华为云HBase冷热分离最佳实践
本文分享自华为云社区《华为云HBase 冷热分离最佳实践》,作者:pippo。
HBase介绍
HBase是Hadoop Database的简称,是建立在Hadoop文件系统之上的分布式面向列的数据库,它具有高可靠、高性能、面向列和可伸缩的特性,提供快速随机访问海量数据能力。
HBase采用Master/Slave架构,由HMaster节点、RegionServer节点、ZooKeeper集群组成,底层数据存储在HDFS上。
整体架构如图所示:

HMaster主要负责:
- 在HA模式下,包含主用Master和备用Master。
- 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
- 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
RegionServer主要负责:
- 存放和管理本地HRegion。
- RegionServer负责提供表数据读写等服务,是HBase的数据处理和计算单元,直接与Client交互。
- RegionServer一般与HDFS集群的DataNode部署在一起,实现数据的存储功能。读写HDFS,管理Table中的数据。
ZooKeeper集群主要负责:
- 存放整个 HBase集群的元数据以及集群的状态信息。
- 实现HMaster主从节点的Failover。
HDFS集群主要负责:
- HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
结构说明:
Store
- 一个Region由一个或多个Store组成,每个Store对应图中的一个Column Family。
MemStore
- 一个Store包含一个MemStore,MemStore缓存客户端向Region插入的数据,当RegionServer中的MemStore大小达到配置的容量上限时,RegionServer会将MemStore中的数据“flush”到HDFS中。
StoreFile
- MemStore的数据flush到HDFS后成为StoreFile,随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置的阈值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。
HFile
- HFile定义了StoreFile在文件系统中的存储格式,它是当前HBase系统中StoreFile的具体实现。
HLog(WAL)
- HLog日志保证了当RegionServer故障的情况下用户写入的数据不丢失,RegionServer的多个Region共享一个相同的HLog。
HBase提供两种API来写入数据。
- Put:数据直接发送给RegionServer。
- BulkLoad:直接将HFile加载到表存储路径。
HBase 冷热分离诉求
HBase是Hadoop Database的简称,是建立在Hadoop文件系统之上的分布式面向列的数据库,它具有高可靠、高性能、面向列和可伸缩的特性,提供快速随机访问海量数据能力。
在海量大数据场景下,表中的部分业务数据随着时间的推移仅作为归档数据或者访问频率很低,同时这部分历史数据体量非常大,比如订单数据或者监控数据,如果降低这部分数据的存储成本将会极大的节省企业的成本。
冷热分离功能支持将冷热数据存储在不同的介质上,冷数据的存储类型为普通IO存储,热数据的存储类型为超高IO存储。普通IO存储的价格仅为超高IO存储的30%,大大降低了存储成本。
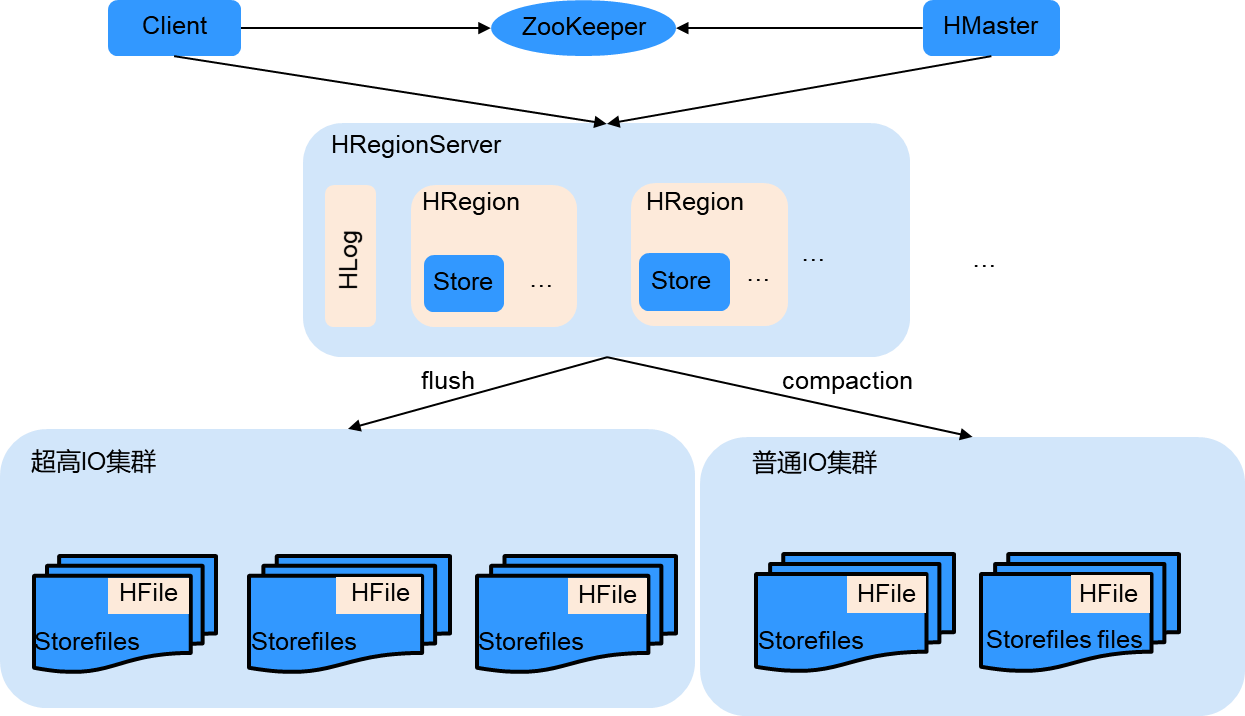
HBase 冷热分离介绍
HBase支持对同一张表的数据进行冷热分离存储。用户在表上配置数据冷热时间分界点后,HBase会依赖用户写入数据的时间戳(毫秒)和时间分界点来判断数据的冷热。数据开始存储在热存储上,随着时间的推移慢慢往冷存储上迁移。同时用户可以任意变更数据的冷热分界点,数据可以从热存储到冷存储,也可以从冷存储到热存储。
整体架构如图所示:
命令介绍
设置表的冷热分界线
创建冷热分离表:
hbase(main):002:0> create 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>'86400'}
参数说明:
NAME:需要冷热分离的列族。
COLD_BOUNDARY:冷热分离时间点,单位为秒(s)。例如COLD_BOUNDARY为86400,代表86400秒(一天)前写入的数据会被自动归档到冷存储。
取消冷热分离。
hbase(main):004:0> alter 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>""}
为已经存在的表设置冷热分离,或者修改冷热分离分界线,单位为秒。
hbase(main):005:0> alter 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>'86400'}
查询冷热分离是否设置或者修改成功
hbase(main):005:0> desc 'hot_cold_table'
数据写入
冷热分离的表与普通表的数据写入方式完全一致,数据会先存储在热存储(超高IO)中。随着时间的推移,如果一行数据满足当前时间-时间列值>COLD_BOUNDARY设置的值条件,则会在执行Compaction时被归档到冷存储(普通IO)中。
插入记录
执行“put”命令往指定表插入一条记录,需要指定表的名称,主键,自定义列,以及插入的具体值。
hbase(main):004:0> put 'hot_cold_table','row1','cf:a','value1'
参数说明:
hot_cold_table:表的名称。
row1:主键。
cf:a:自定义的列。
value1:插入的值。
数据查询
由于冷热数据都在同一张表中,因此用户所有的查询操作都只需在一张表内进行。在查询时,建议通过配置TimeRange来指定查询的时间范围,系统将会根据指定的时间范围决定查询模式,即仅查询热存储、仅查询冷存储或同时查询冷存储和热存储。如果查询时未限定时间范围,则会导致查询冷数据。在这种情况下,查询吞吐量会受到冷存储的限制。
随机查询
不指定HOT_ONLY参数来查询数据。在这种情况下,将会查询冷存储中的数据。
hbase(main):001:0> get 'hot_cold_table', 'row1'
通过指定HOT_ONLY参数来查询数据。在这种情况下,只会查询热存储中的数据。
hbase(main):002:0> get 'hot_cold_table', 'row1', {HOT_ONLY=>true}
通过指定TimeRange参数来查询数据。在这种情况下,CloudTable将会比较TimeRange和冷热边界值,以确定是只查询热存储还是冷存储中的数据,还是同时查询热冷存储中的数据
hbase(main):003:0> get 'hot_cold_table', 'row1', {TIMERANGE => [0, 1568203111265]}
范围查询
不指定HOT_ONLY参数来查询数据。在这种情况下,将会查询冷存储中的数据。
hbase(main):001:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9'}
通过指定HOT_ONLY参数来查询数据。在这种情况下,只会查询热存储中的数据。
hbase(main):002:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9', HOT_ONLY=>true}
通过指定TimeRange参数来查询数据。在这种情况下,CloudTable将会比较TimeRange和冷热边界值,以确定是只查询热存储还是冷存储中的数据,还是同时查询热冷存储中的数据。
hbase(main):003:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9', TIMERANGE => [0, 1568203111265]}
数据合并
- 合并表所有分区的热数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'HOT'
- 合并表所有分区的冷数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'COLD'
- 合并表所有分区的热冷数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'ALL'
HBase 冷热分离效果

华为云HBase冷热分离最佳实践的更多相关文章
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- EntityFramework Core进行读写分离最佳实践方式,了解一下(二)?
前言 写过上一篇关于EF Core中读写分离最佳实践方式后,虽然在一定程度上改善了问题,但是在评论中有的指出更换到从数据库,那么接下来要进行插入此时又要切换到主数据库,同时有的指出是否可以进行底层无感 ...
- EntityFramework Core进行读写分离最佳实践方式,了解一下(一)?
前言 本来打算写ASP.NET Core MVC基础系列内容,看到有园友提出如何实现读写分离,这个问题提的好,大多数情况下,对于园友在评论中提出的问题,如果是值得深究或者大多数同行比较关注的问题我都会 ...
- MaxCompute 构建企业云数据仓库CDW的最佳实践建议
在本文中阿里云资深产品专家云郎分享了基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议. 本文内容根据演讲视频以及PPT整理而成. 大家下午好,我是云郎,之前在甲骨文做企业架构师 ...
- 三艾云 Kubernetes 集群最佳实践
三艾云 Kubernetes 集群最佳实践 三艾云 Kubernetes 集群最佳实践 容器是 Cloud Native 的基石,它们之间的关系不言而喻.了解容器对于学习 Cloud Native 也 ...
- Bulk Load-HBase数据导入最佳实践
一.概述 HBase本身提供了非常多种数据导入的方式,通常有两种经常使用方式: 1.使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 2 ...
- 腾讯云TDSQL PostgreSQL版 -最佳实践 |优化 SQL 语句
查看是否为分布键查询 postgres=# explain select * from tbase_1 where f1=1; QUERY PLAN ------------------------- ...
- TOP100summit:【分享实录-华为】微服务场景下的性能提升最佳实践
本篇文章内容来自2016年TOP100summit华为架构部资深架构师王启军的案例分享.编辑:Cynthia 王启军:华为架构部资深架构师.负责华为的云化.微服务架构推进落地,前后参与了华为手机祥云4 ...
- 华为云Stack新版发布:构筑行业云底座,共创行业新价值
摘要:在以"政企深度用云,释放数字生产力"为主题的华为云Stack战略暨新品发布会上,华为云提出深度用云三大关键举措,并发布华为云Stack 8.2版本,以智能进化推动创造行业新价 ...
- 基于华为云IOT及无线RFID技术的智慧仓储解决方案最佳实践系列一
[摘要]仓储管理存在四大细分场景:出入库管理.盘点.分拣和货物跟踪.本系列将介绍利用华为云IOT全栈云服务,端侧采用华为收发分离式RFID解决方案,打造端到端到IOT智慧仓储解决方案的最佳实践. 仓储 ...
随机推荐
- Python-文件读取过程中每一行后面带一行空行。贼简单!!!!
关键点在于,将open()函数中,参数为w的一行,格式如下: csvfile = open(data_path + '-21w.csv', 'w') 加上一个参数为newline=' ' 格式如下: ...
- 使用Github Copilot完成代码编写
上篇文章,我们使用VSCode创建了T.Global解决方案和两个类库工程,接下来我们使用Github Copilot完成代码编写 先说以下业务需求: 提供一个公共的本地化组件,支持对数字.货币.时间 ...
- mac os 升级到13后,系统免密失败
# sudo vim /etc/ssh/ssh_config # 添加以下内容 PubkeyAcceptedKeyTypes +ssh-rsa
- QT(7)-初识委托
@ 目录 1 简介 2 QT中的委托类 2.1 函数 2.1.1 关键函数 2.1.2 其他函数 3 例子 3.1 官方例子 3.2 修改官方例子 4 设想 1 简介 委托是Qt中的一种机制,用于在Q ...
- JVM-Java虚拟机是怎么实现synchronized的?
1. JVM的锁优化 今天我介绍了 Java 虚拟机中 synchronized 关键字的实现,按照代价由高至低可分为重量级锁.轻量级锁和偏向锁三种. 重量级锁会阻塞.唤醒请求加锁的线程.它针对的是多 ...
- JavaScript 语法:注释与输入 / 输出
作者:WangMin 格言:努力做好自己喜欢的每一件事 JavaScript 注释 JavaScript 注释用于解释 JavaScript 代码,提高代码的可读性,也可以用于在测试替代代码时阻止执行 ...
- 优雅设计之美:实现Vue应用程序的时尚布局
前言 页面布局是减少代码重复和创建可维护且具有专业外观的应用程序的基本模式.如果使用的是Nuxt,则可以提供开箱即用的优雅解决方案.然而,令人遗憾的是,在Vue中,这些问题并未得到官方文档的解决. 经 ...
- PZthon
一道新式题目,python.exe的分析 这个时候没有思路不要紧,直接wp 先用特别的软件执行.exe程序,就是对.exe进行反编译 然后在反编译脚本的目录写就有了一个打包文件夹 在里面找到文件的.p ...
- uni-app学习笔记——路由与页面跳转
小颖最近在学习小程序,怕自己前看后忘,毕竟还没开始进入项目实践中,就自己瞎倒腾嘻嘻,今天来看下 uni-app 的路由与页面跳转,小颖就简单列举下它们的用法,具体的大家可以看官网哦!啦啦啦啦啦 ...
- React Hooks 钩子特性
人在身处逆境时,适应环境的能力实在惊人.人可以忍受不幸,也可以战胜不幸,因为人有着惊人的潜力,只要立志发挥它,就一定能渡过难关. Hooks 是 React 16.8 的新增特性.它可以让你在不编写 ...