MySQL运维12-Mycat分库分表之按天分片
一、按天分片
指定一个时间周期,将数据写入一个数据节点中,例如:第1-10天的数据,写入到第一个数据节点中,第2-20天的数据写入到第二个节点中,第3-30天的数据节点写入到第三个数据节点中。
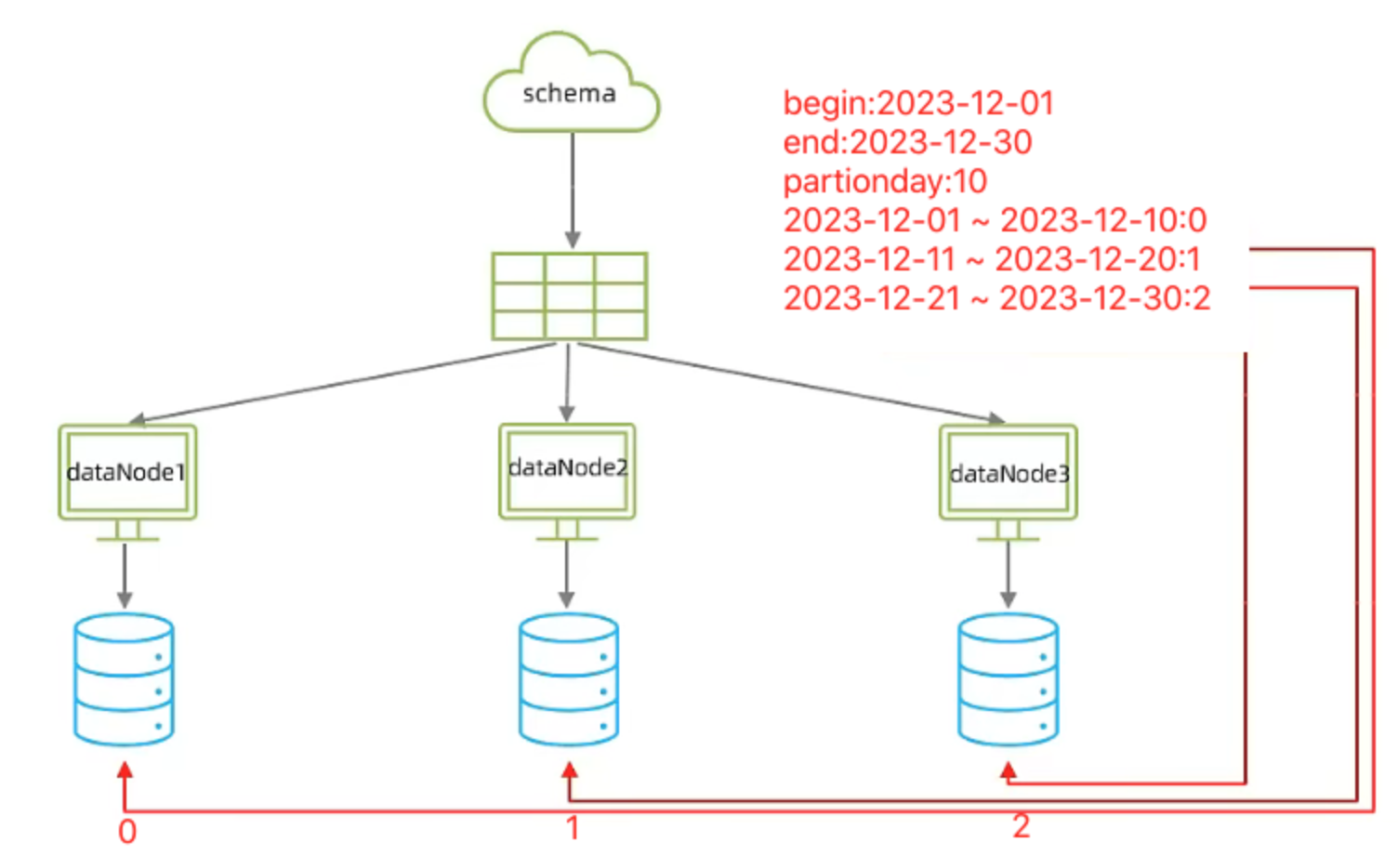
说明1:按天分片要配置一个起始日期,一个结束日期,一个分片间隔时间三个参数
说明2:按天分片允许当前时间超出配置的开始时间和结束时间,超出时间范围仍然会按照分片间隔时间,继续在多个数据节点之间切换的
说明3:该案例中分片的起始时间为2023-12-01,结束时间为2023-12-30,一共30天的时间。但是如果当前日期超过了这个时间段,该规则仍然可以用,继续按照分片间隔时间10天,继续分片。
说明4:该案例中分片间隔时间为10,即10天。所以这里需要至少三个数据节点。因为分片时间范围是30天除以10天的间隔等于3,而如果只配置了两个分片服务器则会报错,因为第1-10天的数据写在了第一个分片服务器上,第10-20天的数据写入到了第二个分片数据库中,从第21天-30的数据,就会找不到分片服务器而报错。
二、准备工作
逻辑库:hl_logs,先在各个数据节点上创建好数据库。

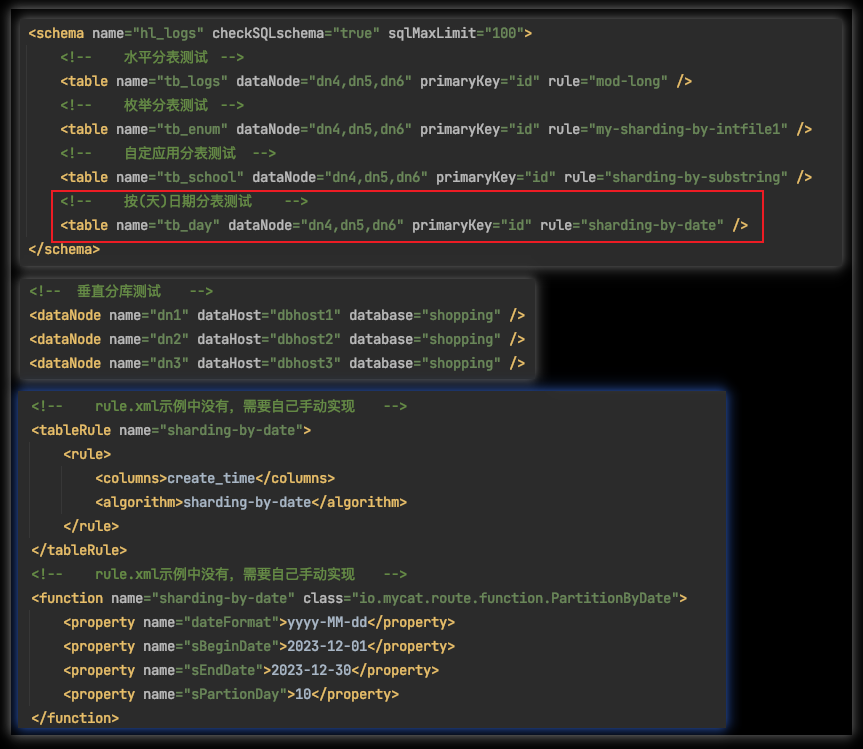
三、配置rule.xml
<!-- rule.xml示例中没有,需要自己手动实现 -->
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
说明1:这个按照(天)日期分片,在rule.xml示例中也是没有写好的,需要自己实现。
<!-- rule.xml示例中没有,需要自己手动实现 -->
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2023-12-01</property>
<property name="sEndDate">2023-12-30</property>
<property name="sPartionDay">10</property>
</function>
说明2:这个按照(天)日期分片的function标签,在rule.xml示例中也是没有写好的,需要自己实现。
说明3:dateFormat属性设置的分片日期的格式
说明4:sBeginDate是分片的开始日期
说明5:sEndDate是分片的结束日期
说明6:sPartionDay是分片间隔时间
说明7:如果当前时间超过了分片结束日期依然可以继续按照分片间隔时间,继续分片使用
四、配置schema.xml
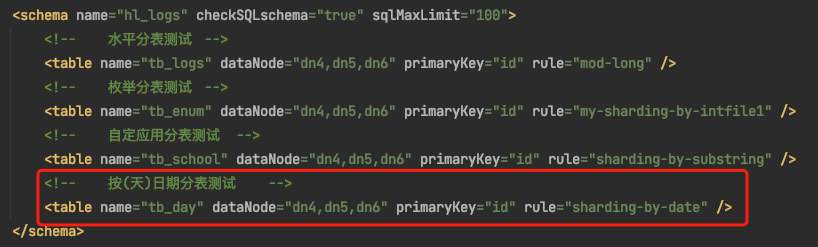
说明1:逻辑库为:hl_logs
说明2:逻辑表为:tb_day
说明3:分片规则为:"sharding-by-date"
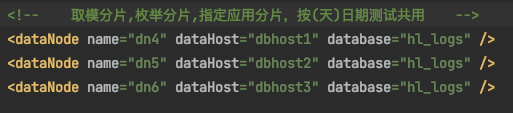

说明4:dn4对应的是dbhost1即192.168.3.90分片
说明5:dn5对应的是dbhost2即192.168.3.91分片
说明6:dn6对应的是dbhost3即192.168.3.92分片
五、配置server.xml
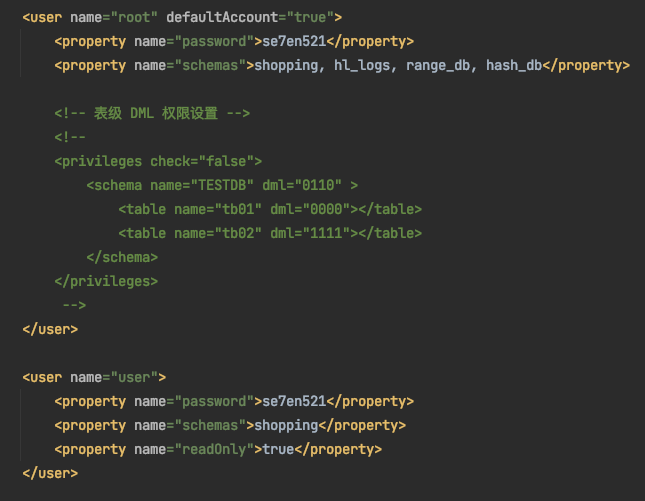
说明1:在之前的文章中已经将tb_logs表添加到root用户的权限中了,所以这里不需要更改即可。
六、按(天)日期分片测试
首先重启Mycat
登录Mycat
查看逻辑库和逻辑表
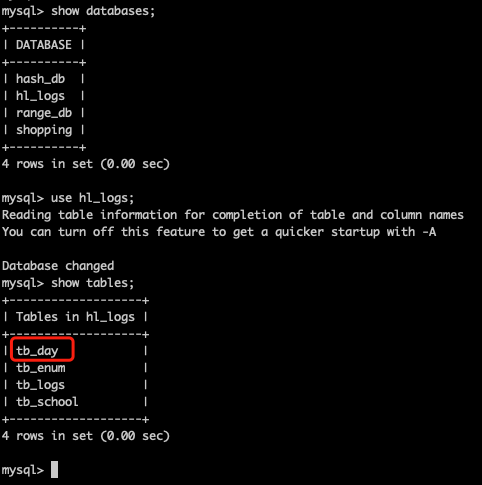
这里的tb_day只是逻辑库,而在MySQL中还并没有tb_day这个表,需要在Mycat中创建
create table tb_day(id int auto_increment primary key, name varchar(20), create_time varchar(19));

插入数据进行测试:这里插入一组数据进行测试:
insert into tb_day(name, create_time) values ("张三", "2023-12-02");
insert into tb_day(name, create_time) values ("李四", "2023-12-12");
insert into tb_day(name, create_time) values ("王五", "2023-12-22");
insert into tb_day(name, create_time) values ("赵六", "2023-12-31");
insert into tb_day(name, create_time) values ("侯七", "2024-01-01");
insert into tb_day(name, create_time) values ("孙八", "2024-01-11");
insert into tb_day(name, create_time) values ("周九", "2024-01-21");

说明1:张三的创建时间为2023-12-02在2023-12-01 至 2023-12-10之间,所以张三在192.168.3.90第一个数据分片上。
说明2:赵六的创建时间不在2023-12-01 至 2023-12-30的时间范围了,所以重新开始以10天为一周期的计算周期,而2023-12-31在新周期的第一个区间,所以赵六也在192.168.3.90第一个数据分片上。
说明3:侯七的创建时间不在2023-12-01 至 2023-12-30的时间范围了,所以重新开始以10天为一周期的计算周期,而2024-01-01在新周期的第一个区间,所以侯七也在192.168.3.90第一个数据分片上。

说明4:李四的创建时间为2023-12-12在2023-12-11 至 2023-12-20之间,所以张三在192.168.3.91第二个数据分片上。
说明5:孙八的创建时间不在2023-12-01 至 2023-12-30的时间范围了,所以重新开始以10天为一周期的计算周期,而2024-01-11在新周期的第二个区间,所以孙八也在192.168.3.91第二个数据分片上。

说明6:王五的创建时间为2023-12-22在2023-12-21 至 2023-12-30之间,所以王五在192.168.3.92第三个数据分片上。
说明7:周九的创建时间不在2023-12-01 至 2023-12-30的时间范围了,所以重新开始以10天为一周期的计算周期,而2024-01-21在新周期的第三个区间,所以周九也在192.168.3.92第三个数据分片上。
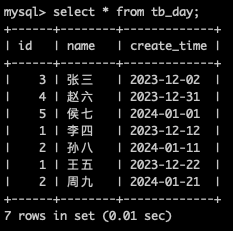
说明8:在Mycat上进行查询的数据是,所有数据节点的全集。按(天)日期分片是水平分库分表的一种方式。
MySQL运维12-Mycat分库分表之按天分片的更多相关文章
- Mysql系列五:数据库分库分表中间件mycat的安装和mycat配置详解
一.mycat的安装 环境准备:准备一台虚拟机192.168.152.128 1. 下载mycat cd /softwarewget http:-linux.tar.gz 2. 解压mycat tar ...
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- mycat分库分表 看这一篇就够了
之前我们已经讲解过了数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- (转) MySQL分区与传统的分库分表
传统的分库分表 原文:http://blog.csdn.net/kobejayandy/article/details/54799579 传统的分库分表都是通过应用层逻辑实现的,对于数据库层面来说,都 ...
随机推荐
- 基于velero及minio实现etcd数据备份与恢复
1.Velero简介 Velero 是vmware开源的一个云原生的灾难恢复和迁移工具,它本身也是开源的,采用Go语言编写,可以安全的备份.恢复和迁移Kubernetes集群资源数据:官网https: ...
- 领域驱动设计(DDD):DDD落地问题和一些解决方法
欢迎继续关注本系列文章,下面我们继续讲解下DDD在实战落地时候,会具体碰到哪些问题,以及解决的方式有哪些. DDD 是一种思想,主要知道我们方向,具体如何做,需要我们根据业务场景具体问题具体分析. 充 ...
- 在微服务环境下,远程调用feign和异步线程存在请求数据丢失问题
一.无异步线程得情况下feign远程调用: 0.登录拦截器: @Component public class LoginUserInterceptor implements HandlerInterc ...
- SQL查询中的小技巧:SELECT 1 和 LIMIT 1 替代 count(*)
前言 在写SQL查询时,常规做法是使用SELECT count(*)来统计符合条件的记录数. 然而,在某些情况下,我们只关心是否存在符合条件的记录,而不需要知道具体的记录数. 为了优化性能,可以改用使 ...
- 【接口自动化测试】Eolink Apilkit 安装部署,支持 Windows、Mac、Linux 等系统
Eolink Apikit 有三种客户端,可以依据自己的情况选择.三种客户端的数据是共用的,因此可以随时切换不同的客户端. 我们推荐使用新推出的 Apikit PC 客户端,PC 端拥有线上产品所有的 ...
- JavaAgent寄生在目标进程中引起的ClassNotFoundException
今天有解决方案部的小伙伴反映,我公司XWind产品在分析客户应用程序的潜在性能问题时,总是显现诊断任务异常,为了定位问题的根因,我们马上要求解决方案部的小伙伴提供XWind相关的日志,从日志中找到了如 ...
- 08-03_阅读flask上下文前夕补充、flask请求上下文、数据库连接池
文章目录 阅读flask上下文前夕补充 01 偏函数 02 __add__的使用 03 chain函数 2 flask请求上下文 1 首先分析请求上下文对象(ctx)创立 2 把请求对象(ctx)添加 ...
- 文心一言 VS 讯飞星火 VS chatgpt (108)-- 算法导论10.1 6题
六.用go语言,说明如何用两个栈实现一个队列,并分析相关队列操作的运行时间. 文心一言: 使用两个栈实现队列的基本思想是利用一个栈(stack1)来处理入队操作,另一个栈(stack2)来处理出队操作 ...
- MySQL误删恢复方法1
MySQL不同于oracle,没有闪回查询这类概念,但网上流传几个闪回的开源工具如 binglog2sql.MyFlash,可以使用binglog日志进行误操作数据的恢复. 笔者以前测试过 bingl ...
- 使用LiME收集主机物理内存的内容时发生宕机
作者 pengdonglin137@163.com 现象 在一台ARM64的Centos7虚拟机里加载 https://github.com/504ensicsLabs/LiME 编译出的内核模块时发 ...