[转帖]Linux Page cache和Buffer cache
https://www.cnblogs.com/hongdada/p/16926655.html
free 命令常用参数
free 命令用来查看内存使用状况,常用参数如下:
-hhuman-readable 格式打印-w把 cache & buffer 分开打印-tshow total for RAM + swap
free 结果指标剖析
centos6中,cache,buffers是分开的,7以后就合并了,cache/buffers
[root@10-23-220-95 ~]# free -hwt
total used free shared buffers cache available
Mem: 7.6G 2.0G 3.3G 384M 0B 2.3G 4.9G
Swap: 511M 114M 397M
Total: 8.1G 2.1G 3.7G
Mem total 表示总计可用的物理内存大小
used 表示分配给进程的内存大小
free 未使用的内存大小
cache/buffers 是操作系统用来做缓存的内存占用,未被使用的内存不能白白浪费,操作系统会拿它用作缓存以此提升性能
total = used + free + cache/buffers。当 free 内存被用完后,cache/buffers 会释放一些供应用程序使用,所以 available (可用内存空间)要比 free 大一些。
Swap 是磁盘上划分出来供内存使用的空间,经常不用的东西没必要放在内存里,可以把它置换到外存中,需要的时候再加载的内存。
buffers/cache 进一步理解
当我们使用 free -th -w 查看主机内存信息的时候,常会发现 buffers/cache 占了许多内存空间。这些占用是用来做什么的呢?什么时候我需要扩内存了呢?
其实,buffers/cache 用掉的空间是用来做磁盘页缓存的,它使得系统运转更加快速。除了使得新手迷惑以外,没有其他任何弊端。buffers/cache 不会与应用程序争抢内存空间,只要应用程序需要等多的内存,它就把用来做磁盘页缓存的内存段归还回去,给到应用程序使用。
什么时候开始真正小心内存不够用了?
available memory接近于 0swap used增长或者波动dmesg | grep oom-killer能够查看到OutOfMemory-killer在工作
shared memory 的理解
root@cloud:~ # free -t
total used free shared buff/cache available
Mem: 131106128 6740848 113822952 1376104 10542328 122002484
Swap: 0 0 0
Total: 131106128 6740848 113822952
通过 free 的输出可以看到,有一列 shared 项。free 命令的信息来源是 /proc/meminfo,shared 列的数据来自于 Shmem 部分。
root@cloud:~ # cat /proc/meminfo | grep Shmem
Shmem: 1376104 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
shared memory 统计的是被 tmpfs 所使用的内存大小。我们可以通过 df -t 来查看 tmpfs 所站的空间大小
root@cloud:~ # df -T | grep tmpfs
udev devtmpfs 65538520 0 65538520 0% /dev
tmpfs tmpfs 13110616 1375724 11734892 11% /run
tmpfs tmpfs 65553064 340 65552724 1% /dev/shm
tmpfs tmpfs 5120 0 5120 0% /run/lock
tmpfs tmpfs 65553064 0 65553064 0% /sys/fs/cgroup
shm tmpfs 65536 0 65536 0% /data/docker-data/containers/6c626b670a9f9f6fe05f65a29c3f4ea223814dc39ca5416547a1e405f64c715c/mounts/shm
shm tmpfs 65536 0 65536 0% /data/docker-data/containers/2ca280f90cab45f8249a7c8b0959b7cf4f62da5ccf29c3f41148df4fe92362f2/mounts/shm
shm tmpfs 65536 0 65536 0% /data/docker-data/containers/3a6ed95e443e72b2821bc68932e06f6cf18bb7bbf21b71f50bb59b405857e28c/mounts/shm
shm tmpfs 65536 0 65536 0% /data/docker-data/containers/d4c079af0ac5ec2e5faaa476d46baba8971729f44e9090a383ce9b4d2032d69c/mounts/shm
tmpfs tmpfs 13110612 0 13110612 0% /run/user/0
如果我们把 tmpfs Used 列数字加起来,会发现和 free 中 shared 基本相等(因为这个数据是动态一直在变化的)。那么什么是 tmpfs 呢?
tmpfs 是一个完全存在于内存里的文件系统,和其他内存数据一样,一切都是临时数据,重启机器后会丢失。tmpfs 的挂载和其他磁盘挂载类似,也可以在 /etc/fstab 内配置。
扇区sector
硬盘的读写以扇区为基本单位。磁盘上的每个磁道被等分为若干个弧段,这些弧段称之为扇区。硬盘的物理读写以扇区为基本单位。通常情况下每个扇区的大小是 512 字节。linux 下可以使用 fdisk -l 了解扇区大小:
$ sudo /sbin/fdisk -l
Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x7d9f5643
其中 Sector size,就是扇区大小,本例中为 512 bytes。
扇区是磁盘物理层面的概念,操作系统是不直接与扇区交互的,而是与多个连续扇区组成的磁盘块交互。由于扇区是物理层面的概念,所以无法在系统中进行大小的更改。
2009年后,硬盘厂商开始发布4KB字节扇区的硬盘了,4KB扇区硬盘已经在消费级市场广泛应用。但是同一块硬盘上的扇区大小一定是一致的。
块/簇 IO Block
文件系统读写数据的最小单位,也叫磁盘簇。window系统叫簇,Linux叫块,是操作系统虚拟出来的逻辑概念,扇区是磁盘最小的物理存储单元,操作系统将相邻的扇区组合在一起,形成一个块,对块进行管理。每个磁盘块可以包括 2、4、8、16、32 或 64 个扇区。磁盘块是操作系统所使用的逻辑概念,而非磁盘的物理概念。磁盘块的大小可以通过命令 stat /boot 来查看:
$ sudo stat /boot
File: /boot
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 801h/2049d Inode: 655361 Links: 3
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-07-06 20:19:45.487160301 +0800
Modify: 2019-07-06 20:19:44.835160301 +0800
Change: 2019-07-06 20:19:44.835160301 +0800
Birth: -
其中 IO Block 就是磁盘块大小,本例中是 4096 Bytes,一般也是 4K。
为了更好地管理磁盘空间和更高效地从硬盘读取数据,操作系统规定一个磁盘块中只能放置一个文件,因此文件所占用的空间,只能是磁盘块的整数倍,那就意味着会出现文件的实际大小,会小于其所占用的磁盘空间的情况。
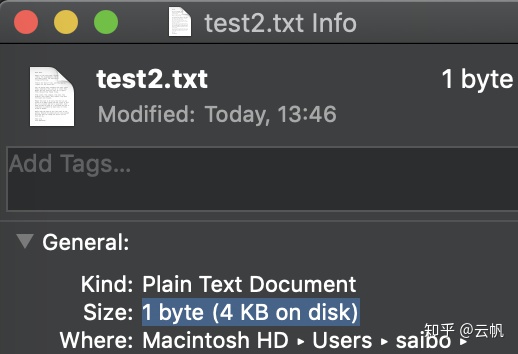
test2.txt是一个只包含一个字母的文本文档。它的理论大小是一个字节,但是由于系统的磁盘块大小是4KB(文件的最小存储大小单位),所以test2.txt占据的磁盘实际空间是4KB
操作系统不能对磁盘扇区直接寻址操写,主要原因是扇区数量庞大,因此才将多个连续扇区组合一起操作。磁盘块的大小是可以通过blockdev命令更改的。
页 page
内存的最小存储单位。页的大小通常为磁盘块大小的 2^n 倍,可以通过命令 getconf PAGE_SIZE 来获取页的大小:
$sudo getconf PAGE_SIZE
4096
本例中为 4096 Bytes,与磁盘块大小一致。
总结两个逻辑单位:
- 页,内存操作的基本单位
- 磁盘块,磁盘操作的基本单位
Page Cache
Page Cache以Page为单位,缓存文件内容。缓存在Page Cache中的文件数据,能够更快的被用户读取。同时对于带buffer的写入操作,数据在写入到Page Cache中即可立即返回,而不需等待数据被实际持久化到磁盘,进而提高了上层应用读写文件的整体性能。
Buffer Cache
磁盘的最小数据单位为sector,每次读写磁盘都是以sector为单位对磁盘进行操作。
sector大小跟具体的磁盘类型有关,有的为512Byte, 有的为4K Bytes。无论用户是希望读取1个byte,还是10个byte,最终访问磁盘时,都必须以sector为单位读取,如果裸读磁盘,那意味着数据读取的效率会非常低。
同样,如果用户希望向磁盘某个位置写入(更新)1个byte的数据,他也必须整个刷新一个sector,言下之意,则是在写入这1个byte之前,我们需要先将该1byte所在的磁盘sector数据全部读出来,在内存中,修改对应的这1个byte数据,然后再将整个修改后的sector数据,一口气写入磁盘。
为了降低这类低效访问,尽可能的提升磁盘访问性能,内核会在磁盘sector上构建一层缓存,他以sector的整数倍力度单位(block),缓存部分sector数据在内存中,当有数据读取请求时,他能够直接从内存中将对应数据读出。当有数据写入时,他可以直接再内存中直接更新指定部分的数据,然后再通过异步方式,把更新后的数据写回到对应磁盘的sector中。这层缓存则是块缓存Buffer Cache。
Page cache与Buffer Cache作用
page cache :页缓存,负责缓存逻辑数据。
buffer cache : 块缓存,负责缓存物理数据。
Cache与Buffer是我们容易混淆的内存概念,Cache名为缓存,Buffer名为缓冲。
Cache和Buffer的出现就是为了弥补高速设备和低速设备之间的矛盾而设立的中间层。
Cache会将低速设备中常被访问的数据缓存起来,当高速设备需要再次访问这些数据时,会命中Cache中的数据,以减少对低速设备的访问。
Buffer用于缓和高速设备要把数据回写到低速设备时带来的冲击,当数据量比较大时,Buffer能将数据分割成合适的大小,分批回写到磁盘;当数据量比较小的时候,Buffer能将分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,通过“流量整形”提高系统性能。
读取数据具体流程是:先去读取buffer cache,如果cache空间不够,会通过一定的策略将一些过时或多次未被访问的buffer cache清空。程序在下一次访问磁盘时首先查看是否在buffer cache找到所需块,命中可减少访问磁盘时间。不命中时需重新读入buffer cache。
Page cache和Buffer cache的区别
磁盘的操作有逻辑级(文件系统)和物理级(磁盘块),这两种Cache就是分别缓存逻辑和物理级数据的。
假设我们通过文件系统操作文件,那么文件将被缓存到Page Cache,如果需要刷新文件的时候,Page Cache将交给Buffer Cache去完成,因为Buffer Cache就是缓存磁盘块的。
也就是说,直接去操作文件,那就是Page Cache区缓存,用dd等命令直接操作磁盘块,就是Buffer Cache缓存的东西。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
Buffer(Buffer Cache)以块形式缓冲了块设备的操作,定时或手动的同步到硬盘,它是为了缓冲写操作然后一次性将很多改动写入硬盘,避免频繁写硬盘,提高写入效率。
Cache(Page Cache)以页面形式缓存了文件系统的文件,给需要使用的程序读取,它是为了给读操作提供缓冲,避免频繁读硬盘,提高读取效率。
图解Page Cache与Buffer Cache
程序读取的文件数据保留在Page Cache(页面缓存)中,以便将来读取时重用。如第一次使用find、grep命令时速度比较慢,再次执行就非常快。
当Page Cache中的数据需要刷新时,Page Cache中的数据会交给Buffer Cache,而Buffer Cache中的数据会定时刷新到磁盘中,也可通过sync命令将缓冲区里的数据写入磁盘。如果突然断电,Buffer Cache没来得及写入到磁盘中,那么就会发生数据丢失。
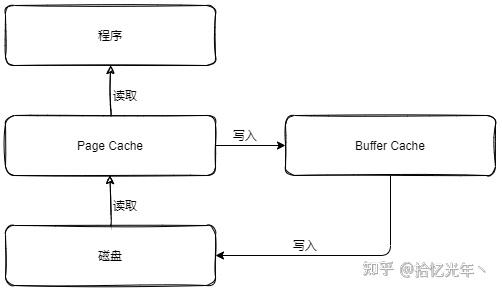
在Linux 2.4以前page cache和buffer cache是两个独立的缓存,Linux 2.4开始buffer cache不再是一个独立的缓存,如下图所示的那样,它被包含在page cache中,通过page cache来实现。
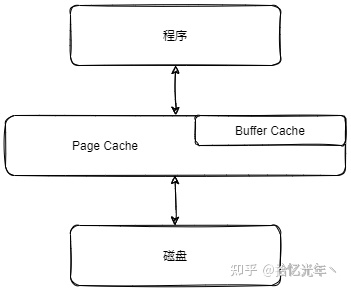
Page Cache、Buffer Cache两者融合
介于上述Page Cache、Buffer Cache分离设计的弊端,Linux-2.4版本中对Page Cache、Buffer Cache的实现进行了融合,融合后的Buffer Cache不再以独立的形式存在,Buffer Cache的内容,直接存在于Page Cache中,同时,保留了对Buffer Cache的描述符单元:buffer_head。
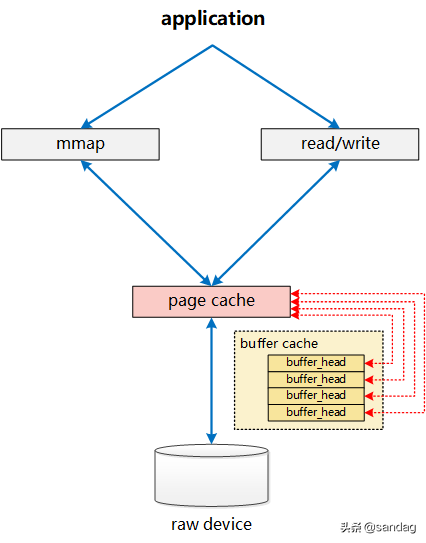
两者的关系已经相互融合如下图所示:
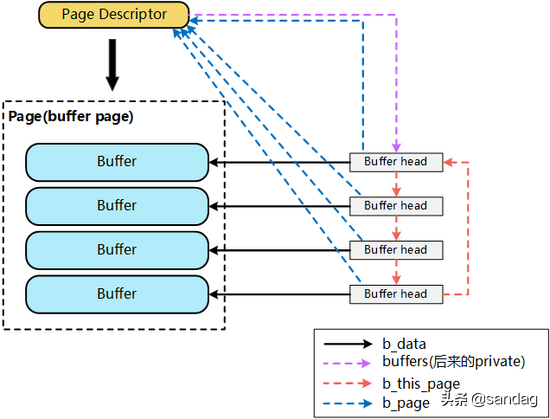
一个文件的PageCache(page),通过 buffers 字段能够非常快捷的确定该page对应的buffer_head信息,进而明确该page对应的device, block等信息。
总结
pageCache缓冲了读数据操作,如果要写入数据,pageCache会将数据传递给bufferCache,通过bufferCache缓冲写数据操作。
参考:
Linux系统中的Page cache和Buffer cache
Linux内核Page Cache和Buffer Cache关系及演化历史
[转帖]Linux Page cache和Buffer cache的更多相关文章
- linux page cache和buffer cache
主要区别是,buffer cache缓存元信息,page cache缓存文件数据 buffer 与 cache 是作为磁盘文件缓存(磁盘高速缓存disk cache)来使用,主要目的提高文件系统系性能 ...
- Linux系统中的Page cache和Buffer cache
Linux系统中的Page cache和Buffer cache Linux中有两个很容易混淆的概念,pagecache和buffercache,首先简单将一些Linux系统下内存的分布,使用free ...
- linux Page cache和buffer cache正解
Page cache和buffer cache一直以来是两个比较容易混淆的概念,在网上也有很多人在争辩和猜想这两个cache到底有什么区别,讨论到最后也一直没有一个统一和正确的结论,在我工作的这一段时 ...
- Page cache和Buffer cache[转1]
http://www.cnblogs.com/mydomain/archive/2013/02/24/2924707.html Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的 ...
- 【转】Linux 查看内存(free buffer cache)
转自:http://elf8848.iteye.com/blog/1995638 Linux下如何查内存信息,如内存总量.已使用量.可使用量.经常使用Windows操作系统的朋友,已经习惯了如果空闲的 ...
- page cache和buffer cache
因为要优化I/O性能,所以要理解一下这两个概念,这两个cache着实让我迷糊了好久,通过查资料大概明白了两者的区别,试着说下. page cache:文件系统层级的缓存,从磁盘里读取的内容是存储到这里 ...
- linux内存 free命令 buffer cache作用
free命令用于查看linux内存使用情况 #free shared:用于进程之间相互共享数据. Used:已使用内存. total:内存总量. free:未使用的内存. available:开启一个 ...
- 【Linux】清理缓存buffer/cache
运行sync将dirty的内容写回硬盘 sync 通过修改proc系统的drop_caches清理free的cache echo 3 > /proc/sys/vm/drop_caches ech ...
- page cache和buffer cache 图解
http://www.cnblogs.com/yrpen/p/3777963.html http://www.cnblogs.com/hustcat/archive/2011/10/27/222699 ...
- linux page buffer cache深入理解
Linux上free命令的输出. 下面是free的运行结果,一共有4行.为了方便说明,我加上了列号.这样可以把free的输出看成一个二维数组FO(Free Output).例如: FO[2][1] = ...
随机推荐
- LeetCode DP篇(62、63、322、887)
62. 不同路径 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为"Start" ). 机器人每次只能向下或者向右移动一步.机器人试图达到网格的右下角(在下图中 ...
- DBA:这有一份对接NBU备份故障排除指南,请查收!
摘要:当前DWS支持NBU介质备份恢复,本文介绍DWS对接NBU备份故障排除方法. 本文分享自华为云社区<DWS对接NBU备份故障排除指南>,作者: 唐伯虎点蚊香. NetBackup是V ...
- 在springboot中,如何读取配置文件中的属性
摘要:在比较大型的项目的开发中,比较经常修改的属性我们一般都是不会在代码里面写死的,而是将其定义在配置文件中,之后如果修改的话,我们可以直接去配置文件中修改,那么在springboot的项目中,我们应 ...
- Solon Aop 特色开发(6)新鲜货提取器,提取Bean的函数进行定制开发
Solon,更小.更快.更自由!本系列专门介绍Solon Aop方面的特色: <Solon Aop 特色开发(1)注入或手动获取配置> <Solon Aop 特色开发(2)注入或手动 ...
- flask 上传文件,视图
记得有template ''' 导入flask类.该类的实例将会成为我们的wsgi应用 __name__是一个适用于大多数情况的快捷方式,有了这个参数,flask才能知道在那里找到模板和静态文件等东西 ...
- C++17 更通用的 union:variant
References 现代C++学习--实现多类型存储std::variant 如何优雅的使用 std::variant 与 std::optional std::variant 是 C++17 中, ...
- Codeforces Round #690 (Div. 3) (简单题解记录)
Codeforces Round #690 (Div. 3) 1462A. Favorite Sequence 简单看懂题即可,左边输出一个然后右边输出一个. void solve() { int n ...
- RabbitMQ的ack机制
1.什么是消息确认ACK. 答:如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失.为了确保数据不会丢失,RabbitMQ支持消 ...
- 图扑 HT for Web 风格属性手册教程
图扑软件明星产品 HT for Web 是一套纯国产化独立自主研发的 2D 和 3D 图形界面可视化引擎.HT for Web(以下简称 HT)图元的样式由其 Style 属性控制,并且不同类型图元的 ...
- 大数据(4)---HDFS工作机制简述
一.name node管理元数据 元数据:hdfs的目录结构以及文件文件的块信息(块副本数量,存放位置等). Namenode把元数据存在内存中,以方便改动,同时也会在某个时间点上面将其写到磁盘上(f ...