,是无法保证主库和从库之前的数据一致的,于是出现了重要的辅助组件MHA(Master High Availability),它的部署方式如下:

MHA由管理服务和Node服务组成,Node服务部署在每个MySQL节点上,MHA组件负责让MySQL的从库尽可能的追平主库,提供主从一致的状态。发生故障进行主从切换时,Manager首先为从库补充落后的数据,然后再将用户访问切换到从库,这个过程可能长达数十秒。
MHA的部署和维护都相当复杂,如未能顺利执行故障切换或发生数据丢失,运维面临的场面都将很棘手。其实运维同学何尝不希望手中的系统稳定运行呢?要是数据库自身能提供强一致保障,何苦再依赖复杂的辅助组件!
2. 什么是强一致
上一节中笔者介绍了弱一致带来各种问题,接下来这一节具体介绍下什么是强一致。在“分布式系统”和“数据库”这两个领域中,一致性都是重要概念,但它表达的内容却并不相同。对于分布式系统而言,一致性是在探讨当系统内的一份逻辑数据存在多个物理的数据副本时,对其执行读写操作会产生什么样的结果,这也符合 CAP 理论对一致性的表述。而在数据库领域,“一致性”与事务密切相关,又进一步细化到 ACID 四个方面。因此,当我们谈论分布式数据库的一致性时,实质上是在谈论事务一致性和数据一致性两个方面。
2.1 事务一致性
事务的一致性主要是指的事务的ACID,分别是原子性、一致性、隔离性和持久性,如下图所示:
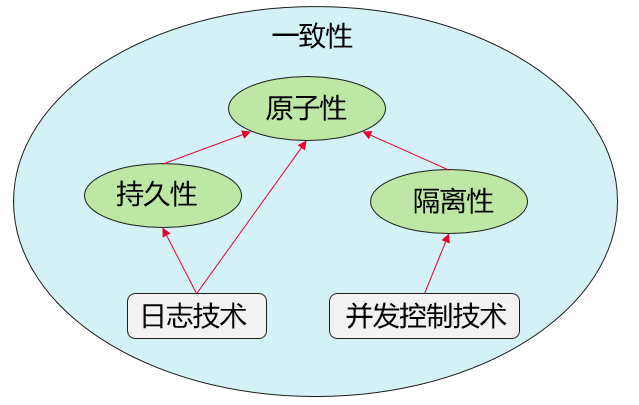
- 原子性:事务中的所有变更要么全部发生,要么一个也不发生,通过日志技术实现;
- 一致性:事务要保持数据的完整性,它是应用程序的属性,依赖原子性和隔离属性来实现;
- 隔离性:多事务并行执行所得到的结果,与串行执行(一个接一个)完全相同,通过并发控制技术来实现;
- 持久性:一旦事务提交,它对数据的改变将被永久保留,不应受到任何系统故障的影响,通过日志技术实现。
2.2 数据一致性
在分布式系统中,为了避免网络不可靠带来的问题,通常会存储多个数据副本,逻辑上的一份数据存储在多个物理副本上,自然带来了数据一致性问题。
(1)状态视角
从状态的视角来看,任何变更操作后,数据只有两种状态,所有副本一致或者不一致。在某些条件下,不一致的状态是暂时,还会转换到一致的状态,而那些永远不一致的情况几乎不会去讨论,所以习惯上大家会把不一致称为“弱一致”。相对的,一致就叫做“强一致”了。以一个一主两备的MySQL集群为例,“强一致”的交互过程如下:
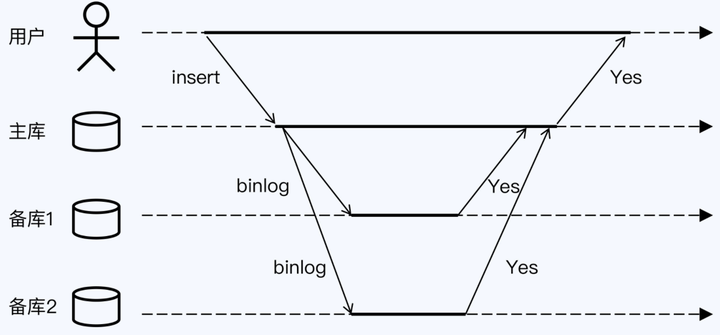
在该模式下,主库与备库同步 binlog 时,主库只有在收到两个备库的成功响应后,才能够向客户端反馈提交成功。显然,用户获得响应时,主库和备库的数据副本已经达成一致,所以后续的读操作肯定是没有问题的,这就是状态视角的“强一致”的模型。
但是状态视角的这种强一致副作用很大:第一个是性能很差,主库必须要等备库1和备库2成功返回后才能返回;第二个是可用性问题,如果主备节点很多,出现故障的概率非常高。因此,状态视角的强一致代价非常大,所以很少使用。
(2)操作视角
状态视角的强一致降低了系统的可用性,因此很多系统选择状态视角的弱一致性模型,通过额外的算法(如Raft、Paxos)在不保证所有节点状态的一致的情况下,来保证操作视角的一致性,同时提高了系统的可用性。通过加入一些限定条件,衍生出了若干种一致性模型:

- 线性一致性:操作视角实现真正的强一致
- 顺序一致性:一致性强度弱于线性一致性
- 因果一致性:一致性强度弱于顺序一致性
- 写后读一致性:一致性强度相当,弱于因果一致性
这些一致性模型的介绍参考《高斯Redis与强一致》这篇文章。
3. 强一致的刚需场景
上一节我们介绍了什么是强一致,这一节我们介绍下强一致的典型应用场景。
在常见的互联网应用中,如果数据库服务器只部署在单个节点上,那么应用程序所有的读和写都只会访问单个节点,一份逻辑数据在物理上也只有一份,这种场景下就谈不上强一致的问题。
但是随着系统中业务访问量的增加,如果是单机部署数据库,就会导致I/O访问频率过高,数据库就会成为系统的瓶颈。此时,为了降低单机磁盘的I/O访问频率,提高单个机器的I/O性能,通常会增加多个数据存储节点,形成一主一从或者一主多重的架构,
此时,我们可以将负载分布在多个从节点上,一方面可以实现读写分离,写请求访问主库,读请求访问备库。另一方面,还可以在主库如果出现宕机的情况下进行主备切换,增强系统的稳定性。在以上两个场景中,由于一份逻辑数据在物理上有多个副本,那么如何保证多个副本之间的数据一致呢,这就是强一致需要解决的问题。
3.1 读写分离场景
以关系型数据库MySQL为例,典型的部署方案为一主两从三节点方案,主节点负责处理写操作,两个从节处理读操作,分担主库的压力,如下图所示:

此时,如果系统没有实现强一致,就有可能会遇到执行完写操作后,立刻去读,然后发现读不到或者读到旧状态的尴尬场景,比如操作顺序为以下操作:
- 客户端首先通过代理向主节点 Master 进行了写入操作,此时由于没有实现强一致,写操作写完后立即返回;
- 紧接着第二步去从节点 Slave A 执行读操作,此时Master和Slave A之间的同步还未完成,系统处于非强一致的状态,所以第二步的读操作读取到了旧状态。
可以看出,在一主多备读写分离的场景下,如果想要保证写入和读取操作的准确无误,系统实现强一致是非常重要的。
3.2 主备切换场景
主备切换的场景也需要强一致来保证,以目前业内使用最广泛的内存数据库Redis为例,Redis的主从同步如下图所示:
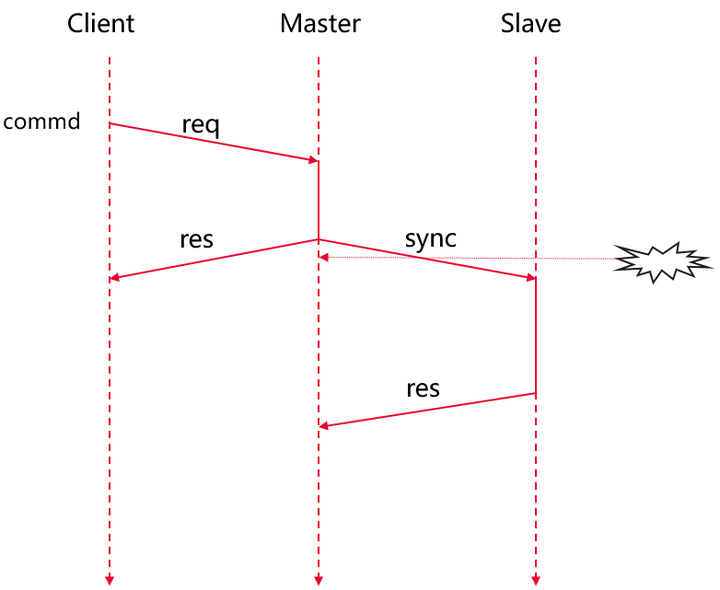
从上图可以看出,当Redis客户端向Master服务器发送一条命令时,Master服务器立即回复客户端命令的执行结果,并不等待命令同步到从服务器再回复,也就是说Redis的主从同步其实是异步的。
由于Master节点存在宕机的可能,在这种情况下,如果在Master收到命令但是还没同步到Slave服务器时发生了宕机,Redis就会发生主备切换,然后此时Master服务器和Slave服务器的数据还没有同步,就导致了数据丢失的情况。可见,开源Redis弱一致性本身的缺陷和不足,而要解决这个问题,必须实现强一致性才能解决。
4. 高斯Redis强一致
由于开源的Redis不具备强一致的特性,导致开源Redis的应用也受到了诸多限制,为了解决开源Redis弱一致的问题,GaussDB(for Redis)应运而生。GaussDB(for Redis) 是华为云数据库团队自主研发的兼容Redis协议的云原生数据库,彻底解决了开源Redis一致性问题带来的痛点。
4.1 高斯Redis架构
高斯Redis的整体架构如下:
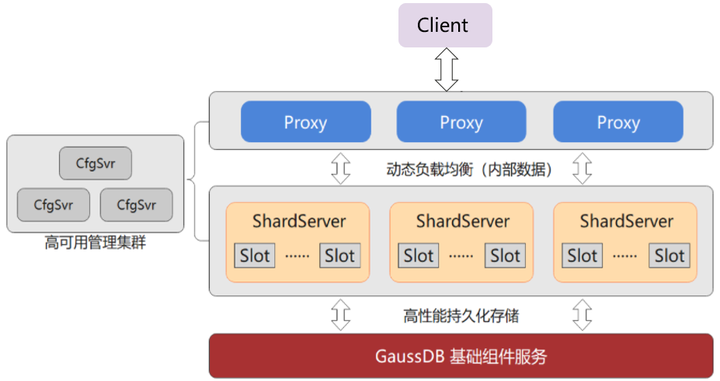
相比开源Redis,高斯Redis采用存算分离的设计思想,计算层负责计算和协议的处理,聚焦服务。而存储层负责副本管理、扩缩容等处理,聚焦数据本身。高斯Redis的优势如下:
- 数据强一致:存储层使用分布式存储DFV,轻松实现了3副本强一致;
- 超可用:N个节点的集群最多可以挂掉N – 1个节点;
- 低成本:数据采用磁盘存储并且进行压缩,每GB的成本不到开源Redis的十分之一;
- 秒扩容:计算层仅需修改路由映射,无需数据搬迁,实现秒级扩容;
- 自动备份:高斯Redis可以实现MVCC快照备份和定期自动备份。
4.2 高斯Redis强一致的实现
开源Redis和高斯Redis的架构如下图所示:

开源Redis或者传统的主从结构如左图所示,如果在读写分离的场景或者主节点出现宕机发生主从切换的时候,都会导致数据不一致的情况。
高斯Redis采用存算分离的架构,如右图所示,在存储层DFV的副本管理中采用分布式共识算法实现了3副本的强一致。计算层调用存储层的接口时,如果返回OK,那么即表示存储层已经实现副本强一致的复制。
5. 结语
我们在做架构设计的时候,其实很多场景都隐藏着强一致的诉求。如朋友圈这类应用,如果没有实现强一致,朋友圈的评论很容易乱序。再比如限流器的场景,如果没有强一致的保证,也极容易造成数据库的崩溃。因此,必须在系统设计之初就认识到强一致的重要性,才能设计出更加稳定和可靠的系统。而高斯Redis基于存算分离的架构设计,实现了数据的强一致,为业务的稳定可靠提供了超强保障。
6. 附录
本文作者:华为云数据库GaussDB(for Redis)团队
杭州/西安/深圳简历投递:yuwenlong4@huawei.com
- 本文作者:华为云数据库GaussDB(for Redis)团队
- 杭州/西安/深圳简历投递:yuwenlong4@huawei.com
- 更多产品信息:GaussDB(for Redis)官网
- 更多技术文章:GaussDB(for Redis)博客
华为云企业级Redis揭秘第15期:Redis为什么需要强一致?的更多相关文章
- 华为云企业级Redis揭秘第16期:超越开源Redis的ACID"真"事务
摘要: 开源Redis只支持伪事务,应用场景受限.高斯Redis发布企业级事务特性,支持完备ACID,为交易.库存等上层业务带来全新可能. 本文分享自华为云社区<华为云企业级Redis揭秘第16 ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第八期:用高斯 Redis 进行计数
摘要:高斯Redis,计数的最佳选择! 一.背景 当我们打开手机刷微博时,就要开始和各种各样的计数器打交道了.我们注册一个帐号后,微博就会给我们记录一组数据:关注数.粉丝数.动态数-:我们刷帖时,关注 ...
- 华为云企业级Redis评测第一期:稳定性与扩容表现
摘要:采用Redis Labs推出的多线程压测工具memtier_benchmark对比测试下GaussDB(for Redis) 和原生Redis的特性差异. 本文分享自华为云社区<华为云企业 ...
- redis入门(15)redis的数据备份和恢复
redis入门(15)redis的数据备份和恢复
- 华为云PB级数据库GaussDB(for Redis)揭秘第七期:高斯Redis与强一致
摘要:在KV数据库领域,"强一致性"不仅是一个技术名词,它更是业务与运维的重要需求. 清明刚过,五一假期就要来了.大好春光,不如去婺源看油菜花吧!小云迅速打开APP刷出余票2张,赶 ...
- 大海航行靠舵手 华为云靠什么征服K8S?
Kubernetes 是Google开源的容器集群管理系统或者称为分布式操作系统.它构建在Docker技术之上,为容器化的应用提供资源调度.部署运行.服务发现.扩容缩容等整一套功能,本质上可看作是基于 ...
- 华为云Stack新版发布:构筑行业云底座,共创行业新价值
摘要:在以"政企深度用云,释放数字生产力"为主题的华为云Stack战略暨新品发布会上,华为云提出深度用云三大关键举措,并发布华为云Stack 8.2版本,以智能进化推动创造行业新价 ...
- 揭秘丨7分钟看懂华为云鲲鹏Redis背后的自研技术【华为云技术分享】
2019年5月,华为云发布全球首个基于自研ARM架构的分布式缓存鲲鹏Redis,搭载华为LibOS+华为编译器+安全容器引擎三项黑科技,在保证Redis强劲高性能外,还降低客户30%的使用成本,真正实 ...
- [动图演示]Redis 持久化 RDB/AOF 详解与实践【华为云技术分享】
Redis 是一个开源( BSD 许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件.它支持的数据类型很丰富,如字符串.链表.集 合.以及散列等,并且还支持多种排序功能. 什么叫持 ...
- 揭秘华为云GaussDB(for Influx):数据直方图
摘要:本文带您了解直方图在不同产品中的实现,以及GaussDB(for Influx)中直方图的使用方法. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第九期:最佳实践 ...
随机推荐
- 在centos7上使用 docker安装mongodb挂载宿主机以及创建其数据库的用户名和密码(最新版本)
前言 因为博主在使用docker安装mongodb并挂载时,发现在网上搜了好多都是以前版本的mongodb,并且按照他们操作总是在进入mongodb出问题,博主搞了好久终于弄好了,故写下博客,供有需要 ...
- Spring系列:基于XML的方式构建IOC
目录 一.搭建模块spring6-ioc-xml 二.获取bean的三种方式 三.基于setter注入 四.基于构造器注入 五.特殊值处理 六.为对象类型属性赋值 七.引入外部属性文件 八.基于XML ...
- 多巴胺所表达的prediction error信号
Dopamine reward prediction-error signalling: a two-component response (Wolfram Schultz; NATURE REVIE ...
- 暴力+DP:买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格. 如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润. 注意:你不能在买入股票前卖出股票. ...
- 2021牛客多校第一场 I题(DP)
题意 给定一个长度为 \(n(n<=5000)\) 的排列,两个人轮流从这个序列中选择一个数,要求当前回合此人选择的数大于任意一个已经被选择的数,并且该数在数组中的位置 \(i\) 与此人上一次 ...
- class-dump 混淆加固、保护与优化原理
class-dump 混淆加固.保护与优化原理 进行逆向时,经常需要dump可执行文件的头文件,用以确定类信息和方法信息,为hook相关方法提供更加详细的数据.class-dump的主要用于检查存 ...
- excel怎么固定前几行前几列不滚动?
在Excel中,如果你想固定前几行或前几列不滚动,可以通过以下几种方法来实现.详细的介绍如下: **固定前几行不滚动:** 1. 选择需要固定的行数.例如,如果你想要固定前3行,应该选中第4行的单元格 ...
- GitHub、Google等镜像加速地址收集
摘要 本文用于收集GitHub.Google等镜像/加速地址. GitHub GitHub加速地址一览 fastgithub Https://www.fastgithub.com/(推荐) 站源 地址 ...
- React Hooks 钩子特性
人在身处逆境时,适应环境的能力实在惊人.人可以忍受不幸,也可以战胜不幸,因为人有着惊人的潜力,只要立志发挥它,就一定能渡过难关. Hooks 是 React 16.8 的新增特性.它可以让你在不编写 ...
- Selenium的基本api
1.打开浏览器的驱动,以chrome为例 from selenium import webdriver #chrome驱动 driver = webdriver.Chrome(executable_p ...