谈谈流计算中的『Exactly Once』特性
本文翻译自 streaml.io 网站上的一篇博文:“Exactly once is NOT exactly the same” ,分析了流计算系统中常说的『Exactly Once』特性,主要观点是:『精确一次』并不保证是完全一样。主要内容如下:
背景
1.1. 最多一次(At-most-once)
1.2. 至少一次(At-least-once)
1.3. 精确一次(Exactly-once)
『精确一次』是真正的『精确一次』吗?
分布式快照与至少一次事件传递和重复数据删除的比较
结论
参考
目前市面上使用较多的流计算系统有 Apache Storm,Apache Flink, Heron, Apache Kafka (Kafka Streams) 和 Apache Spark (Spark Streaming)。关于流计算系统有个被广泛讨论的特性是『exactly-once』语义,很多系统宣称已经支持了这一特性。但是,到底什么是『exactly-once』,怎么样才算是实现了『exactly-once』,人们存在很多误解和歧义。接下来我们做下分析。
1. 背景
本文分析了流计算系统中常说的”exactly once”特性,主要观点是:exactly once 并不保证完全一样。
什么是有界数据集和无界数据集?
有界数据:在常规处理之中,我们都会从Mysql等之中拿到信息进行处理,那么处理此类数据的时候,特点是数据为静止不动的,没有进行追加,或者是再处理的时刻不需要考虑追加写入操作。这种又称为批处理,batch processing。
无界数据:对于某些场景而言,类似Kafka的持续计算等等都是无界数据集。无界数据集在处理的当下要发生持续变更,追加等等。这种又称为流计算,Stream Processing。
场景比较:无界数据集和有界数据集,很像池塘和大河,在计算池塘之中的数据时候,只需要将池塘之中当前所有的鱼计算一起就可以了。但是无界数据集,就像江河之中的鱼,在奔流到海的过程之中,每时每刻都有鱼流过而进入大海,那么计算鱼的数量就是持续追加的。
二者的数据集相对而言是一个模糊的概念,将粒度拉细,如果只是一条一条的处理,那么就可以认为是无界的,如果将粒度做粗,在一个时间段之中做一定的数据处理,那么数据又可以认为是有界的。既然二者之间可以互换,那么业界也就开始追寻批流统一的框架。
可以同时实现批处理和流处理的框架有Apache Spark和Apache Flink。
- Apache Spark的流处理场景就是微批场景,也就是会在特定的时间间隔之内发起一起计算,而不是每条都触发计算。
- Apache Flink最终将批处理和流处理混合到同一引擎当中,使用Apache Flink可以同时实现批处理和流处理任务。
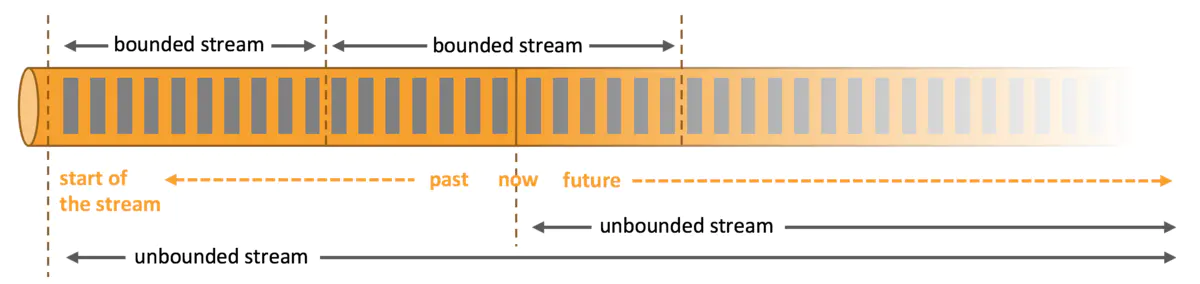
那么,流处理在一般情况下可以简单的描述为对无界数据或者事件的连续处理。
流处理(有时称为事件处理)可以简单地描述为是对无界数据或事件的连续处理。流或事件处理应用程序可以或多或少地被描述为有向图,并且通常被描述为有向无环图(DAG)。在这样的图中,每个边表示数据或事件流,每个顶点表示运算符,会使用程序中定义的逻辑处理来自相邻边的数据或事件。有两种特殊类型的顶点,通常称为 sources 和 sinks。sources读取外部数据/事件到应用程序中,而 sinks 通常会收集应用程序生成的结果。下图是流式应用程序的示例。
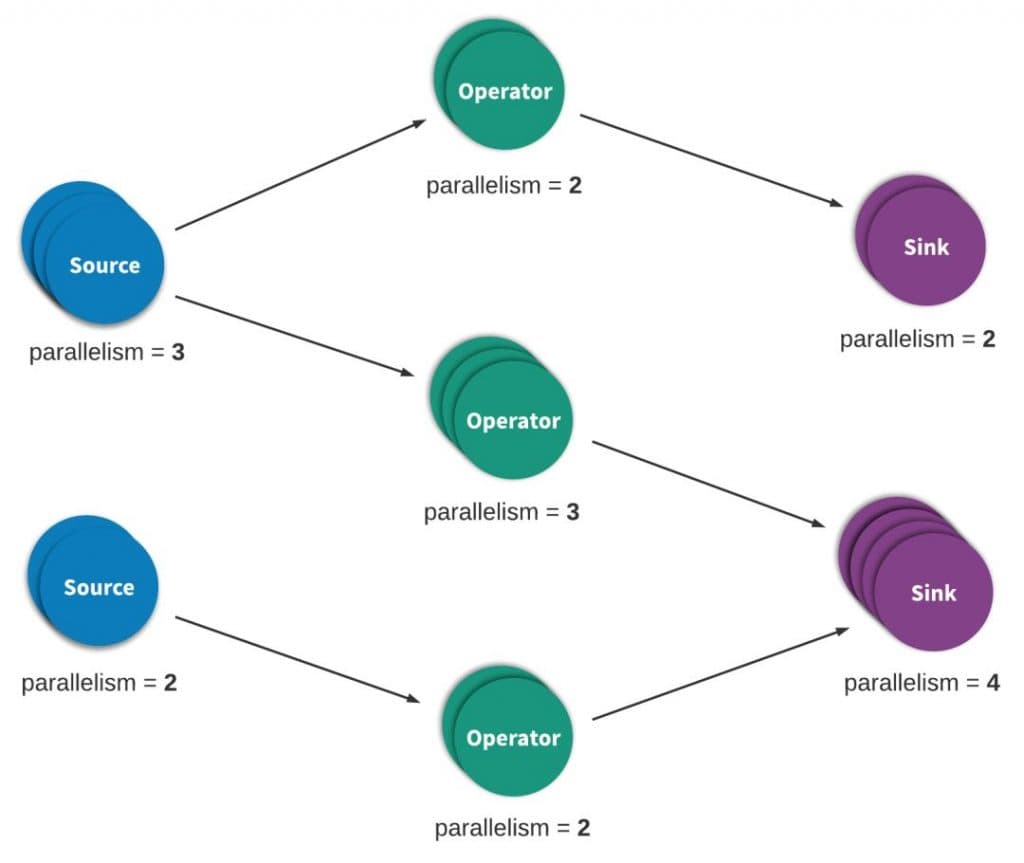 (A typical stream processing topology)
(A typical stream processing topology)
流处理引擎通常允许用户指定可靠性模式或处理语义,以指示它将为整个应用程序中的数据处理提供哪些保证。这些保证是有意义的,因为你始终会遇到由于网络,机器等可能导致数据丢失的故障。流处理引擎通常为应用程序提供了三种数据处理语义:最多一次、至少一次和精确一次。
如下是对这些不同处理语义的宽松定义:
1.1 最多一次(At-most-once)
这本质上是一『尽力而为』的方法。保证数据或事件最多由应用程序中的所有算子处理一次。 这意味着如果数据在被流应用程序完全处理之前发生丢失,则不会进行其他重试或者重新发送。下图中的例子说明了这种情况。
 (At-most-once processing semantics)
(At-most-once processing semantics)
1.2 至少一次(At-least-once)
应用程序中的所有算子都保证数据或事件至少被处理一次。这通常意味着如果事件在流应用程序完全处理之前丢失,则将从源头重放或重新传输事件。然而,由于事件是可以被重传的,因此一个事件有时会被处理多次,这就是所谓的至少一次。
下图的例子描述了这种情况:第一个算子最初未能成功处理事件,然后在重试时成功,接着在第二次重试时也成功了,其实是没有必要的。
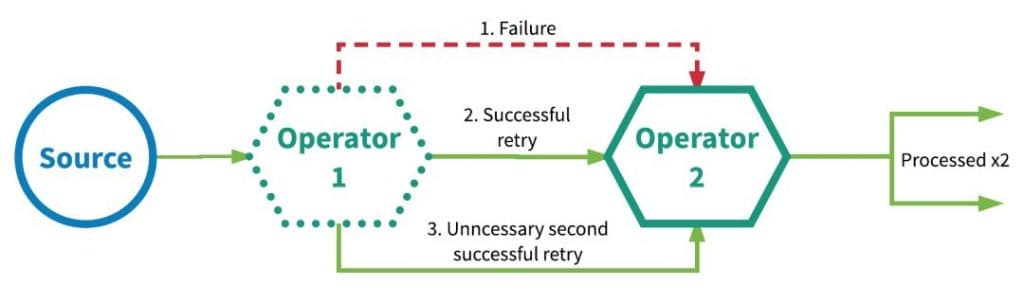 (At-least-once processing semantics )
(At-least-once processing semantics )
1.3 精确一次(Exactly-once)
即使是在各种故障的情况下,流应用程序中的所有算子都保证事件只会被『精确一次』的处理。(也有文章将 Exactly-once 翻译为:完全一次,恰好一次)
通常使用两种流行的机制来实现『精确一次』处理语义。
- 分布式快照 / 状态检查点
- 至少一次事件传递和对重复数据去重
实现『精确一次』的分布式快照/状态检查点方法受到 Chandy-Lamport 分布式快照算法的启发[1]。通过这种机制,流应用程序中每个算子的所有状态都会定期做 checkpoint。如果是在系统中的任何地方发生失败,每个算子的所有状态都回滚到最新的全局一致 checkpoint 点。在回滚期间,将暂停所有处理。源也会重置为与最近 checkpoint 相对应的正确偏移量。整个流应用程序基本上是回到最近一次的一致状态,然后程序可以从该状态重新启动。下图描述了这种 checkpoint 机制的基础知识。
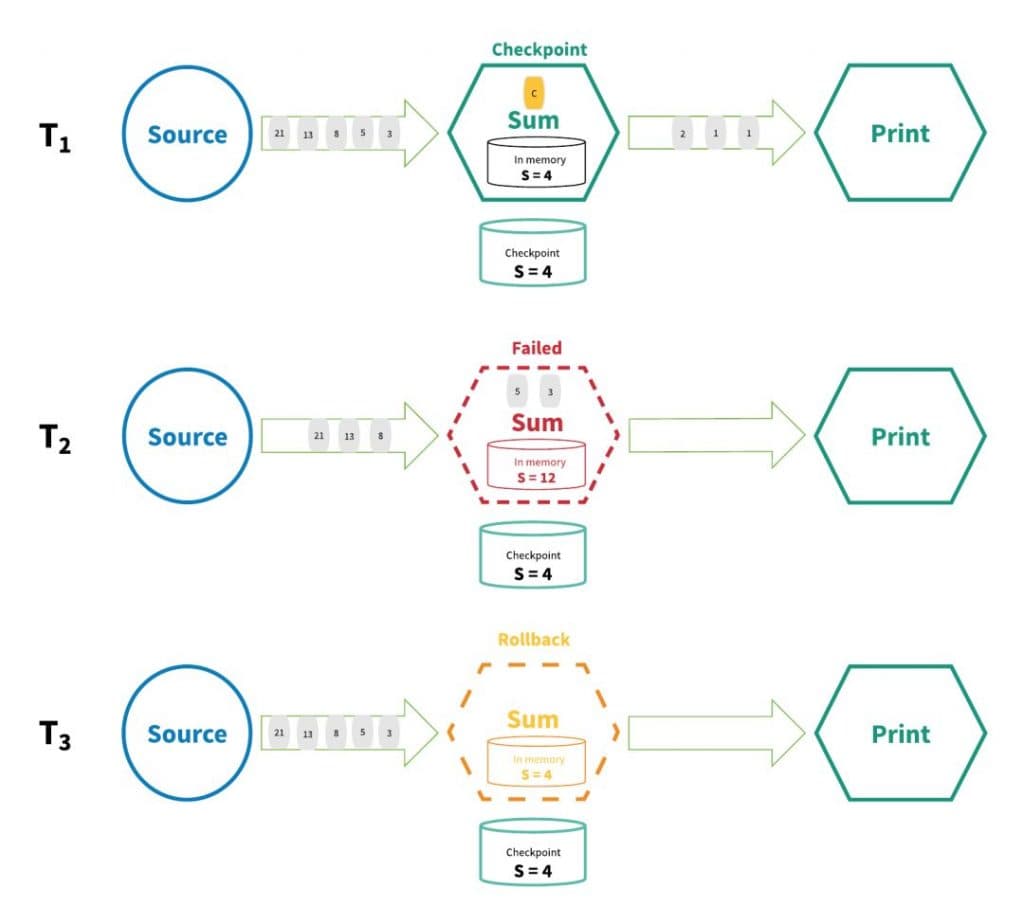 (Distributed snapshot)
(Distributed snapshot)
在上图中,流应用程序在 T1 时间处正常工作,并且做了checkpoint。然而,在时间 T2,算子未能处理输入的数据。此时,S=4 的状态值已保存到持久存储器中,而状态值 S=12 保存在算子的内存中。为了修复这种差异,在时间 T3,处理程序将状态回滚到 S=4 并“重放”流中的每个连续状态直到最近,并处理每个数据。最终结果是有些数据已被处理了多次,但这没关系,因为无论执行了多少次回滚,结果状态都是相同的。
另一种实现『精确一次』的方法是:在每个算子上实现至少一次事件传递和对重复数据去重来。使用此方法的流处理引擎将重放失败事件,以便在事件进入算子中的用户定义逻辑之前,进一步尝试处理并移除每个算子的重复事件。此机制要求为每个算子维护一个事务日志,以跟踪它已处理的事件。利用这种机制的引擎有 Google 的 MillWheel[2] 和 Apache Kafka Streams。下图说明了这种机制的要点。
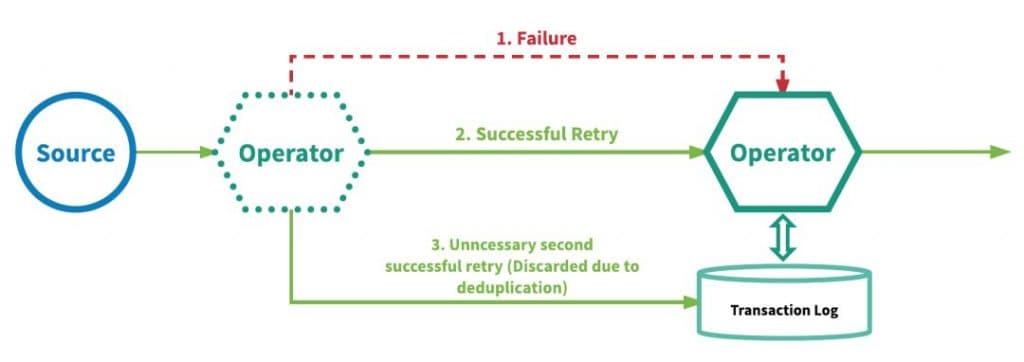 (At-least-once delivery plus deduplication)
(At-least-once delivery plus deduplication)
2. 『精确一次』是真正的『精确一次』吗?
现在让我们重新审视『精确一次』处理语义真正对最终用户的保证。『精确一次』这个术语在描述正好处理一次时会让人产生误导。
有些人可能认为『精确一次』描述了事件处理的保证,其中流中的每个事件只被处理一次。实际上,没有引擎能够保证正好只处理一次。在面对任意故障时,不可能保证每个算子中的用户定义逻辑在每个事件中只执行一次,因为用户代码被部分执行的可能性是永远存在的。
考虑具有流处理运算符的场景,该运算符执行打印传入事件的 ID 的映射操作,然后返回事件不变。下面的伪代码说明了这个操作:
Map (Event event) {
Print "Event ID: " + event.getId()
Return event
}每个事件都有一个 GUID (全局惟一ID)。如果用户逻辑的精确执行一次得到保证,那么事件 ID 将只输出一次。但是,这是无法保证的,因为在用户定义的逻辑的执行过程中,随时都可能发生故障。引擎无法自行确定执行用户定义的处理逻辑的时间点。因此,不能保证任意用户定义的逻辑只执行一次。这也意味着,在用户定义的逻辑中实现的外部操作(如写数据库)也不能保证只执行一次。此类操作仍然需要以幂等的方式执行。
那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储。
上面描述的两种机制都使用持久的后端存储作为真实性的来源,可以保存每个算子的状态并自动向其提交更新。对于机制 1 (分布式快照 / 状态检查点),此持久后端状态用于保存流应用程序的全局一致状态检查点(每个算子的检查点状态)。对于机制 2 (至少一次事件传递加上重复数据删除),持久后端状态用于存储每个算子的状态以及每个算子的事务日志,该日志跟踪它已经完全处理的所有事件。
提交状态或对作为真实来源的持久后端应用更新可以被描述为恰好发生一次。然而,如上所述,计算状态的更新 / 更改,即处理在事件上执行任意用户定义逻辑的事件,如果发生故障,则可能不止一次地发生。换句话说,事件的处理可以发生多次,但是该处理的效果只在持久后端状态存储中反映一次。因此,我们认为有效地描述这些处理语义最好的术语是『有效一次』(effectively once)。
3. 分布式快照与至少一次事件传递和重复数据删除的比较
从语义的角度来看,分布式快照和至少一次事件传递以及重复数据删除机制都提供了相同的保证。然而,由于两种机制之间的实现差异,存在显着的性能差异。
机制 1(分布式快照 / 状态检查点)的性能开销是最小的,因为引擎实际上是往流应用程序中的所有算子一起发送常规事件和特殊事件,而状态检查点可以在后台异步执行。但是,对于大型流应用程序,故障可能会更频繁地发生,导致引擎需要暂停应用程序并回滚所有算子的状态,这反过来又会影响性能。流式应用程序越大,故障发生的可能性就越大,因此也越频繁,反过来,流式应用程序的性能受到的影响也就越大。然而,这种机制是非侵入性的,运行时需要的额外资源影响很小。
机制 2(至少一次事件传递加重复数据删除)可能需要更多资源,尤其是存储。使用此机制,引擎需要能够跟踪每个算子实例已完全处理的每个元组,以执行重复数据删除,以及为每个事件执行重复数据删除本身。这意味着需要跟踪大量的数据,尤其是在流应用程序很大或者有许多应用程序在运行的情况下。执行重复数据删除的每个算子上的每个事件都会产生性能开销。但是,使用这种机制,流应用程序的性能不太可能受到应用程序大小的影响。对于机制 1,如果任何算子发生故障,则需要发生全局暂停和状态回滚;对于机制 2,失败的影响更加局部性。当在算子中发生故障时,可能尚未完全处理的事件仅从上游源重放/重传。性能影响与流应用程序中发生故障的位置是隔离的,并且对流应用程序中其他算子的性能几乎没有影响。从性能角度来看,这两种机制的优缺点如下。
分布式快照 / 状态检查点的优缺点:
优点:
– 较小的性能和资源开
缺点:
– 对性能的影响较大
– 拓扑越大,对性能的潜在影响越大
至少一次事件传递以及重复数据删除机制的优缺点:
优点:
– 故障对性能的影响是局部的
– 故障的影响不一定会随着拓扑的大小而增加
缺点:
– 可能需要大量的存储和基础设施来支持
– 每个算子的每个事件的性能开销
虽然从理论上讲,分布式快照和至少一次事件传递加重复数据删除机制之间存在差异,但两者都可以简化为至少一次处理加幂等性。对于这两种机制,当发生故障时(至少实现一次),事件将被重放/重传,并且通过状态回滚或事件重复数据删除,算子在更新内部管理状态时本质上是幂等的。
4. kafka 是如何实现的呢
这个特性是怎么实现的呢?在底层,它和TCP的工作原理有点像,每一批发送到Kafka的消息都将包含一个序列号,broker将使用这个序列号来删除重复的发送。和只能在瞬态内存中的连接中保证不重复的TCP不同,这个序列号被持久化到副本日志,所以,即使分区的leader挂了,其他的broker接管了leader,新leader仍可以判断重新发送的是否重复了。这种机制的开销非常低:每批消息只有几个额外的字段。你将在这篇文章的后面看到,这种特性比非幂等的生产者只增加了可忽略的性能开销。
可见是使用第二种方式。
5. 结论
在这篇博客文章中,我希望能够让你相信『精确一次』这个词是非常具有误导性的。提供『精确一次』的处理语义实际上意味着流处理引擎管理的算子状态的不同更新只反映一次。『精确一次』并不能保证事件的处理,即任意用户定义逻辑的执行,只会发生一次。我们更喜欢用『有效一次』(effectively once)这个术语来表示这种保证,因为处理不一定保证只发生一次,但是对引擎管理的状态的影响只反映一次。两种流行的机制,分布式快照和重复数据删除,被用来实现精确/有效的一次性处理语义。这两种机制为消息处理和状态更新提供了相同的语义保证,但是在性能上存在差异。这篇文章并不是要让你相信任何一种机制都优于另一种,因为它们各有利弊。
6. 参考
Chandy, K. Mani and Leslie Lamport.Distributed snapshots: Determining global states of distributed systems. ACMTransactions on Computer Systems (TOCS) 3.1 (1985): 63-75.
Akidau, Tyler, et al. MillWheel:Fault-tolerant stream processing at internet scale. Proceedings of the VLDBEndowment 6.11 (2013): 1033-1044.
参考:
- https://flink-learning.org.cn/article/detail/8f5e2d15facb1a0423b333d6f1a8dee5
- https://timzhouyes.github.io/2020/07/07/ExactOnce%E7%B2%BE%E7%A1%AE%E4%B8%80%E6%AC%A1/
谈谈流计算中的『Exactly Once』特性的更多相关文章
- 《Kafka Stream》调研:一种轻量级流计算模式
原文链接:https://yq.aliyun.com/articles/58382 摘要: 流计算,已经有Storm.Spark,Samza,包括最近新起的Flink,Kafka为什么再自己做一套流计 ...
- 【翻译】Jay Kreps - 为何流处理中局部状态是必要的
译者注: 原文作者是 Jay Kreps,也是那篇著名的<The Log: What every software engineer should know about real-time da ...
- (转)谈谈RTP传输中的负载类型和时间戳
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://ticktick.blog.51cto.com/823160/350142 最近被 ...
- 【FFMPEG】谈谈RTP传输中的负载类型和时间戳
谈谈RTP传输中的负载类型和时间戳 最近被RTP的负载类型和时间戳搞郁闷了,一个问题调试了近一周,终于圆满解决,回头看看,发现其实主要原因还是自己没有真正地搞清楚RTP协议中负载类型和时间戳的含义.虽 ...
- 今天谈谈流,什么是IO流?
无标题 (5) :first-child { margin-top: 0; } blockquote > :last-child { margin-bottom: 0; } img { bord ...
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- 使用Python的yield实现流计算模式
首先先提一下上一篇<如何猜出Y combinator>中用的方法太复杂了.其实在Lambda演算中实现递归的思想很简单,就是函数把自己作为第一个参数传入函数,然后后面就是简单的Lambda ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
随机推荐
- 解决连接MySQL,报错10061,系统错误5
mysql登录不上去,报错10061,百度后得,mysql服务未启动.. 方法一.选择dos窗口命令行打开mysql 输入代码 net start mysql 报错,如图所示.系统错误 5 解决办法: ...
- Java List集合根据某字段去重
去重方法 单个字段为条件去重 /** * 单字段去重 * @param jackpotList1 新集合 * @param jackpotList 需要去重的集合 * @return */ priva ...
- radware 相关(alteon产品)
目录 术语 组网 配置思路 IP 规划 负载均衡器的IP规划 服务器的IP规划 登陆设备 简单命令行配置 Main Menu 管理IP 确认设备版本 telnet/sshd/http enable 网 ...
- 2023-08-02:给定一棵树,一共有n个点, 每个点上没有值,请把1~n这些数字,不重复的分配到二叉树上, 做到 : 奇数层节点的值总和 与 偶数层节点的值总和 相差不超过1。 返回奇数层节点分配
2023-08-02:给定一棵树,一共有n个点, 每个点上没有值,请把1~n这些数字,不重复的分配到二叉树上, 做到 : 奇数层节点的值总和 与 偶数层节点的值总和 相差不超过1. 返回奇数层节点分配 ...
- ois七层模型与数据封装过程
一,ois七层模型 一,ois七层模型1 为什么要分层2 七层模型3 七层总结二,协议,端口,的作用2.1协议作用2.2tcp/udp的区别2.3ARP 协议的作用2.4客户端与服务端的作用2.5ic ...
- 连续下雨天,.net开发者如何预防流感
最近连续下了3天雨,天气变化大,很容易引发感冒咳嗽等疾病.对于.NET技术开发人员来说,如何保持身体健康,保证工作效率是一个很重要的问题. 首先,我们需要注意保持室内空气流通,避免长时间处于封闭的空间 ...
- vue3 组合式 api 单文件组件写法
1 Vue3 组合式 API 的基本原理和理念 1.1 Vue3 中的 Composition API Vue3 中的 Composition API 是一种新的编写组件逻辑的方式,它提供了更好的代码 ...
- 20款VS Code实用插件推荐
前言 VS Code是一个轻量级但功能强大的源代码编辑器,轻量级指的是下载下来的VS Code其实就是一个简单的编辑器,强大指的是支持多种语言的环境插件拓展,也正是因为这种支持插件式安装环境开发让VS ...
- [ABC145E] All-you-can-eat
2023-02-25 题目 题目传送门 翻译 翻译 难度&重要性(1~10):5 题目来源 AtCoder 题目算法 背包dp 解题思路 设 \(dp_i\) 为最后一道菜在第 \(i\) 时 ...
- 《深入理解Java虚拟机》读书笔记: 类加载器
类加载器 虚拟机设计团队把类加载阶段中的"通过一个类的全限定名来获取描述 ...