神经网络之卷积篇:详解经典网络(Classic networks)
详解经典网络
首先看看LeNet-5的网络结构,假设有一张32×32×1的图片,LeNet-5可以识别图中的手写数字,比如像这样手写数字7。LeNet-5是针对灰度图片训练的,所以图片的大小只有32×32×1。实际上LeNet-5的结构和上篇博客的最后一个范例非常相似,使用6个5×5的过滤器,步幅为1。由于使用了6个过滤器,步幅为1,padding为0,输出结果为28×28×6,图像尺寸从32×32缩小到28×28。然后进行池化操作,在这篇论文写成的那个年代,人们更喜欢使用平均池化,而现在可能用最大池化更多一些。在这个例子中,进行平均池化,过滤器的宽度为2,步幅为2,图像的尺寸,高度和宽度都缩小了2倍,输出结果是一个14×14×6的图像。觉得这张图片应该不是完全按照比例绘制的,如果严格按照比例绘制,新图像的尺寸应该刚好是原图像的一半。

接下来是卷积层,用一组16个5×5的过滤器,新的输出结果有16个通道。LeNet-5的论文是在1998年撰写的,当时人们并不使用padding,或者总是使用valid卷积,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小,所以这个图像从14到14缩小到了10×10。然后又是池化层,高度和宽度再缩小一半,输出一个5×5×16的图像。将所有数字相乘,乘积是400。
下一层是全连接层,在全连接层中,有400个节点,每个节点有120个神经元,这里已经有了一个全连接层。但有时还会从这400个节点中抽取一部分节点构建另一个全连接层,就像这样,有2个全连接层。
最后一步就是利用这84个特征得到最后的输出,还可以在这里再加一个节点用来预测\(\hat{y}\)的值,\(\hat{y}\)有10个可能的值,对应识别0-9这10个数字。在现在的版本中则使用softmax函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
相比现代版本,这里得到的神经网络会小一些,只有约6万个参数。而现在,经常看到含有一千万到一亿个参数的神经网络,比这大1000倍的神经网络也不在少数。
不管怎样,如果从左往右看,随着网络越来越深,图像的高度和宽度在缩小,从最初的32×32缩小到28×28,再到14×14、10×10,最后只有5×5。与此同时,随着网络层次的加深,通道数量一直在增加,从1增加到6个,再到16个。
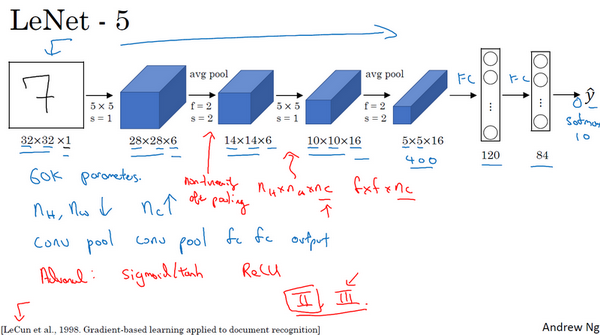
这个神经网络中还有一种模式至今仍然经常用到,就是一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后是全连接层,最后是输出,这种排列方式很常用。
对于那些想尝试阅读论文的读者,再补充几点。接下来的部分主要针对那些打算阅读经典论文的读者,所以会更加深入。这些内容完全可以跳过,算是对神经网络历史的一种回顾吧,听不懂也不要紧。
读到这篇经典论文时,会发现,过去,人们使用sigmod函数和tanh函数,而不是ReLu函数,这篇论文中使用的正是sigmod函数和tanh函数。这种网络结构的特别之处还在于,各网络层之间是有关联的,这在今天看来显得很有趣。
比如说,有一个\(n_{H} \times n_{W} \times n_{C}\)的网络,有\(n_{C}\)个通道,使用尺寸为\(f×f×n_{C}\)的过滤器,每个过滤器的通道数和它上一层的通道数相同。这是由于在当时,计算机的运行速度非常慢,为了减少计算量和参数,经典的LeNet-5网络使用了非常复杂的计算方式,每个过滤器都采用和输入模块一样的通道数量。论文中提到的这些复杂细节,现在一般都不用了。
认为当时所进行的最后一步其实到现在也还没有真正完成,就是经典的LeNet-5网络在池化后进行了非线性函数处理,在这个例子中,池化层之后使用了sigmod函数。如果真的去读这篇论文,这会是最难理解的部分之一。
下面的网络结构简单一些,幻灯片的大部分类容来自于原文的第二段和第三段,原文的后几段介绍了另外一种思路。文中提到的这种图形变形网络如今并没有得到广泛应用,所以在读这篇论文的时候,建议精读第二段,这段重点介绍了这种网络结构。泛读第三段,这里面主要是一些有趣的实验结果。
要举例说明的第二种神经网络是AlexNet,是以论文的第一作者Alex Krizhevsky的名字命名的,另外两位合著者是ilya Sutskever和Geoffery Hinton。
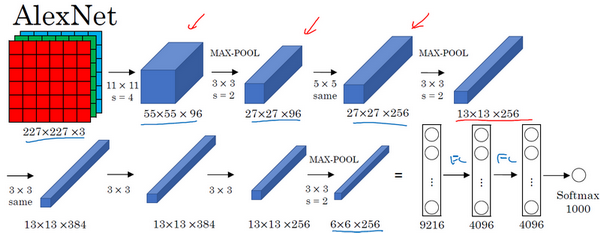
AlexNet首先用一张227×227×3的图片作为输入,实际上原文中使用的图像是224×224×3,但是如果尝试去推导一下,会发现227×227这个尺寸更好一些。第一层使用96个11×11的过滤器,步幅为4,由于步幅是4,因此尺寸缩小到55×55,缩小了4倍左右。然后用一个3×3的过滤器构建最大池化层,\(f=3\),步幅\(s\)为2,卷积层尺寸缩小为27×27×96。接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。再执行一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。再做一次same卷积,就像这样。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
实际上,这种神经网络与LeNet有很多相似之处,不过AlexNet要大得多。正如前面提到的LeNet或LeNet-5大约有6万个参数,而AlexNet包含约6000万个参数。当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据,这一点AlexNet表现出色。AlexNet比LeNet表现更为出色的另一个原因是它使用了ReLu激活函数。

第一点,在写这篇论文的时候,GPU的处理速度还比较慢,所以AlexNet采用了非常复杂的方法在两个GPU上进行训练。大致原理是,这些层分别拆分到两个不同的GPU上,同时还专门有一个方法用于两个GPU进行交流。

论文还提到,经典的AlexNet结构还有另一种类型的层,叫作“局部响应归一化层”(Local Response Normalization),即LRN层,这类层应用得并不多。局部响应归一层的基本思路是,假如这是网络的一块,比如是13×13×256,LRN要做的就是选取一个位置,比如说这样一个位置,从这个位置穿过整个通道,能得到256个数字,并进行归一化。进行局部响应归一化的动机是,对于这张13×13的图像中的每个位置来说,可能并不需要太多的高激活神经元。但是后来,很多研究者发现LRN起不到太大作用,这应该是被划掉的内容之一,因为并不重要,而且现在并不用LRN来训练网络。
如果对深度学习的历史感兴趣的话,认为在AlexNet之前,深度学习已经在语音识别和其它几个领域获得了一些关注,但正是通过这篇论文,计算机视觉群体开始重视深度学习,并确信深度学习可以应用于计算机视觉领域。此后,深度学习在计算机视觉及其它领域的影响力与日俱增。
AlexNet网络结构看起来相对复杂,包含大量超参数,这些数字(55×55×96、27×27×96、27×27×256……)都是Alex Krizhevsky及其合著者不得不给出的。
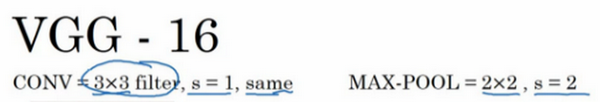
第三个,也是最后一个范例是VGG,也叫作VGG-16网络。值得注意的一点是,VGG-16网络没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。首先用3×3,步幅为1的过滤器构建卷积层,padding参数为same卷积中的参数。然后用一个2×2,步幅为2的过滤器构建最大池化层。因此VGG网络的一大优点是它确实简化了神经网络结构。
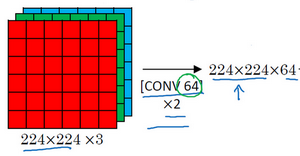
假设要识别这个图像,在最开始的两层用64个3×3的过滤器对输入图像进行卷积,输出结果是224×224×64,因为使用了same卷积,通道数量也一样。VGG-16其实是一个很深的网络,这里并没有把所有卷积层都画出来。

假设这个小图是输入图像,尺寸是224×224×3,进行第一个卷积之后得到224×224×64的特征图,接着还有一层224×224×64,得到这样2个厚度为64的卷积层,意味着用64个过滤器进行了两次卷积。正如在前面提到的,这里采用的都是大小为3×3,步幅为1的过滤器,并且都是采用same卷积,所以就不再把所有的层都画出来了,只用一串数字代表这些网络。
接下来创建一个池化层,池化层将输入图像进行压缩,从224×224×64缩小到多少呢?没错,减少到112×112×64。然后又是若干个卷积层,使用129个过滤器,以及一些same卷积,看看输出什么结果,112×112×128.然后进行池化,可以推导出池化后的结果是这样(56×56×128)。接着再用256个相同的过滤器进行三次卷积操作,然后再池化,然后再卷积三次,再池化。如此进行几轮操作后,将最后得到的7×7×512的特征图进行全连接操作,得到4096个单元,然后进行softmax激活,输出从1000个对象中识别的结果。
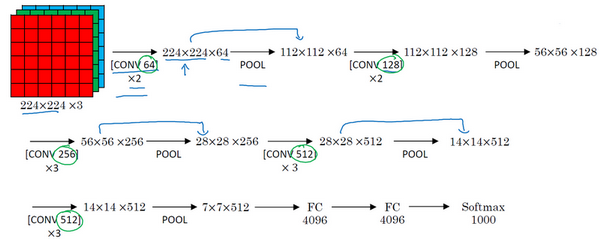
顺便说一下,VGG-16的这个数字16,就是指在这个网络中包含16个卷积层和全连接层。确实是个很大的网络,总共包含约1.38亿个参数,即便以现在的标准来看都算是非常大的网络。但VGG-16的结构并不复杂,这点非常吸引人,而且这种网络结构很规整,都是几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。同时,卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512。作者可能认为512已经足够大了,所以后面的层就不再翻倍了。无论如何,每一步都进行翻倍,或者说在每一组卷积层进行过滤器翻倍操作,正是设计此种网络结构的另一个简单原则。这种相对一致的网络结构对研究者很有吸引力,而它的主要缺点是需要训练的特征数量非常巨大。

有些文章还介绍了VGG-19网络,它甚至比VGG-16还要大,如果想了解更多细节,请参考幻灯片下方的注文,阅读由Karen Simonyan和Andrew Zisserman撰写的论文。由于VGG-16的表现几乎和VGG-19不分高下,所以很多人还是会使用VGG-16。最喜欢它的一点是,文中揭示了,随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍。也就是说,图像缩小的比例和通道数增加的比例是有规律的。从这个角度来看,这篇论文很吸引人。
以上就是三种经典的网络结构,如果对这些论文感兴趣,建议从介绍AlexNet的论文开始,然后就是VGG的论文,最后是LeNet的论文。虽然有些晦涩难懂,但对于了解这些网络结构很有帮助。
神经网络之卷积篇:详解经典网络(Classic networks)的更多相关文章
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- http协议详解-经典篇
本文转载至 http://www.cnblogs.com/flychen/archive/2012/11/28/2792206.html ————————————————————————————— ...
- 详解ResNet 网络,如何让网络变得更“深”了
摘要:残差网络(ResNet)的提出是为了解决深度神经网络的"退化"(优化)问题.ResNet 通过设计残差块结构,调整模型结构,让更深的模型能够有效训练更训练. 本文分享自华为云 ...
- HTTP协议详解(经典)
转自:http://blog.csdn.net/gueter/archive/2007/03/08/1524447.aspx Author :Jeffrey 引言 HTTP是一个属于应用层的面向对象的 ...
- 一文详解 WebSocket 网络协议
WebSocket 协议运行在TCP协议之上,与Http协议同属于应用层网络数据传输协议.WebSocket相比于Http协议最大的特点是:允许服务端主动向客户端推送数据(从而解决Http 1.1协议 ...
- Oracle10g数据泵impdp参数详解--摘自网络
Oracle10g数据泵impdp参数详解 2011-6-30 12:29:05 导入命令Impdp • ATTACH 连接到现有作业, 例如 ATTACH [=作业名]. • C ...
- 神经网络基础部件-BN层详解
一,数学基础 1.1,概率密度函数 1.2,正态分布 二,背景 2.1,如何理解 Internal Covariate Shift 2.2,Internal Covariate Shift 带来的问题 ...
随机推荐
- 【JavaWeb】HttpClient
需要的依赖: <!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --> <de ...
- conda环境下安装nvidia-nvcc
参考: https://www.cnblogs.com/littletreee/p/17234053.html conda安装Pytorch或TensorFlow的时候是默认不安装nvcc,但是有时候 ...
- mujoco_py.cymj.GlfwError: Failed to initialize GLFW
安装mujoco后运行可视化界面代码报错: mujoco_py.cymj.GlfwError: Failed to initialize GLFW 解决方法: sudo apt-get install ...
- 推荐一个优秀的 .NET MAUI 组件库
前言 .NET MAUI 的发布,项目中可以使用这个新的跨平台 UI 框架来轻松搭建的移动和桌面应用. 为了帮助大家更快地构建美观且功能丰富的应用,本文将推荐一款优秀的 .NET MAUI 组件库MD ...
- 2023 ICPC 合肥游记
board zsy 11.24 开始嗓子疼了,但可以忍受.晚上睡的很不舒服 11.25 起床就开始难受,还得骑车到地铁站,应该打个车来着.不过路上拍到了很好看的朝霞(写到这里才想起来还没发朋友圈给 t ...
- NetCore消息管道 Middleware
中间件定义 /// <summary> /// 自定义中间件1 /// </summary> public class MyMiddleware : IMiddleware { ...
- Blazor开发框架Known-V2.0.9
V2.0.9 Known是基于Blazor的企业级快速开发框架,低代码,跨平台,开箱即用,一处代码,多处运行.本次版本主要是修复一些BUG和表格页面功能增强. 官网:http://known.puma ...
- 使用 nuxi add 快速创建 Nuxt 应用组件
title: 使用 nuxi add 快速创建 Nuxt 应用组件 date: 2024/8/28 updated: 2024/8/28 author: cmdragon excerpt: 通过使用 ...
- Linux 内核相关命令
Shell 命令: ipcs # 查看共享内存 dmesg # 显示内核消息 sudo dmesg -c # 清空内核消息 sudo mknod /dev/rwbuf c 60 0 sudo insm ...
- 安卓系统使用chrome插件(以yandex安装油猴为例)
以tampermonkey为代表的Chrome插件广受好评,但由于Chrome在安卓系统并不支持令人遗憾.所以带来安卓手机使用Chrome插件的教程. 一,首先下载安卓开源浏览器(个人推荐yandex ...